Le calcul parallèle est un type de calcul dans lequel de nombreux calculs ou processus sont exécutés simultanément. Les problèmes complexes peuvent souvent être divisés en problèmes plus simples, qui peuvent ensuite être résolus simultanément. Il existe plusieurs formes de calcul parallèle : le parallélisme au niveau des bits , au niveau des instructions , au niveau des données et au niveau des tâches . Le parallélisme est utilisé depuis longtemps dans le calcul haute performance , mais il suscite un intérêt croissant en raison des contraintes physiques qui empêchent l’augmentation de la fréquence . La consommation d’énergie (et par conséquent la production de chaleur) des ordinateurs étant devenue une préoccupation majeure ces dernières années, le calcul parallèle s’est imposé comme le paradigme dominant en architecture informatique , principalement sous la forme de processeurs multicœurs .
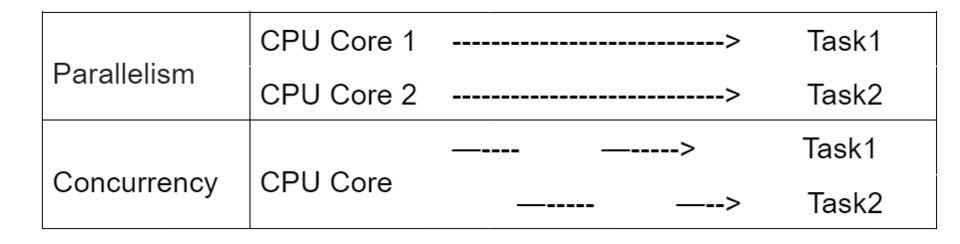
En informatique , le parallélisme et la concurrence sont deux notions distinctes : un programme parallèle utilise plusieurs cœurs de processeur , chaque cœur exécutant une tâche indépendamment. La concurrence, quant à elle, permet à un programme de gérer plusieurs tâches sur un seul cœur ; le cœur alterne entre les tâches (ou threads ) sans nécessairement les terminer une à une. Un programme peut présenter les deux caractéristiques de parallélisme et de concurrence, aucune, ou une combinaison de ces deux caractéristiques.
Les ordinateurs parallèles peuvent être classés selon le niveau de parallélisme pris en charge par le matériel : les ordinateurs multicœurs et multiprocesseurs intègrent plusieurs unités de traitement au sein d’une même machine, tandis que les clusters , les MPP et les grilles de calcul utilisent plusieurs ordinateurs pour exécuter une même tâche. Des architectures d’ordinateurs parallèles spécialisées sont parfois utilisées conjointement avec des processeurs traditionnels afin d’accélérer des tâches spécifiques.
Dans certains cas, le parallélisme est transparent pour le programmeur, comme dans le cas du parallélisme au niveau du bit ou des instructions. Cependant, les algorithmes explicitement parallèles , en particulier ceux qui exploitent la concurrence, sont plus difficiles à écrire que les algorithmes séquentiels , car la concurrence introduit plusieurs nouvelles catégories de bogues logiciels potentiels , dont les conditions de concurrence sont les plus fréquentes. La communication et la synchronisation entre les différentes sous-tâches constituent généralement l'un des principaux obstacles à l'obtention de performances optimales pour les programmes parallèles.
La loi d'Amdahl donne une limite supérieure théorique à l' accélération d'un programme unique grâce à la parallélisation ; elle stipule que cette accélération est limitée par la fraction de temps pendant laquelle la parallélisation peut être utilisée.
les logiciels informatiques sont conçus pour le calcul séquentiel . Pour résoudre un problème, un algorithme est construit et implémenté sous forme d'une séquence d'instructions. Ces instructions sont exécutées sur l' unité centrale de traitement d'un ordinateur. Une seule instruction peut être exécutée à la fois ; une fois cette instruction terminée, la suivante est exécutée.Le calcul parallèle, quant à lui, utilise simultanément plusieurs unités de traitement pour résoudre un problème. Pour ce faire, le problème est décomposé en parties indépendantes, permettant à chaque unité de traitement d'exécuter sa partie de l'algorithme en parallèle avec les autres. Ces unités de traitement peuvent être diverses et inclure des ressources telles qu'un ordinateur unique doté de plusieurs processeurs, plusieurs ordinateurs en réseau, du matériel spécialisé, ou toute combinaison de ces éléments. Historiquement, le calcul parallèle a été utilisé pour le calcul scientifique et la simulation de problèmes scientifiques, notamment dans les sciences naturelles et de l'ingénieur , comme la météorologie . Ceci a conduit à la conception de matériels et de logiciels parallèles, ainsi qu'au calcul haute performance .
L'augmentation de la fréquence d'horloge a été le principal facteur d'amélioration des performances informatiques du milieu des années 1980 à 2004. Le temps d'exécution d'un programme est égal au nombre d'instructions multiplié par le temps moyen d'exécution d'une instruction. Toutes choses égales par ailleurs, l'augmentation de la fréquence d'horloge diminue le temps moyen d'exécution d'une instruction. Une augmentation de la fréquence réduit donc le temps d'exécution de tous les programmes gourmands en calcul . Cependant, la consommation électrique P d'une puce est donnée par l'équation P = C × V² × F , où C est la capacité commutée par cycle d'horloge (proportionnelle au nombre de transistors dont les entrées changent), V est la tension et F est la fréquence du processeur (cycles par seconde). L'augmentation de la fréquence accroît la consommation électrique du processeur. Cette augmentation de la consommation a finalement conduit Intel , le 8 mai 2004, à abandonner ses processeurs Tejas et Jayhawk , ce qui est généralement considéré comme la fin de l'augmentation de la fréquence d'horloge en tant que paradigme dominant de l'architecture informatique.
