Un modèle de données est un modèle abstrait qui organise les éléments de données et normalise la façon dont ils sont liés les uns aux autres et aux propriétés des entités du monde réel . Par exemple, un modèle de données peut spécifier que l'élément de données représentant une voiture est composé d'un certain nombre d'autres éléments qui, à leur tour, représentent la couleur et la taille de la voiture et définissent son propriétaire.
L'activité professionnelle correspondante est généralement appelée modélisation des données ou, plus précisément, conception de bases de données . Les modèles de données sont généralement spécifiés par un expert en données, un spécialiste des données, un data scientist, un bibliothécaire de données ou un chercheur en données. Un langage et une notation de modélisation des données sont souvent représentés sous forme graphique, par exemple sous forme de diagrammes.
Un modèle de données peut parfois être qualifié de structure de données , notamment dans le contexte des langages de programmation . Les modèles de données sont souvent complétés par des modèles fonctionnels , en particulier dans le contexte des modèles d'entreprise .
Un modèle de données détermine explicitement la structure des données ; inversement, les données structurées sont des données organisées selon un modèle ou une structure de données explicite. Les données structurées s’opposent aux données non structurées et aux données semi-structurées .
objets et des relations propres à un domaine d'application particulier : par exemple, les clients, les produits et les commandes d'une entreprise manufacturière. Il peut aussi désigner l'ensemble des concepts utilisés pour définir de telles formalisations : par exemple, les entités, les attributs, les relations ou les tables. Ainsi, le « modèle de données » d'une application bancaire peut être défini à l'aide du modèle de données entité-relation. Cet article utilise ce terme dans les deux sens.La gestion de grandes quantités de données structurées et non structurées est une fonction essentielle des systèmes d'information . Les modèles de données décrivent la structure, la manipulation et l'intégrité des données stockées dans les systèmes de gestion de données, tels que les bases de données relationnelles. Ils peuvent également décrire des données à structure moins rigide, comme les documents de traitement de texte , les courriels , les images, les fichiers audio et vidéo numériques : XDM , par exemple, fournit un modèle de données pour les documents XML .
Le rôle des modèles de données
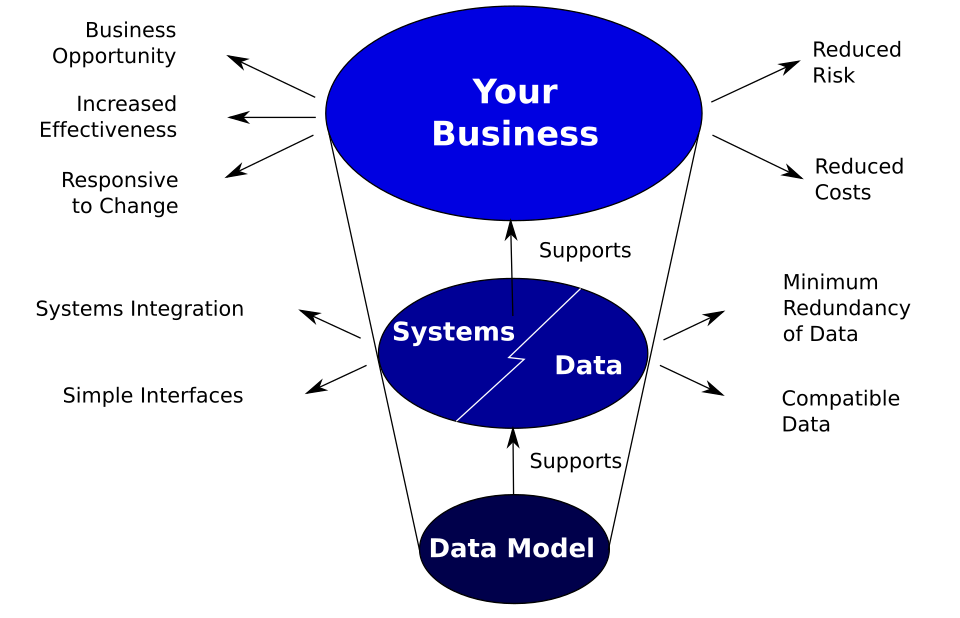
L'objectif principal des modèles de données est de faciliter le développement des systèmes d'information en fournissant la définition et le format des données. Selon West et Fowler (1999), « si cette démarche est appliquée de manière cohérente entre les systèmes, la compatibilité des données est assurée. Si les mêmes structures de données sont utilisées pour stocker et accéder aux données, différentes applications peuvent les partager. Les résultats obtenus sont présentés ci-dessus. Cependant, la construction, l'exploitation et la maintenance des systèmes et des interfaces s'avèrent souvent plus coûteuses que prévu. De plus, elles peuvent freiner l'activité de l'entreprise au lieu de la soutenir. Une des principales causes réside dans la faible qualité des modèles de données implémentés dans les systèmes et les interfaces. »
- « Les règles métier, spécifiques à la manière dont les choses sont faites dans un lieu particulier, sont souvent fixées dans la structure d’un modèle de données. Cela signifie que de petits changements dans la façon dont les affaires sont menées entraînent d’importants changements dans les systèmes informatiques et les interfaces. »
