

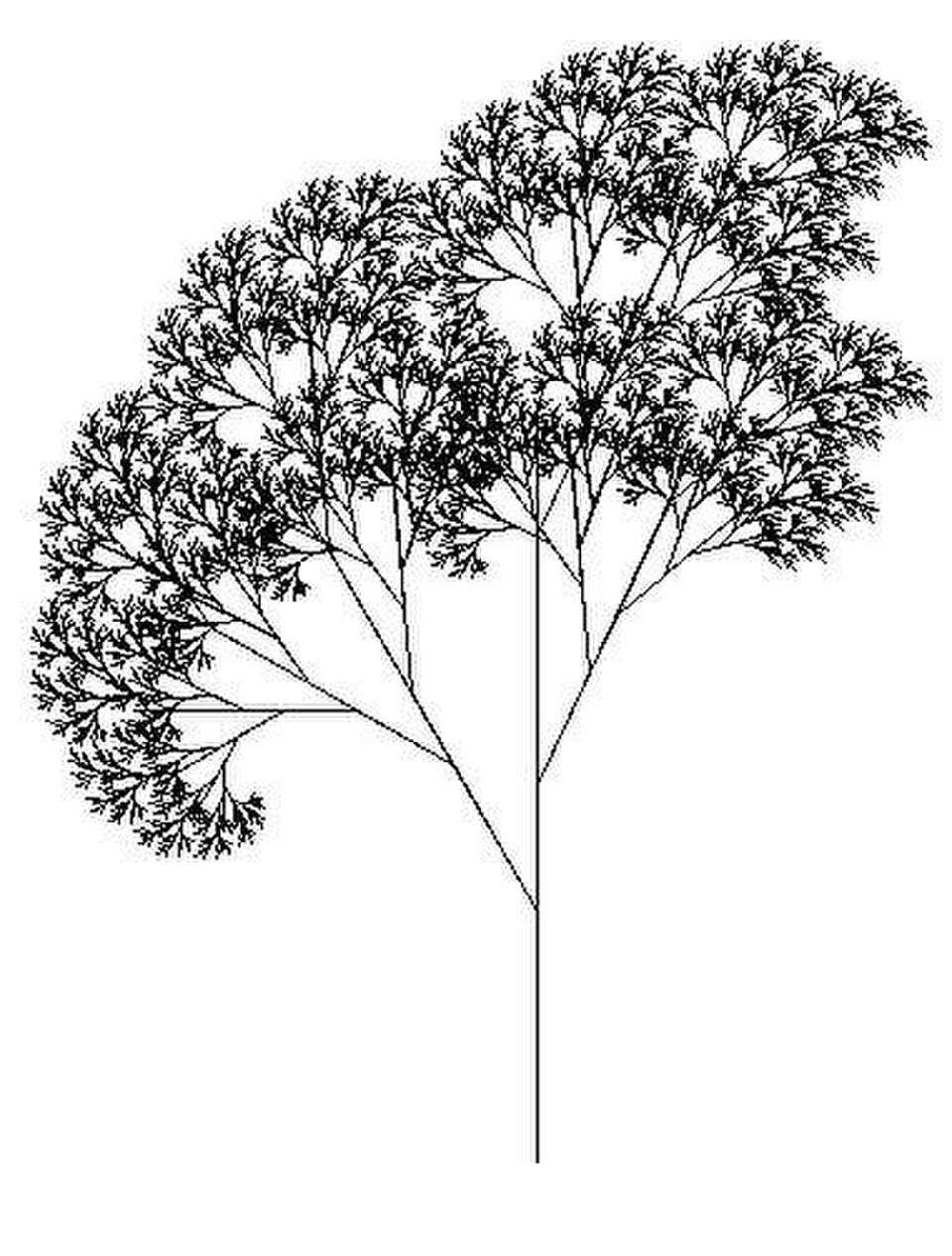
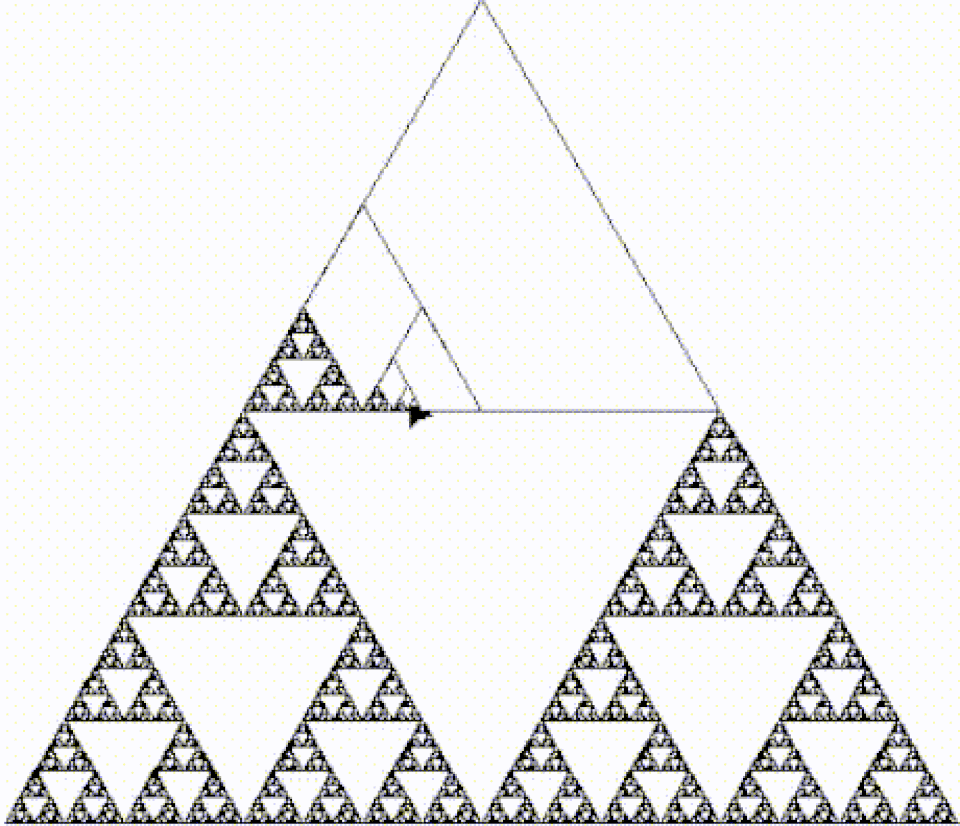
En informatique , la récursivité est une méthode de résolution de problèmes informatiques dont la solution dépend de solutions à des instances plus petites de ce même problème. La récursivité résout ces problèmes récursifs en utilisant des fonctions qui s'appellent elles-mêmes au sein de leur propre code. Cette approche peut être appliquée à de nombreux types de problèmes, et la récursivité est l'un des concepts fondamentaux de l'informatique.
La puissance de la récursivité réside manifestement dans la possibilité de définir un ensemble infini d'objets par une instruction finie . De même, un nombre infini de calculs peut être décrit par un programme récursif fini, même si ce programme ne contient aucune répétition explicite.