Pour résoudre les problèmes de consommation d'énergie et de surchauffe, les principaux fabricants de processeurs (CPU) ont commencé à produire des processeurs multicœurs à faible consommation. Le cœur est l'unité de calcul du processeur ; dans les processeurs multicœurs, chaque cœur est indépendant et peut accéder simultanément à la même mémoire. Les processeurs multicœurs ont introduit le calcul parallèle dans les ordinateurs de bureau . La parallélisation des programmes séquentiels est ainsi devenue une tâche de programmation courante. En 2012, les processeurs quadricœurs sont devenus la norme pour les ordinateurs de bureau , tandis que les serveurs disposaient de processeurs à plus de 10 cœurs. La loi de Moore prévoyait que le nombre de cœurs par processeur doublerait tous les 18 à 24 mois . En 2023, certains processeurs comptaient plus de cent cœurs. Certaines architectures combinent cœurs performants et cœurs à faible consommation (comme l'architecture big.LITTLE d'ARM ) en raison de contraintes thermiques et de conception.système d'exploitation peut garantir l'exécution en parallèle de différentes tâches et programmes utilisateur sur les cœurs disponibles. Cependant, pour qu'un logiciel séquentiel tire pleinement parti de l'architecture multicœur, le programmeur doit restructurer et paralléliser son code. L'accélération de l'exécution des applications ne sera plus obtenue par une simple augmentation de la fréquence ; les programmeurs devront désormais paralléliser leur code pour exploiter la puissance de calcul croissante des architectures multicœurs.
Lois pertinentes
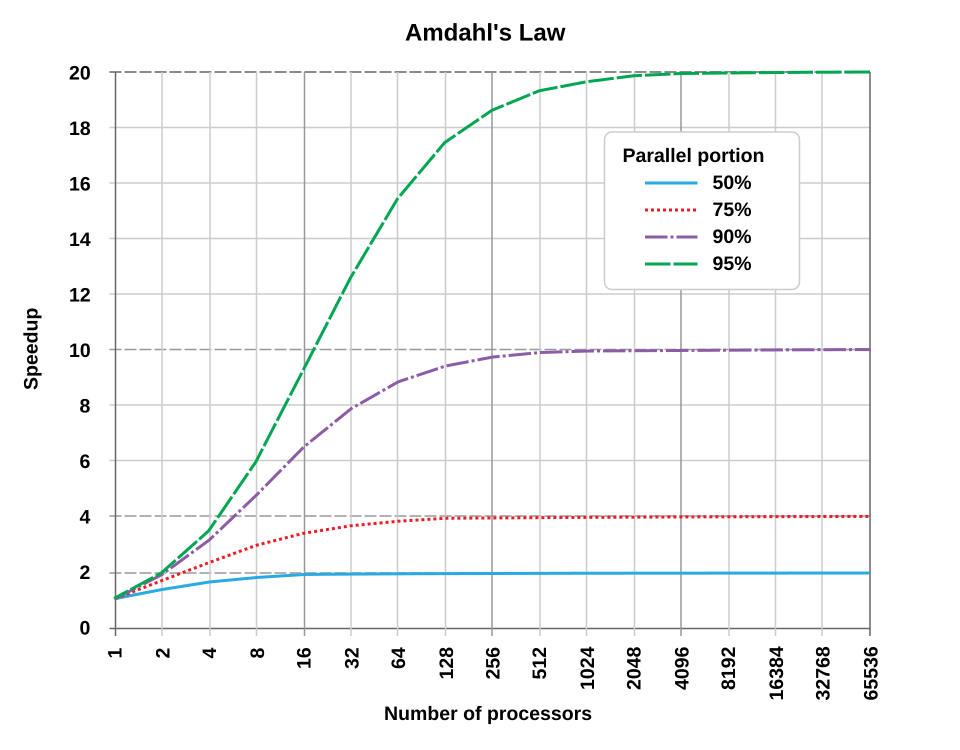
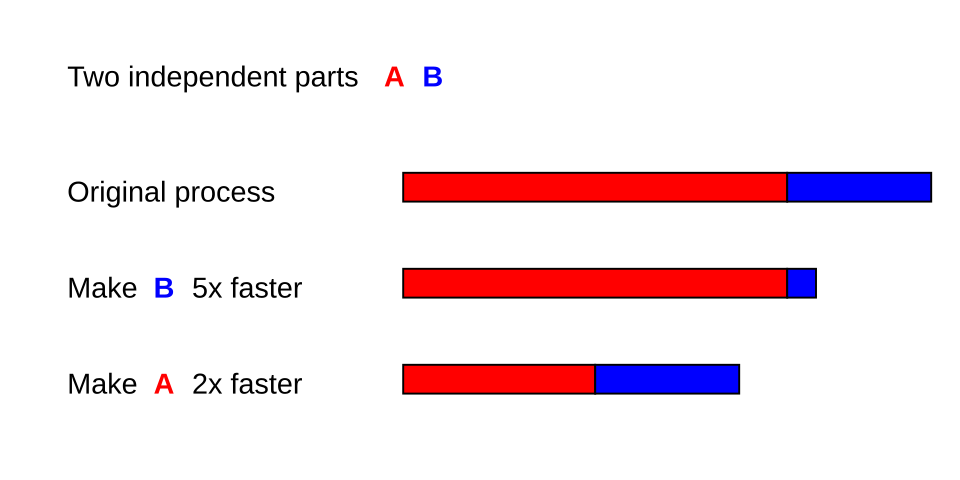
Le gain de vitesse maximal potentiel d'un système global peut être calculé par la loi d'Amdahl . Cette loi indique qu'une amélioration optimale des performances est obtenue en équilibrant les améliorations apportées aux composantes parallélisables et non parallélisables d'une tâche. De plus, elle révèle que l'augmentation du nombre de processeurs engendre des rendements décroissants, les gains de vitesse devenant négligeables au-delà d'un certain seuil.
La loi d'Amdahl présente des limites, notamment des hypothèses de charge de travail fixe, la négligence des surcharges de communication et de synchronisation interprocessus , une focalisation principalement sur l'aspect calculatoire et l'ignorance de facteurs extrinsèques tels que la persistance des données, les opérations d'E/S et les surcharges d'accès à la mémoire.