- « Les types d’entités ne sont souvent pas identifiés, ou sont identifiés incorrectement. Cela peut entraîner une duplication des données, de la structure des données et des fonctionnalités, ainsi que les coûts inhérents à cette duplication en matière de développement et de maintenance. »
- « Les modèles de données des différents systèmes sont arbitrairement différents. Il en résulte que des interfaces complexes sont nécessaires entre les systèmes qui partagent des données. Ces interfaces peuvent représenter entre 25 et 70 % du coût des systèmes actuels. »
- « Les données ne peuvent être partagées électroniquement avec les clients et les fournisseurs, car leur structure et leur signification n’ont pas été normalisées. Par exemple, les données et les dessins de conception technique des installations de traitement sont encore parfois échangés sur papier. »
La raison de ces problèmes réside dans l'absence de normes permettant de garantir que les modèles de données répondent aux besoins de l'entreprise et soient cohérents.
Un modèle de données définit explicitement la structure des données. Les applications typiques des modèles de données comprennent les modèles de bases de données, la conception de systèmes d'information et la facilitation de l'échange de données. Généralement, les modèles de données sont spécifiés dans un langage de modélisation de données.[3]
Trois perspectives

Une instance de modèle de données peut être de trois types selon l'ANSI en 1975 :
- Modèle conceptuel de données : il décrit la sémantique d’un domaine, constituant ainsi le périmètre du modèle. Par exemple, il peut s’agir d’un modèle du domaine d’intérêt d’une organisation ou d’un secteur d’activité. Ce modèle est composé de classes d’entités, représentant des types d’éléments significatifs dans le domaine, et d’assertions de relations décrivant les associations entre paires de classes d’entités. Un schéma conceptuel spécifie les types de faits ou de propositions pouvant être exprimés à l’aide du modèle. En ce sens, il définit les expressions autorisées dans un « langage » artificiel dont le périmètre est limité par celui du modèle.
- Modèle logique de données : décrit la sémantique, telle que représentée par une technologie de manipulation de données particulière. Il comprend notamment des descriptions de tables et de colonnes, de classes orientées objet et de balises XML.
- Modèle physique des données : décrit les moyens physiques par lesquels les données sont stockées. Il s’agit notamment des partitions, des processeurs, des espaces de tables, etc.
L'intérêt de cette approche, selon l'ANSI, réside dans l'indépendance relative qu'elle confère aux trois perspectives. La technologie de stockage peut évoluer sans impacter ni le modèle logique ni le modèle conceptuel. La structure des tables et des colonnes peut également changer sans (nécessairement) affecter le modèle conceptuel. Dans tous les cas, les structures doivent bien entendu rester cohérentes avec l'autre modèle. La structure des tables et des colonnes peut différer d'une simple transposition des classes d'entités et de leurs attributs, mais elle doit impérativement remplir les objectifs de la structure conceptuelle des classes d'entités. Les premières phases de nombreux projets de développement logiciel privilégient la conception d'un modèle conceptuel de données . Cette conception peut ensuite être détaillée dans un modèle logique de données . Ultérieurement, ce modèle peut être traduit en un modèle physique de données . Il est toutefois possible d'implémenter directement un modèle conceptuel.