— Niklaus Wirth , Algorithmes + Structures de données = Programmes , 1976
La plupart des langages de programmation prennent en charge la récursivité en permettant à une fonction de s'appeler elle-même depuis son propre code. Certains langages de programmation fonctionnelle (par exemple, Clojure ) ne définissent aucune boucle intégrée et reposent exclusivement sur la récursivité. Il est démontré, en théorie de la calculabilité, que ces langages récursifs sont Turing-complets ; cela signifie qu'ils sont aussi puissants (ils peuvent être utilisés pour résoudre les mêmes problèmes) que les langages impératifs basés sur des structures de contrôle telles que ` pile d'appels, dont la taille sera égale à la somme des tailles des entrées de tous les appels impliqués. Il s'ensuit que, pour les problèmes facilement résolubles par itération, la récursivité est généralement moins efficace et que, pour certains problèmes, des techniques d'optimisation algorithmique ou du compilateur, telles que l'optimisation des appels terminaux , peuvent améliorer les performances de calcul par rapport à une implémentation récursive naïve.la récursivité en informatique est né de la logique mathématique et est devenu par la suite un élément essentiel de la conception des langages de programmation . Les premiers travaux de Church , Gödel , Kleene et Turing sur les fonctions récursives et la calculabilité ont jeté les bases qui ont rendu la récursivité possible dans les langages de programmation. La récursivité est utilisée par les mathématiciens depuis longtemps, mais elle n'est devenue un outil pratique de programmation qu'à la fin des années 1950 et au début des années 1960. Des personnalités clés telles que John McCarthy et le comité de conception d'ALGOL 60 ont contribué à l'introduction de la récursivité en programmation.
John McCarthy a posé les premiers jalons en créant le langage de programmation LISP en 1960. Dans son article « Recursive Functions of Symbolic Expressions and Their Computation by Machine, Part I » , McCarthy a démontré que la récursivité pouvait être au cœur d'un langage de programmation manipulant des symboles par étapes. En LISP, la récursivité pouvait être utilisée dans des fonctions selon des règles simples, et il existait également une méthode pour les évaluer. Ceci a démontré que la récursivité était une approche pratique pour écrire des programmes et qu'elle décrivait également le processus de calcul. Par conséquent, LISP est devenu l'un des premiers langages de programmation à utiliser la récursivité comme caractéristique principale, et a par la suite influencé d'autres langages.
Durant cette période, la récursivité a également été ajoutée à ALGOL 60. [ rapport sur le langage algorithmique ALGOL 60 , publié en 1960, était le fruit d'une tentative internationale de conception d'un langage standard. L'une des nouvelles fonctionnalités importantes du langage était la possibilité pour les procédures de s'appeler elles-mêmes. Auparavant, seules les boucles étaient autorisées, ce qui représentait donc un changement significatif. La récursivité a permis aux programmeurs de décrire les algorithmes de manière plus naturelle et plus flexible.
Structure d'une fonction récursive
La définition d'une fonction récursive se divise généralement en deux parties : un ou plusieurs cas de base et un ou plusieurs cas récursifs. Cette structure reflète la logique de l'induction mathématique , une technique de démonstration où la preuve du ou des cas de base et de l'étape d'induction garantit qu'un théorème donné est vrai pour toutes les entrées valides.
Cas de base
Le cas de base spécifie les valeurs d'entrée pour lesquelles la fonction peut fournir un résultat directement, sans récursion supplémentaire. Il s'agit généralement des entrées les plus simples ou les plus petites possibles (qui peuvent être résolues trivialement), permettant ainsi l'arrêt du calcul. Les cas de base sont essentiels car ils empêchent la régression infinie. Autrement dit, ils définissent une condition d'arrêt qui met fin à la récursion.
Un exemple est le calcul de la factorielle d'un entier n, qui est le produit de tous les entiers de 0 à n. Pour ce problème, la définition 0! = 1 est un cas de base. Sans elle, la récursion peut se poursuivre indéfiniment, entraînant une non-terminaison, voire des erreurs de dépassement de capacité de la pile dans les implémentations réelles.
La conception d'un cas de base correct est cruciale pour des raisons à la fois théoriques et pratiques. Certains problèmes possèdent un cas de base naturel (par exemple, la liste vide est un cas de base dans certaines fonctions récursives de traitement de listes), tandis que d'autres nécessitent un paramètre supplémentaire pour fournir un critère d'arrêt (par exemple, l'utilisation d'un compteur de profondeur dans le parcours récursif d'arbres ).
En programmation informatique récursive , l'omission ou la définition incorrecte du cas de base peut entraîner une récursion infinie imprévue. Une étude a montré que de nombreux étudiants ont des difficultés à identifier les cas de base appropriés.