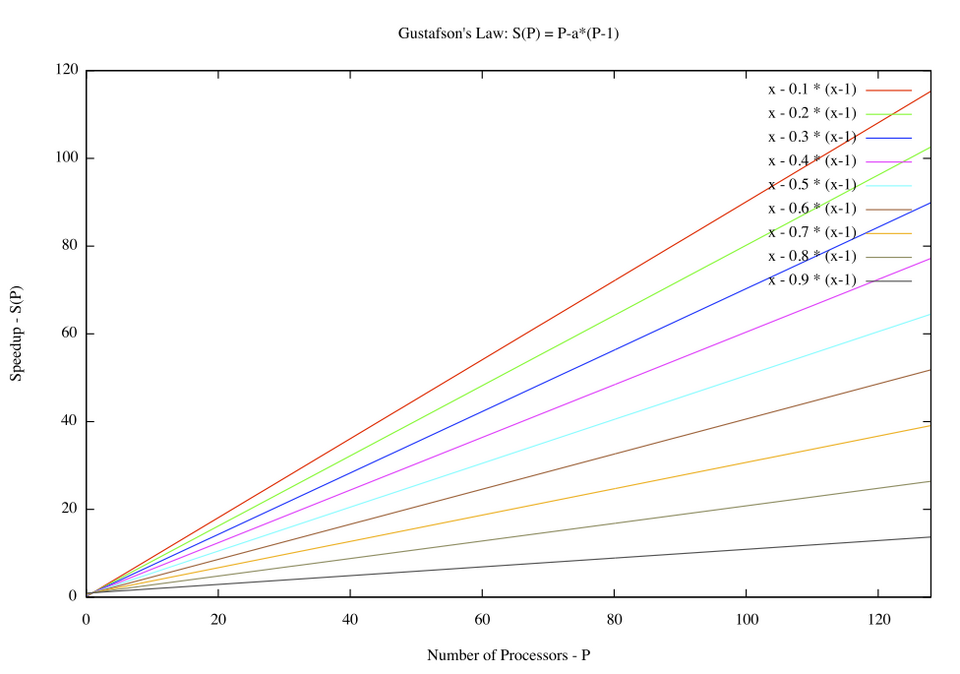
La loi de Gustafson et la loi d'évolutivité universelle permettent une évaluation plus réaliste des performances parallèles.
Dépendances
La compréhension des dépendances entre les données est fondamentale pour la mise en œuvre d'algorithmes parallèles . Aucun programme ne peut s'exécuter plus rapidement que la plus longue chaîne de calculs dépendants (appelée chemin critique ), car les calculs qui dépendent des calculs précédents dans la chaîne doivent être exécutés séquentiellement. Cependant, la plupart des algorithmes ne se limitent pas à une longue chaîne de calculs dépendants ; il existe généralement des possibilités d'exécuter des calculs indépendants en parallèle.
Soient P <sub>i</sub> et P<sub> j </sub> deux segments de programme. Les conditions de Bernstein décrivent quand ces deux segments sont indépendants et peuvent être exécutés en parallèle. Pour P <sub>i</sub> , soit I<sub> i </sub> l'ensemble des variables d'entrée et O<sub> i</sub> les variables de sortie, et de même pour P <sub> j </sub> . P<sub> i </sub> et P <sub> j</sub> sont indépendants s'ils satisfont aux conditions suivantes :
La violation de la première condition introduit une dépendance de flux : le premier segment produit un résultat utilisé par le second. La deuxième condition représente une anti-dépendance : le second segment produit une variable nécessaire au premier. La troisième et dernière condition représente une dépendance de sortie : lorsque deux segments écrivent au même emplacement, le résultat provient du dernier segment exécuté logiquement.
Considérons les fonctions suivantes, qui illustrent plusieurs types de dépendances :
1 : fonction Dep(a, b) 2: c := a * b 3 : d := 3 * c 4 : fonction de fin
Dans cet exemple, l'instruction 3 ne peut pas être exécutée avant (ou même en parallèle avec) l'instruction 2, car l'instruction 3 utilise un résultat de l'instruction 2. Elle viole la condition 1 et introduit ainsi une dépendance de flux.
1 : fonction NoDep(a, b) 2: c := a * b 3 : d := 3 * b 4 : e := a + b 5 : fonction de fin
Dans cet exemple, il n'y a aucune dépendance entre les instructions, elles peuvent donc toutes être exécutées en parallèle.
Les conditions de Bernstein interdisent le partage de mémoire entre différents processus. Il est donc nécessaire d'imposer un ordre d'accès, par exemple à l'aide de sémaphores , de barrières ou d'une autre méthode de synchronisation .