Histoire
L'un des premiers travaux pionniers en modélisation des systèmes d'information a été réalisé par Young et Kent (1958) qui plaidaient pour « une méthode précise et abstraite de spécification des caractéristiques informationnelles et temporelles d'un problème de traitement de données ». Ils souhaitaient créer « une notation permettant à l' analyste d'organiser le problème autour de n'importe quel matériel ». Leurs travaux constituaient la première tentative de création d'une spécification abstraite et d'une base invariante pour la conception de différentes implémentations alternatives utilisant divers composants matériels. L'étape suivante en modélisation des systèmes d'information a été franchie par CODASYL , un consortium de l'industrie informatique formé en 1959, qui visait essentiellement le même objectif que Young et Kent : le développement d'une structure appropriée pour un langage de définition de problèmes indépendant de la machine, au niveau système du traitement des données. Ceci a conduit au développement d'une algèbre de l'information spécifique aux systèmes d'information .
Dans les années 1960, la modélisation des données a pris une importance accrue avec l'avènement du concept de système d'information de gestion (SIG). Selon Leondes (2002), « à cette époque, le système d'information fournissait les données et les informations nécessaires à la gestion. Le système de base de données de première génération , appelé Integrated Data Store (IDS), a été conçu par Charles Bachman chez General Electric. Deux modèles de bases de données célèbres, le modèle de données en réseau et le modèle de données hiérarchique , ont été proposés durant cette période. » Vers la fin des années 1960, Edgar F. Codd a élaboré ses théories sur l'organisation des données et a proposé le modèle relationnel pour la gestion des bases de données, basé sur la logique des prédicats du premier ordre .
Dans les années 1970, la modélisation entité-relation a émergé comme un nouveau type de modélisation conceptuelle des données, formalisée initialement en 1976 par Peter Chen . Les modèles entité-relation étaient utilisés lors de la première étape de la conception des systèmes d'information, pendant l' analyse des besoins, afin de décrire les besoins en information ou le type d' information à stocker dans une base de données . Cette technique permet de décrire toute ontologie , c'est-à-dire une vue d'ensemble et une classification des concepts et de leurs relations, pour un domaine d'intérêt donné .
Dans les années 1970, G.M. Nijssen a développé la méthode d'analyse de l'information en langage naturel (NIAM), qu'il a perfectionnée dans les années 1980 en collaboration avec Terry Halpin pour aboutir à la modélisation objet-rôle (ORM). Cependant, c'est la thèse de doctorat de Terry Halpin, soutenue en 1989, qui a posé les fondements formels de la modélisation objet-rôle.
Dans son ouvrage de 1978 , *Data and Reality* , Bill Kent compare un modèle de données à une carte territoriale, soulignant que dans la réalité, « les autoroutes ne sont pas peintes en rouge, les rivières ne sont pas traversées par des limites de comté et les courbes de niveau des montagnes sont invisibles ». Contrairement à d'autres chercheurs qui s'efforçaient de créer des modèles mathématiquement rigoureux et élégants, Kent insistait sur la complexité inhérente au monde réel et sur la tâche du modélisateur de données : structurer le chaos sans déformer excessivement la réalité.
Dans les années 1980, selon Jan L. Harrington (2000), « le développement du paradigme orienté objet a fondamentalement transformé notre façon d’appréhender les données et les procédures qui les manipulent. Traditionnellement, les données et les procédures étaient stockées séparément : les données et leurs relations dans une base de données, les procédures dans un programme d’application. L’orientation objet, en revanche, a combiné la procédure d’une entité avec ses données. »
Au début des années 1990, trois mathématiciens néerlandais, Guido Bakema, Harm van der Lek et JanPieter Zwart, ont poursuivi les travaux de GM Nijssen , en se concentrant davantage sur l'aspect communicationnel de la sémantique. En 1997, ils ont formalisé la méthode de modélisation de l'information entièrement orientée communication (FCO-IM) .