Conditions de concurrence, exclusion mutuelle, synchronisation et ralentissement parallèle
Dans un programme parallèle, les sous-tâches sont souvent appelées threads . Certaines architectures d'ordinateurs parallèles utilisent des versions plus petites et légères des threads, appelées fibres , tandis que d'autres utilisent des versions plus grandes, appelées processus . Cependant, le terme « thread » est généralement accepté comme terme générique pour désigner les sous-tâches. Les threads ont souvent besoin d'un accès synchronisé à un objet ou à une autre ressource , par exemple lorsqu'ils doivent mettre à jour une variable partagée. Sans synchronisation, les instructions entre les deux threads peuvent s'exécuter dans n'importe quel ordre. Par exemple, considérons le programme suivant :
| Fil A | Fil B |
|---|---|
| 1A : Lire la variable V | 1B : Lire la variable V |
| 2A : Ajouter 1 à la variable V | 2B : Ajouter 1 à la variable V |
| 3A : Réécrire dans la variable V | 3B : Réécrire dans la variable V |
Si l'instruction 1B est exécutée entre 1A et 3A, ou si l'instruction 1A est exécutée entre 1B et 3B, le programme produira des données incorrectes. On parle alors de condition de concurrence . Le programmeur doit utiliser un verrou pour garantir l'exclusion mutuelle . Un verrou est une construction du langage de programmation qui permet à un thread de prendre le contrôle d'une variable et d'empêcher les autres threads de la lire ou de l'écrire, jusqu'à ce que cette variable soit déverrouillée. Le thread qui détient le verrou est libre d'exécuter sa section critique (la section du programme qui nécessite un accès exclusif à une variable) et de déverrouiller les données une fois l'exécution terminée. Par conséquent, pour garantir une exécution correcte du programme, le programme ci-dessus peut être réécrit en utilisant des verrous :
| Fil A | Fil B |
|---|---|
| 1A : Verrouiller la variable V | 1B : Verrouiller la variable V |
| 2A : Lire la variable V | 2B : Lire la variable V |
| 3A : Ajouter 1 à la variable V | 3B : Ajouter 1 à la variable V |
| 4A : Réécrire dans la variable V | 4B : Réécrire dans la variable V |
| 5A : Déverrouiller la variable V | 5B : Déverrouiller la variable V |
Un thread parviendra à verrouiller la variable V, tandis que l'autre sera bloqué et ne pourra pas poursuivre son exécution tant que V n'aura pas été déverrouillée. Ceci garantit la bonne exécution du programme. Les verrous peuvent être nécessaires pour assurer une exécution correcte lorsque les threads doivent sérialiser l'accès aux ressources, mais leur utilisation peut considérablement ralentir un programme et affecter sa fiabilité .
Le verrouillage de plusieurs variables à l'aide de verrous non atomiques introduit un risque d' interblocage . Un verrou atomique verrouille plusieurs variables simultanément. S'il ne peut pas toutes les verrouiller, il n'en verrouille aucune. Si deux threads doivent verrouiller les mêmes deux variables à l'aide de verrous non atomiques, il est possible qu'un thread verrouille l'une des variables et que l'autre thread verrouille la seconde. Dans ce cas, aucun des deux threads ne peut terminer son exécution, et un interblocage se produit.
De nombreux programmes parallèles exigent que leurs sous-tâches s'exécutent de manière synchrone . Cela nécessite l'utilisation d'une barrière . Les barrières sont généralement implémentées à l'aide d'un verrou ou d'un sémaphore . Une catégorie d'algorithmes, dits sans verrou et sans attente , évite totalement l'utilisation de verrous et de barrières. Cependant, cette approche est généralement difficile à mettre en œuvre et requiert des structures de données correctement conçues.
La parallélisation n'entraîne pas systématiquement un gain de vitesse. En général, lorsqu'une tâche est divisée en un nombre croissant de threads, ces derniers consacrent une part toujours plus importante de leur temps à communiquer entre eux ou à s'attendre mutuellement pour accéder aux ressources. Dès lors que la surcharge liée à la contention des ressources ou à la communication devient prépondérante par rapport au temps consacré aux autres calculs, une parallélisation supplémentaire (c'est-à-dire la répartition de la charge de travail sur un nombre encore plus important de threads) augmente, au lieu de diminuer, le temps nécessaire à l'exécution. Ce problème, connu sous le nom de ralentissement parallèle , peut être amélioré dans certains cas par l'analyse et la refonte du logiciel.
Parallélisme fin, grossier et embarrassant
Les applications sont souvent classées selon la fréquence à laquelle leurs sous-tâches doivent se synchroniser ou communiquer entre elles. Une application présente un parallélisme fin si ses sous-tâches doivent communiquer plusieurs fois par seconde ; un parallélisme grossier si elles ne communiquent pas plusieurs fois par seconde ; et un parallélisme « embarrassant » si elles communiquent rarement, voire jamais. Les applications à parallélisme « embarrassant » sont considérées comme les plus faciles à paralléliser.
La taxonomie de Flynn
Selon David A. Patterson et John L. Hennessy , « Certaines machines sont des hybrides de ces catégories, bien sûr, mais ce modèle classique a survécu parce qu’il est simple, facile à comprendre et qu’il donne une bonne première approximation. C’est aussi — peut-être en raison de sa compréhensibilité — le schéma le plus largement utilisé. »
Inconvénients
En pratique, le calcul parallèle peut engendrer des surcoûts importants, principalement dus à la fusion des données provenant de plusieurs processus. Plus précisément, la communication et la synchronisation interprocessus peuvent entraîner des surcoûts considérablement plus élevés — souvent de deux ordres de grandeur, voire plus — que pour le traitement des mêmes données sur un seul thread. Par conséquent, l'amélioration globale doit être évaluée avec soin.
Granularité
Parallélisme au niveau du bit
Depuis l'avènement de la technologie de fabrication de puces informatiques à très grande échelle (VLSI) dans les années 1970 jusqu'en 1986 environ, l'accélération de l'architecture informatique reposait sur le doublement de la taille des mots , c'est-à-dire la quantité d'informations que le processeur peut manipuler par cycle. Augmenter la taille des mots réduit le nombre d'instructions que le processeur doit exécuter pour effectuer une opération sur des variables dont la taille est supérieure à la longueur d'un mot. Par exemple, lorsqu'un processeur 8 bits doit additionner deux entiers de 16 bits , il doit d'abord additionner les 8 bits de poids faible de chaque entier à l'aide de l'instruction d'addition standard, puis additionner les 8 bits de poids fort à l'aide d'une instruction d'addition avec retenue et du bit de retenue de l'addition des bits de poids faible. Ainsi, un processeur 8 bits nécessite deux instructions pour effectuer une seule opération, tandis qu'un processeur 16 bits pourrait l'effectuer en une seule instruction.
Historiquement, les microprocesseurs 4 bits ont été successivement remplacés par des microprocesseurs 8 bits, puis 16 bits, et enfin 32 bits. Cette évolution s'est globalement interrompue avec l'introduction des processeurs 32 bits, qui sont devenus la norme en informatique générale pendant deux décennies. Ce n'est qu'au début des années 2000, avec l'avènement des architectures x86-64 , que les processeurs 64 bits se sont généralisés.
Parallélisme au niveau des instructions
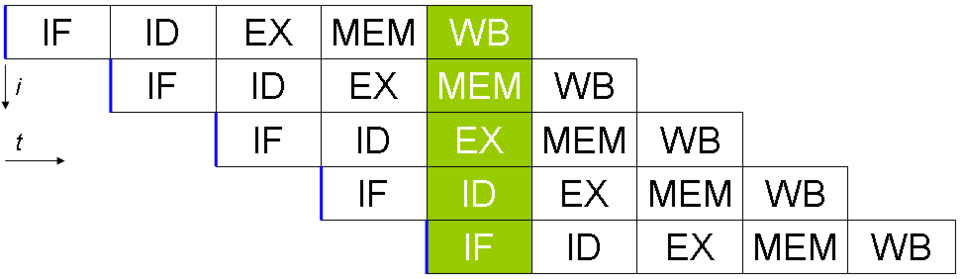
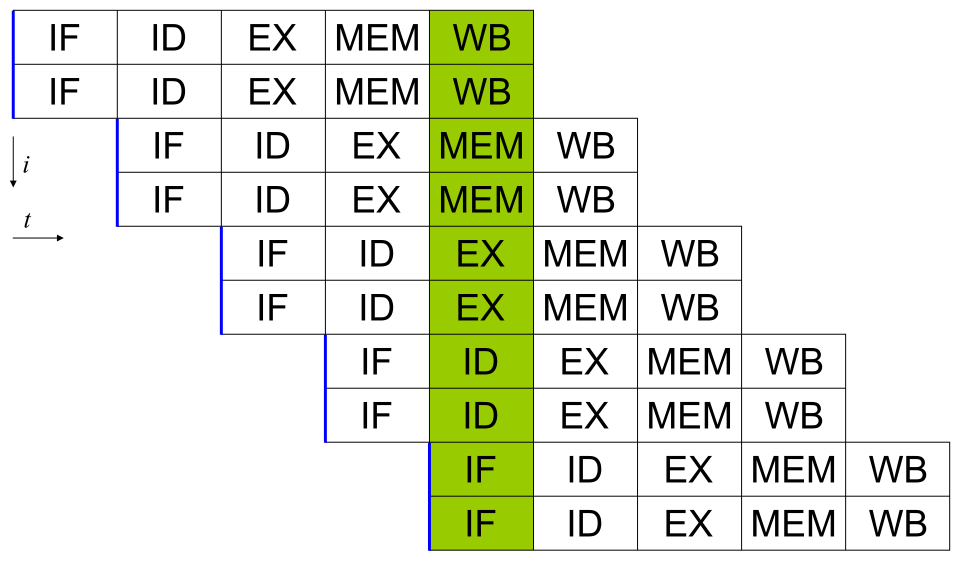
La plupart des processeurs modernes possèdent plusieurs unités d'exécution . Ils combinent généralement cette caractéristique avec le pipeline et peuvent ainsi exécuter plusieurs instructions par cycle d'horloge ( 1"}},"i":0}}] IPC > 1 ). Ces processeurs sont appelés processeurs superscalaires . Les processeurs superscalaires se distinguent des processeurs multicœurs par le fait que leurs unités d'exécution ne constituent pas des processeurs complets (c'est-à-dire des unités de traitement). Les instructions ne peuvent être regroupées que s'il n'existe aucune dépendance de données entre elles. Le scoreboarding et l' algorithme de Tomasulo (qui est similaire au scoreboarding mais utilise le renommage de registres ) sont deux des techniques les plus courantes pour implémenter l'exécution hors séquence et le parallélisme au niveau des instructions.
Parallélisme des tâches
Matériel
Mémoire et communication
Dans un ordinateur parallèle, la mémoire principale est soit de la mémoire partagée (commune entre tous les éléments de traitement d'un même espace d'adressage ), soit de la mémoire distribuée (chaque élément de traitement disposant de son propre espace d'adressage local). La mémoire distribuée désigne la distribution logique de la mémoire, mais implique souvent également une distribution physique. La mémoire partagée distribuée et la virtualisation de la mémoire combinent ces deux approches : chaque élément de traitement possède sa propre mémoire locale et peut accéder à la mémoire des processeurs distants. L'accès à la mémoire locale est généralement plus rapide que l'accès à la mémoire distante. Sur les supercalculateurs , l'espace de mémoire partagée distribuée peut être implémenté à l'aide d'un modèle de programmation tel que PGAS . Ce modèle permet aux processus d'un nœud de calcul d'accéder de manière transparente à la mémoire distante d'un autre nœud. Tous les nœuds de calcul sont également connectés à un système de mémoire partagée externe via une interconnexion à haut débit, comme Infiniband . Ce système de mémoire partagée externe est appelé tampon de rafale et est généralement constitué de matrices de mémoire non volatile physiquement distribuées sur plusieurs nœuds d'E/S.