Types
Modèle de base de données


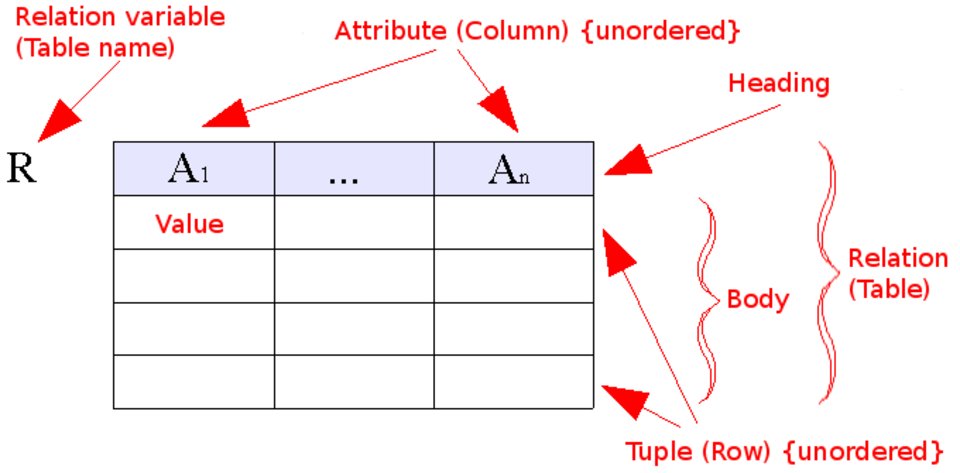
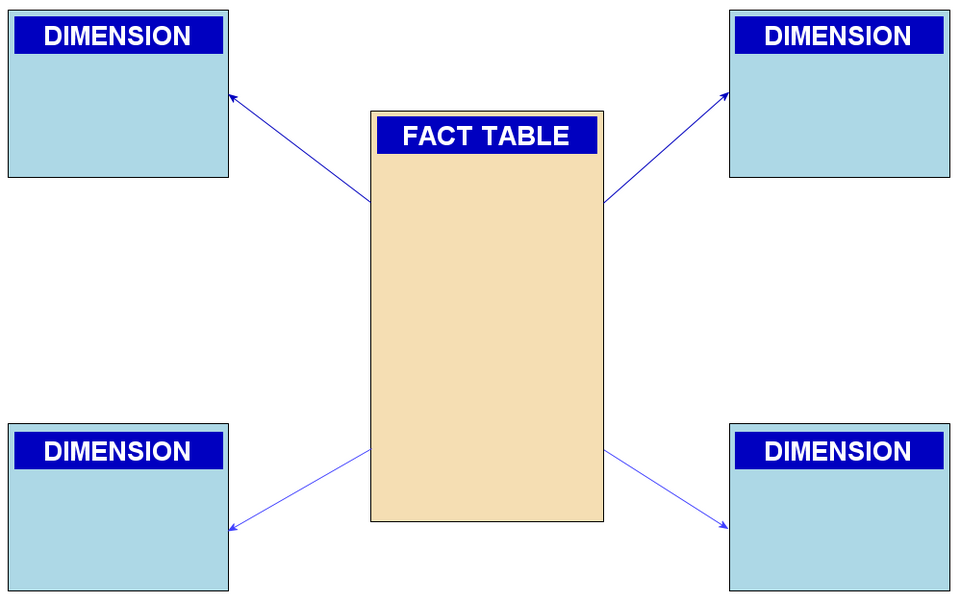
Diagramme de structure de données
Un diagramme de structure de données (DSD) est un diagramme et un modèle de données utilisé pour décrire des modèles de données conceptuels. Il fournit des notations graphiques qui documentent les entités , leurs relations et les contraintes qui les lient. Les éléments graphiques de base des DSD sont les rectangles , représentant les entités, et les flèches , représentant les relations. Les diagrammes de structure de données sont particulièrement utiles pour documenter des entités de données complexes.