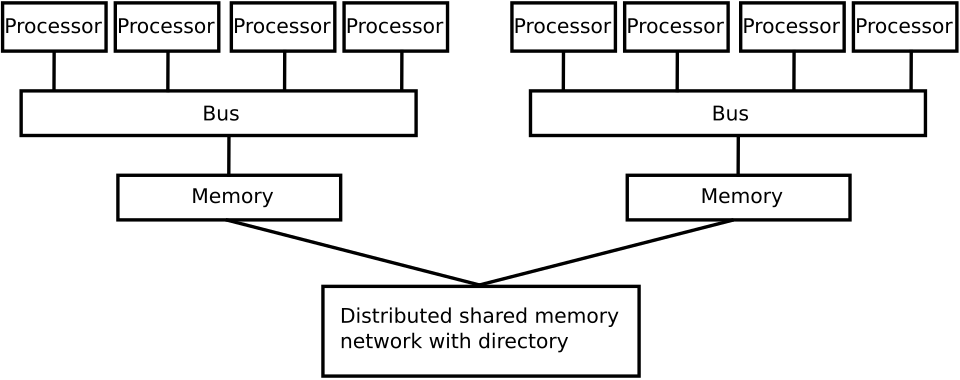
Les architectures informatiques dans lesquelles chaque élément de la mémoire principale est accessible avec une latence et une bande passante égales sont appelées systèmes à accès mémoire uniforme (UMA). Généralement, cela n'est possible que grâce à un système à mémoire partagée , où la mémoire n'est pas physiquement distribuée. Un système ne possédant pas cette propriété est appelé architecture à accès mémoire non uniforme (NUMA). Les systèmes à mémoire distribuée présentent un accès mémoire non uniforme.
Les systèmes informatiques (à l'exception des LPU de Groq ) utilisent des caches : des mémoires de petite taille et rapides, situées à proximité du processeur, qui stockent des copies temporaires des valeurs en mémoire (à proximité physique et logique). Les systèmes informatiques parallèles rencontrent des difficultés avec les caches susceptibles de stocker une même valeur à plusieurs emplacements, ce qui peut entraîner une exécution incorrecte du programme. Ces ordinateurs nécessitent un système de cohérence de cache , qui assure le suivi des valeurs mises en cache et les purge de manière stratégique, garantissant ainsi une exécution correcte du programme. L'écoute du bus est l'une des méthodes les plus courantes pour suivre les valeurs accédées (et donc à purger). Concevoir des systèmes de cohérence de cache performants et de grande taille représente un défi majeur en architecture informatique. C'est pourquoi les architectures à mémoire partagée ne sont pas évolutives, contrairement aux systèmes à mémoire distribuée.
La communication entre processeurs et entre processeurs et mémoire peut être implémentée matériellement de plusieurs manières, notamment via une mémoire partagée (multiportée ou multiplexée ), un commutateur crossbar , un bus partagé ou un réseau d'interconnexion d'une myriade de topologies , y compris en étoile , en anneau , en arbre , en hypercube , en hypercube épais (un hypercube avec plus d'un processeur à un nœud) ou en maillage n-dimensionnel .
Les ordinateurs parallèles reposant sur des réseaux interconnectés nécessitent un système de routage pour permettre l'échange de messages entre des nœuds non directement connectés. Dans les grandes machines multiprocesseurs, le support de communication entre les processeurs est généralement hiérarchique.
Classes d'ordinateurs parallèles
Les ordinateurs parallèles peuvent être classés selon le niveau de parallélisme pris en charge par le matériel. Cette classification est globalement analogue à la distance entre les nœuds de calcul élémentaires. Ces classifications ne sont pas mutuellement exclusives ; par exemple, les grappes de multiprocesseurs symétriques sont relativement courantes.
Calcul multicœur
Le multithreading simultané (dont l'Hyper-Threading d'Intel est la plus connue) constituait une forme primitive de pseudo-multicœur. Un processeur capable de multithreading concurrent intègre plusieurs unités d'exécution au sein d'une même unité de traitement (il possède donc une architecture superscalaire) et peut exécuter plusieurs instructions par cycle d'horloge depuis plusieurs threads. Le multithreading temporel, quant à lui, utilise une seule unité d'exécution au sein de la même unité de traitement et ne peut exécuter qu'une seule instruction à la fois depuis plusieurs threads.
Multitraitement symétrique
Informatique distribuée
calcul en cluster
Un cluster est un groupe d'ordinateurs faiblement couplés qui fonctionnent en étroite collaboration, au point de pouvoir être considérés, à certains égards, comme un seul ordinateur. Les clusters sont composés de plusieurs machines autonomes connectées par un réseau. Bien que les machines d'un cluster ne soient pas nécessairement symétriques, l'équilibrage de charge est plus complexe dans le cas contraire. Le type de cluster le plus courant est le cluster Beowulf , qui est un cluster implémenté sur plusieurs ordinateurs commerciaux identiques, connectés par un réseau local Ethernet TCP/IP . La technologie Beowulf a été initialement développée par Thomas Sterling et Donald Becker . 87 % des supercalculateurs du Top500 sont des clusters. Les autres sont des processeurs massivement parallèles (MPP), expliqués ci-dessous.
Les systèmes de calcul distribué (décrits ci-dessous) étant capables de traiter aisément des problèmes massivement parallèles, les clusters modernes sont généralement conçus pour résoudre des problèmes plus complexes, c'est-à-dire des problèmes qui exigent un partage plus fréquent des résultats intermédiaires entre les nœuds. Ceci requiert une large bande passante et, surtout, un réseau d'interconnexion à faible latence . De nombreux supercalculateurs, anciens et actuels, utilisent du matériel réseau haute performance personnalisé, spécifiquement conçu pour le calcul distribué, comme le réseau Cray Gemini. En 2014, la plupart des supercalculateurs utilisaient du matériel réseau standard disponible dans le commerce, souvent Myrinet , InfiniBand ou Gigabit Ethernet .
Calcul massivement parallèle
Un processeur massivement parallèle (MPP) est un ordinateur unique doté de nombreux processeurs en réseau. Les MPP partagent de nombreuses caractéristiques avec les clusters, mais ils utilisent des réseaux d'interconnexion spécialisés (alors que les clusters utilisent du matériel standard pour la mise en réseau). Les MPP sont généralement plus volumineux que les clusters, comptant typiquement bien plus de 100 processeurs. Dans un MPP, « chaque processeur possède sa propre mémoire et une copie du système d'exploitation et des applications. Chaque sous-système communique avec les autres via une interconnexion à haut débit. »
Le Blue Gene/L d' IBM , le cinquième supercalculateur le plus rapide au monde selon le classement TOP500 de juin 2009 , est un MPP.