Les diagrammes de structure de données (DSD) sont une extension du modèle entité-relation (modèle ER). Dans les DSD, les attributs sont spécifiés à l'intérieur des entités et non à l'extérieur, tandis que les relations sont représentées par des rectangles composés d'attributs qui définissent les contraintes liant les entités. Les DSD diffèrent du modèle ER en ce que ce dernier se concentre sur les relations entre les différentes entités, tandis que les DSD se concentrent sur les relations entre les éléments d'une même entité et permettent aux utilisateurs de visualiser pleinement les liens et les relations entre chaque entité.
Il existe plusieurs styles de représentation des diagrammes de structures de données, la principale différence résidant dans la manière de définir la cardinalité . On peut opter pour des flèches, des flèches inversées ( pattes de corbeau ) ou une représentation numérique de la cardinalité.

Modèle entité-relation
Il existe plusieurs styles de représentation des diagrammes de structures de données, la principale différence résidant dans la manière de définir la cardinalité. On peut opter pour des flèches, des flèches inversées (pattes de corbeau) ou une représentation numérique de la cardinalité.
Modèle de données géographiques
- Le modèle de données vectorielles représente la géographie sous forme de points, de lignes et de polygones.
- Le modèle de données raster représente la géographie sous forme de matrices de cellules qui stockent des valeurs numériques ;
- et le modèle de données de réseau irrégulier triangulé (TIN) représente la géographie comme des ensembles de triangles contigus et non superposés.

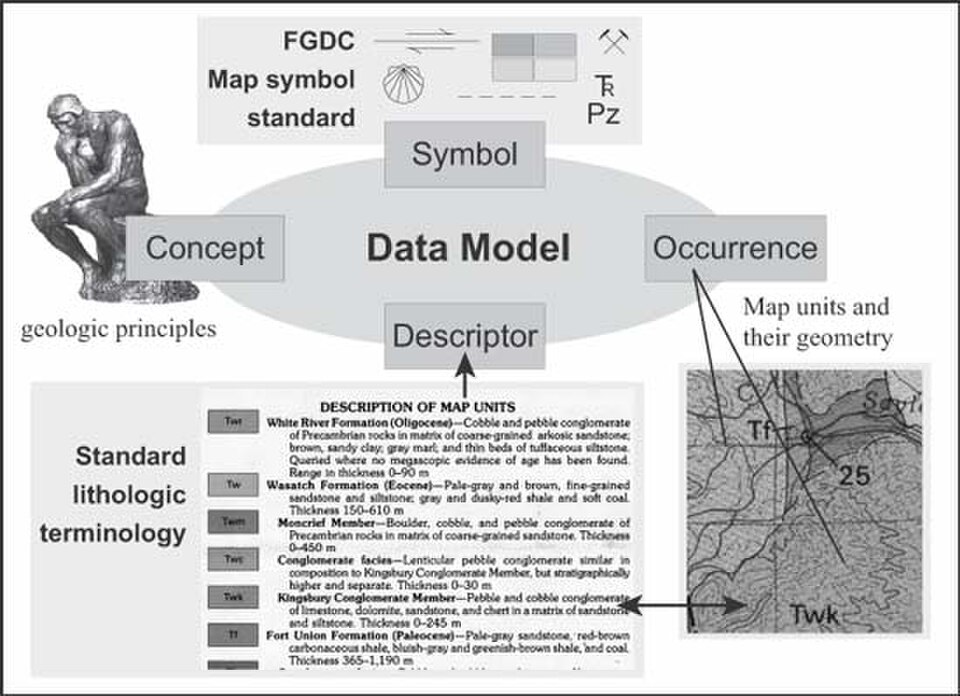
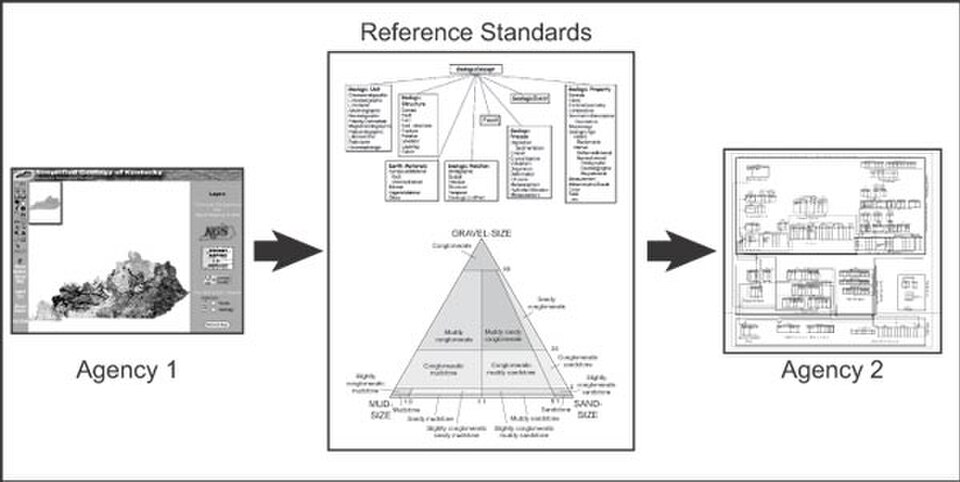

Modèle de données générique
En génie logiciel, un modèle de données sémantique est une technique permettant de définir la signification des données en fonction de leurs interrelations avec d'autres données. Il s'agit d'une abstraction qui décrit comment les symboles stockés interagissent avec le monde réel. Un modèle de données sémantique est parfois appelé modèle de données conceptuel .
La structure logique des données d'un système de gestion de bases de données (SGBD), qu'elle soit hiérarchique , réseau ou relationnelle , ne peut satisfaire pleinement aux exigences d'une définition conceptuelle des données, car sa portée est limitée et elle est influencée par la stratégie d'implémentation du SGBD. Par conséquent, la nécessité de définir les données d'un point de vue conceptuel a conduit au développement de techniques de modélisation sémantique des données. Autrement dit, des techniques permettant de définir la signification des données dans le contexte de leurs interrelations avec d'autres données. Comme illustré dans la figure, le monde réel, en termes de ressources, d'idées, d'événements, etc., est défini symboliquement au sein de supports de stockage physiques. Un modèle de données sémantique est une abstraction qui définit la manière dont les symboles stockés se rapportent au monde réel. Ainsi, le modèle doit être une représentation fidèle du monde réel.
Sujets
Architecture des données
Une architecture de données décrit les structures de données utilisées par une entreprise et/ou ses applications. Elle comprend des descriptions des données stockées et des données en transit ; des descriptions des bases de données, des groupes de données et des éléments de données ; ainsi que des correspondances entre ces éléments de données et leurs qualités, applications, emplacements, etc.
Essentielle à la réalisation de l'objectif, l'architecture des données décrit comment les données sont traitées, stockées et utilisées dans un système donné. Elle fournit des critères pour les opérations de traitement des données, permettant ainsi de concevoir les flux de données et de contrôler ces flux au sein du système.