Calcul distribué
La plupart des applications de calcul distribué utilisent un intergiciel (logiciel intermédiaire qui s'intercale entre le système d'exploitation et l'application pour gérer les ressources réseau et standardiser l'interface logicielle). L'intergiciel le plus courant pour le calcul distribué est BOINC ( Berkeley Open Infrastructure for Network Computing ). Les logiciels de calcul distribué utilisent souvent les « cycles disponibles », en effectuant des calculs lorsque l'ordinateur est inactif.
informatique en nuage
Technologie des registres distribués
Ordinateurs parallèles spécialisés
Within parallel computing, there are specialized parallel devices that remain niche areas of interest. While not domain-specific, they tend to be applicable to only a few classes of parallel problems.
Reconfigurable computing with field-programmable gate arrays
Reconfigurable computing is the use of a field-programmable gate array (FPGA) as a co-processor to a general-purpose computer. An FPGA is, in essence, a computer chip that can rewire itself for a given task.
FPGAs can be programmed with hardware description languages such as VHDL or Verilog. Several vendors have created C to HDL languages that attempt to emulate the syntax and semantics of the C programming language, with which most programmers are familiar. The best known C to HDL languages are Mitrion-C, Impulse C, and Handel-C. Specific subsets of SystemC based on C++ can also be used for this purpose.
AMD's decision to open its HyperTransport technology to third-party vendors has become the enabling technology for high-performance reconfigurable computing. According to Michael R. D'Amour, Chief Operating Officer of DRC Computer Corporation, "when we first walked into AMD, they called us 'the socket stealers.' Now they call us their partners."
General-purpose computing on graphics processing units (GPGPU)
General-purpose computing on graphics processing units (GPGPU) is a fairly recent trend in computer engineering research. GPUs are co-processors that have been heavily optimized for computer graphics processing. Computer graphics processing is a field dominated by data parallel operations—particularly linear algebramatrix operations.
À leurs débuts, les programmes GPGPU utilisaient les API graphiques classiques pour leur exécution. Cependant, plusieurs nouveaux langages de programmation et plateformes ont été développés pour effectuer des calculs généraux sur GPU. Nvidia et AMD ont notamment publié des environnements de programmation avec CUDA et Stream SDK , respectivement. Parmi les autres langages de programmation GPU, on peut citer BrookGPU , PeakStream et RapidMind . Nvidia a également lancé des produits dédiés au calcul dans sa gamme Tesla . Le consortium technologique Khronos Group a publié la spécification OpenCL , un framework permettant d'écrire des programmes s'exécutant sur des plateformes composées de CPU et de GPU. AMD , Apple , Intel , Nvidia et d'autres acteurs prennent en charge OpenCL .
circuits intégrés spécifiques à une application
Puisqu'un ASIC est (par définition) spécifique à une application donnée, il peut être entièrement optimisé pour celle-ci. De ce fait, pour une application donnée, un ASIC tend à surpasser un ordinateur à usage général. Cependant, les ASIC sont fabriqués par photolithographie UV . Ce procédé nécessite un jeu de masques, qui peut s'avérer extrêmement coûteux. Un jeu de masques peut coûter plus d'un million de dollars américains . (Plus les transistors nécessaires à la puce sont petits, plus le masque est cher.) Parallèlement, les gains de performance en informatique à usage général au fil du temps (décrits par la loi de Moore ) tendent à annuler ces gains en seulement une ou deux générations de puces . Le coût initial élevé et la tendance à être dépassés par l'informatique à usage général, elle-même soumise à la loi de Moore, ont rendu les ASIC inadaptés à la plupart des applications de calcul parallèle. Néanmoins, certains ont été construits. On peut citer l'exemple de la machine PFLOPS RIKEN MDGRAPE-3 , qui utilise des ASIC personnalisés pour la simulation de dynamique moléculaire .
processeurs vectoriels
Un processeur vectoriel est un processeur ou un système informatique capable d'exécuter la même instruction sur de grands ensembles de données. Les processeurs vectoriels possèdent des opérations de haut niveau qui agissent sur des tableaux linéaires de nombres, ou vecteurs. Un exemple d'opération vectorielle est A = B × C , où A , B et C sont chacun des vecteurs de 64 éléments composés de nombres à virgule flottante 64 bits . Ils sont étroitement liés à la classification SIMD de Flynn.
Les ordinateurs Cray ont acquis une grande renommée dans les années 1970 et 1980 grâce à leur puissance de calcul vectorielle. Cependant, les processeurs vectoriels, qu'ils soient intégrés au processeur ou utilisés comme systèmes informatiques complets, ont globalement disparu. Les jeux d'instructions des processeurs modernes incluent certes certaines instructions de traitement vectoriel, comme avec AltiVec de Freescale Semiconductor et Streaming SIMD Extensions (SSE) d' Intel .
Logiciel
Langages de programmation parallèle
Les efforts de normalisation de la programmation parallèle incluent une norme ouverte appelée OpenHMPP pour la programmation parallèle hybride multicœur. Le modèle de programmation OpenHMPP, basé sur des directives, offre une syntaxe permettant de décharger efficacement les calculs sur des accélérateurs matériels et d'optimiser les transferts de données vers/depuis la mémoire matérielle grâce aux appels de procédure distante .
L'essor des GPU grand public a conduit à la prise en charge des noyaux de calcul , soit dans les API graphiques (appelés shaders de calcul ), soit dans des API dédiées (telles qu'OpenCL ), soit dans d'autres extensions de langage.
Parallélisation automatique
Les langages de programmation parallèle courants restent soit explicitement parallèles , soit (au mieux) partiellement implicites , où le programmeur fournit au compilateur des directives de parallélisation. Il existe quelques langages de programmation parallèle entièrement implicites : SISAL , Parallel Haskell , SequenceL , SystemC (pour FPGA ), Mitrion-C , VHDL et Verilog .