Modélisation des données
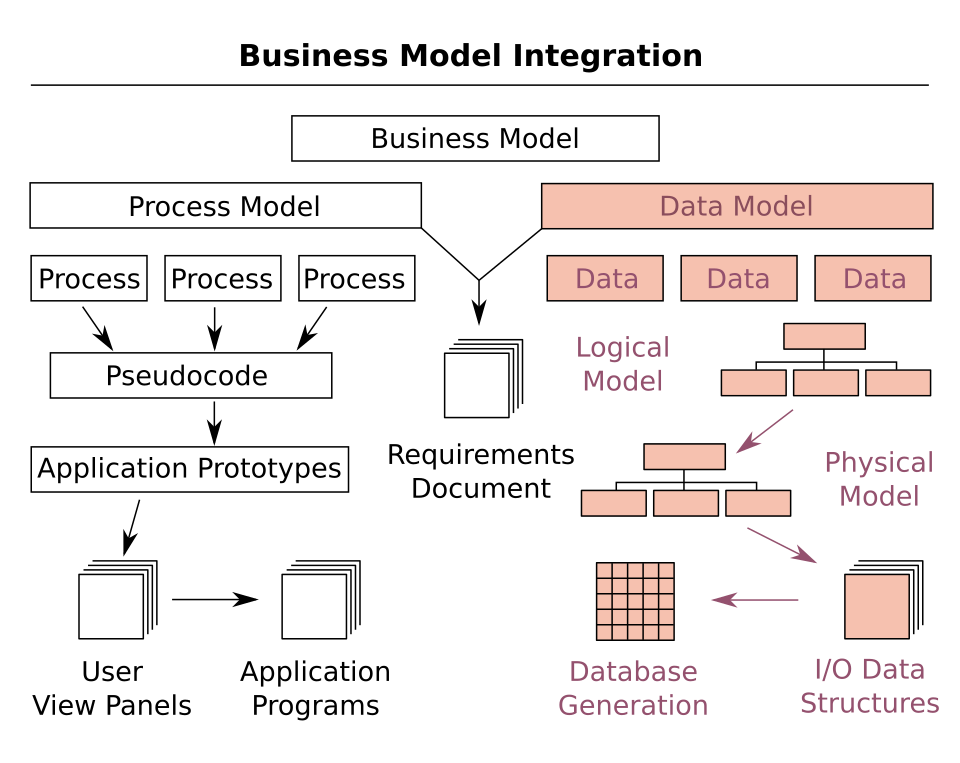
La modélisation des données en génie logiciel est le processus de création d'un modèle de données par l'application de descriptions formelles de modèles de données à l'aide de techniques de modélisation. La modélisation des données est une technique permettant de définir les exigences métier d'une base de données. On parle parfois de modélisation de base de données, car un modèle de données est finalement implémenté dans une base de données.
La figure illustre la manière dont les modèles de données sont développés et utilisés aujourd'hui. Un modèle de données conceptuel est élaboré à partir des besoins en données de l'application en cours de développement, éventuellement dans le cadre d'un modèle d'activité . Ce modèle comprend généralement des types d'entités, des attributs, des relations, des règles d'intégrité et les définitions de ces objets. Il sert ensuite de point de départ à la conception de l'interface ou de la base de données .
propriétés des données
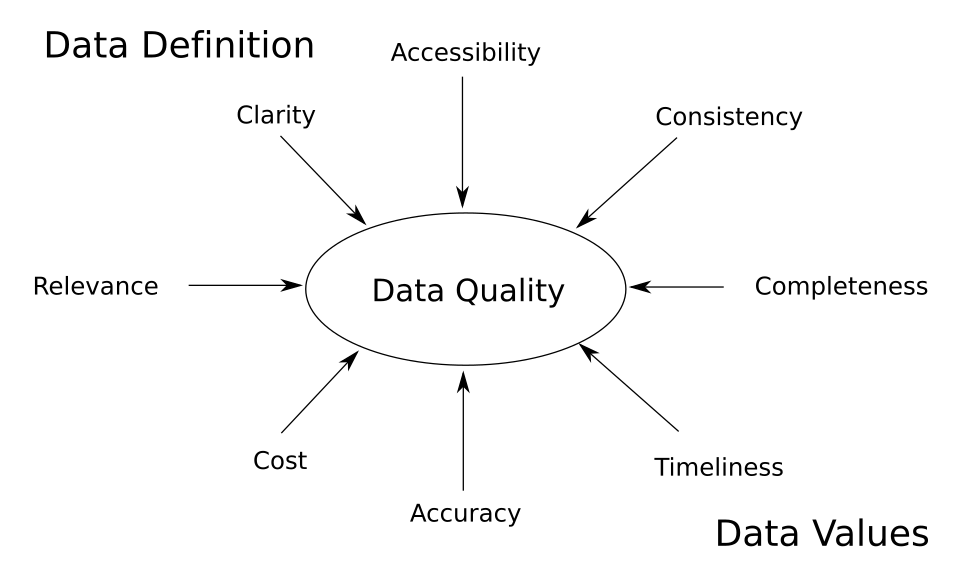
Voici quelques propriétés importantes des données auxquelles des exigences doivent être respectées :
- propriétés liées à la définition
- Pertinence : l’utilité des données au regard de leur finalité ou application prévue.
- Clarté : l’existence d’une définition claire et partagée des données.
- Cohérence : la compatibilité de données de même type provenant de sources différentes.
- propriétés liées au contenu
- actualité : la disponibilité des données au moment requis et leur niveau de mise à jour.
- Précision : à quel point les données sont proches de la réalité.
- propriétés liées à la fois à la définition et au contenu
- exhaustivité : quelle quantité des données requises est disponible ?
- accessibilité : où, comment et à qui les données sont disponibles ou non (par exemple, sécurité).
- coût : le coût encouru pour obtenir les données et les rendre disponibles à l'utilisation.
Organisation des données
Un autre type de modèle de données décrit comment organiser les données à l'aide d'un système de gestion de base de données ou d'une autre technologie de gestion de données. Il décrit, par exemple, les tables et colonnes relationnelles ou les classes et attributs orientés objet. Ce modèle de données est parfois appelé modèle physique , mais dans l'architecture ANSI à trois schémas d'origine, il est qualifié de « logique ». Dans cette architecture, le modèle physique décrit les supports de stockage (cylindres, pistes et espaces de tables). Idéalement, ce modèle dérive du modèle de données plus conceptuel décrit précédemment. Il peut toutefois différer pour tenir compte de contraintes telles que la capacité de traitement et les modes d'utilisation.
Bien que l'analyse de données soit un terme courant pour désigner la modélisation de données, cette activité a en réalité plus en commun avec les idées et les méthodes de la synthèse (déduire des concepts généraux à partir d'exemples particuliers) qu'avec l'analyse (identifier les concepts constitutifs à partir de concepts plus généraux). { On se qualifie probablement d'analystes de systèmes car personne ne peut dire « synthétiseur de systèmes » . } La modélisation de données vise à rassembler les structures de données d'intérêt en un tout cohérent et indissociable en éliminant les redondances de données inutiles et en reliant les structures de données par des relations .
Une autre approche consiste à utiliser des systèmes adaptatifs tels que les réseaux neuronaux artificiels , capables de créer de manière autonome des modèles implicites de données.
structure de données
Une structure de données est une manière de stocker des données dans un ordinateur afin de les utiliser efficacement. Il s'agit d'une organisation des concepts mathématiques et logiques des données. Souvent, une structure de données judicieusement choisie permet d'utiliser l' algorithme le plus performant . Le choix de la structure de données commence souvent par le choix d'un type de données abstrait .
Un modèle de données décrit la structure des données au sein d'un domaine donné et, par extension, la structure sous-jacente de ce domaine. Autrement dit, un modèle de données spécifie une grammaire dédiée à un langage artificiel spécifique à ce domaine. Il représente les classes d'entités (types d'objets) sur lesquelles une entreprise souhaite détenir des informations, les attributs de ces informations, ainsi que les relations entre ces entités et les relations (souvent implicites) entre leurs attributs. Le modèle décrit l'organisation des données, indépendamment de leur représentation dans un système informatique.
Les entités représentées par un modèle de données peuvent être des entités tangibles, mais les modèles incluant de telles classes d'entités concrètes ont tendance à évoluer. Les modèles de données robustes identifient souvent des abstractions de ces entités. Par exemple, un modèle de données peut inclure une classe d'entité appelée « Personne », représentant toutes les personnes interagissant avec une organisation. Une telle classe d'entité abstraite est généralement plus appropriée que des classes appelées « Fournisseur » ou « Employé », qui identifient des rôles spécifiques joués par ces personnes.