Point de contrôle de l'application
Méthodes algorithmiques
À mesure que les ordinateurs parallèles deviennent plus grands et plus rapides, nous sommes désormais capables de résoudre des problèmes dont le calcul était auparavant trop long. Des domaines aussi variés que la bioinformatique (pour le repliement des protéines et l'analyse des séquences ) et l'économie ont tiré parti du calcul parallèle. Les types de problèmes courants rencontrés dans les applications de calcul parallèle comprennent :
- Algèbre linéaire dense
- Algèbre linéaire creuse
- Les méthodes spectrales (telles que la transformée de Fourier rapide de Cooley-Tukey )
- Problèmes à N corps (tels que la simulation de Barnes-Hut )
- Problèmes de grille structurée (tels que les méthodes de Boltzmann sur réseau )
- Problèmes de maillage non structuré (tels que ceux rencontrés dans l'analyse par éléments finis )
- méthode de Monte Carlo
- Logique combinatoire (telle que les techniques cryptographiques par force brute )
- Parcours de graphes (tels que les algorithmes de tri )
- Programmation dynamique
- Méthodes de séparation et d'évaluation
- Modèles graphiques (tels que la détection de modèles de Markov cachés et la construction de réseaux bayésiens )
- Modèle HBJ , un modèle de passage de messages concis
- Simulation de machine à états finis
- Problèmes d'optimisation (tels que les algorithmes génétiques et le recuit simulé )
- Méthodes particulaires (telles que les méthodes particulaires en cellule et l'hydrodynamique des particules lissées )
- Problèmes de satisfaction de contraintes (CSP)
- Exploration de données et reconnaissance de formes
- Formation en apprentissage automatique et en apprentissage profond
- rendu par lancer de rayons
- Analyse des séries chronologiques
- Analyse de données en continu
Tolérance aux pannes
Histoire
Les origines du véritable parallélisme (MIMD) remontent à Luigi Federico Menabrea et à son Esquisse de la machine analytique inventée par Charles Babbage .
En 1957, la Compagnie des Machines Bull annonça la première architecture informatique spécifiquement conçue pour le parallélisme, le Gamma 60. [ utilisait un modèle fork-join et un « distributeur de programmes » pour répartir et collecter les données entre des unités de traitement indépendantes connectées à une mémoire centrale.
En avril 1958, Stanley Gill (Ferranti) aborda la programmation parallèle et la nécessité de recourir à des instructions conditionnelles et à l'attente. [81] Toujours en 1958, les chercheurs d'IBM, John Cocke et Daniel Slotnick, discutèrent pour la première fois de l'utilisation du parallélisme dans les calculs numériques. En 1962 , la lança le D825, un ordinateur à quatre processeurs pouvant accéder à 16 modules de mémoire via un commutateur matriciel . En 1967, Amdahl et Slotnick présentèrent un débat sur la faisabilité du traitement parallèle lors de la conférence de l'American Federation of Information Processing Societies. C'est au cours de ce débat que fut formulée la loi d'Amdahl, qui définit la limite du gain de vitesse grâce au parallélisme.
En 1969, Honeywell a lancé son premier système Multics , un système multiprocesseur symétrique capable d'exécuter jusqu'à huit processeurs en parallèle. C.mmp , un projet multiprocesseur de l' Université Carnegie Mellon dans les années 1970, figurait parmi les premiers multiprocesseurs dotés d'un nombre significatif de processeurs. Le premier multiprocesseur connecté par bus et équipé de caches d'écoute fut le Synapse N+1 en 1984.
Les ordinateurs parallèles SIMD remontent aux années 1970. L'objectif des premiers ordinateurs SIMD était d'amortir le temps de réponse de l' unité de contrôle du processeur sur plusieurs instructions. En 1964, Slotnick proposa la construction d'un ordinateur massivement parallèle pour le Laboratoire national Lawrence Livermore . Son projet fut financé par l' US Air Force , donnant naissance à ILLIAC IV , le premier projet de calcul parallèle SIMD . La clé de sa conception résidait dans un parallélisme relativement élevé, avec jusqu'à 256 processeurs, permettant à la machine de traiter de vastes ensembles de données, une technique qui sera plus tard connue sous le nom de traitement vectoriel . Cependant, ILLIAC IV est considéré comme le « plus tristement célèbre des supercalculateurs », car le projet ne fut achevé qu'à un quart, après 11 ans de développement et un coût presque quatre fois supérieur aux estimations initiales. Lorsqu'il fut finalement prêt à exécuter sa première véritable application en 1976, il fut surpassé par les supercalculateurs commerciaux existants tels que le Cray-1 .
Le cerveau biologique comme ordinateur massivement parallèle
Au début des années 1970, au Laboratoire d'informatique et d'intelligence artificielle du MIT , Marvin Minsky et Seymour Papert ont commencé à développer la théorie de la Société de l'Esprit , qui conçoit le cerveau biologique comme un ordinateur massivement parallèle . En 1986, Minsky a publié * La Société de l'Esprit* , ouvrage dans lequel il affirme que « l'esprit est formé de nombreux petits agents, chacun dépourvu d'intelligence en soi » . Cette théorie tente d'expliquer comment ce que nous appelons intelligence pourrait être le produit de l'interaction de parties non intelligentes. Minsky indique que la principale source d'inspiration de cette théorie provient de ses travaux visant à créer une machine utilisant un bras robotisé, une caméra vidéo et un ordinateur pour construire avec des blocs de construction pour enfants
Des modèles similaires (qui considèrent également le cerveau biologique comme un ordinateur massivement parallèle, c'est-à-dire que le cerveau est constitué d'une constellation d'agents indépendants ou semi-indépendants) ont également été décrits par :
- Thomas R. Blakeslee,
- Michael S. Gazzaniga ,
- Robert E. Ornstein ,
- Ernest Hilgard ,
- Michio Kaku ,
- George Ivanovitch Gurdjieff ,
- Modèle cérébral de type neurocluster.