Cas récursif
Le cas récursif décrit comment décomposer un problème en sous-problèmes plus petits de même forme. Chaque étape récursive transforme l'entrée afin qu'elle se rapproche d'un cas de base, assurant ainsi la progression vers la terminaison. Si l'étape de réduction ne permet pas de progresser vers un cas de base, l'algorithme peut se retrouver piégé dans une boucle infinie .
Dans l' exemple de la factorielle , le cas récursif est défini comme suit : ici, chaque appel de la fonction diminue l'entrée de 1. Ainsi, il garantit que la récursion atteint finalement le cas de base de . 0." 
Le cas récursif est analogue à l'étape d'induction dans une démonstration par récurrence : il suppose que la fonction est valide pour une instance plus petite, puis étend cette hypothèse à l'entrée courante. Les définitions et algorithmes récursifs sont donc très proches des raisonnements inductifs en mathématiques , et leur validité repose souvent sur des techniques de raisonnement similaires.
Exemples
La récursivité trouve de nombreuses applications pratiques qui suivent la structure cas de base/cas récursif. Elle est largement utilisée pour résoudre des problèmes complexes en informatique.
- Les parcours d'arbres , tels que la recherche en profondeur d'abord , utilisent un cas récursif pour traiter chaque sous-arbre (le cas récursif), s'arrêtant finalement aux nœuds feuilles (le cas de base).
- Le tri fusion est un algorithme de tri qui trie et fusionne récursivement des sous-tableaux divisés (cas récursif) jusqu'à ce que chaque sous-tableau ne contienne plus qu'un seul élément (cas de base).
- La suite de Fibonacci est définie en additionnant les deux nombres précédents de la suite (cas récursif), en s'arrêtant lorsque n = 0 ou n = 1 (cas de base).
- La recherche binaire divise à plusieurs reprises l'intervalle de recherche en deux (cas récursif) jusqu'à ce que la cible soit trouvée ou que l'intervalle soit vide (cas de base).
Types de données récursifs
De nombreux programmes informatiques doivent traiter ou générer une quantité arbitrairement grande de données . La récursivité est une technique permettant de représenter des données dont la taille exacte est inconnue du programmeur : celui-ci peut spécifier ces données à l’aide d’une définition autoréférentielle . Il existe deux types de définitions autoréférentielles : les définitions inductives et les définitions coinductives .
les listes chaînées peuvent être définies par induction (ici, en utilisant la syntaxe Haskell ) :De même, les définitions récursives sont souvent utilisées pour modéliser la structure des expressions et des instructions dans les langages de programmation. Les concepteurs de langages expriment fréquemment les grammaires sous une syntaxe telle que la forme Backus-Naur ; voici un exemple de grammaire pour un langage simple d’expressions arithmétiques avec multiplication et addition :flux infinis de chaînes de caractères, donnée de manière informelle, pourrait ressembler à ceci :Un flux de chaînes de caractères est un objet s tel que : head(s) est une chaîne de caractères, et tail(s) est un flux de chaînes de caractères.
Ceci est très similaire à une définition inductive des listes de chaînes de caractères ; la différence est que cette définition spécifie comment accéder au contenu de la structure de données — à savoir, via les fonctions d'accèshead et tail— et quel peut être ce contenu, tandis que la définition inductive spécifie comment créer la structure et à partir de quoi elle peut être créée.
La corécurisation est liée à la coinduction et permet de calculer des instances particulières d'objets (éventuellement) infinis. En tant que technique de programmation, elle est surtout utilisée dans le contexte des langages paresseux et peut s'avérer préférable à la récursivité lorsque la taille ou la précision souhaitée du résultat d'un programme est inconnue. Dans ce cas, le programme requiert à la fois une définition d'un résultat infiniment grand (ou infiniment précis) et un mécanisme permettant d'en extraire une portion finie. Le calcul des n premiers nombres premiers est un problème qui peut être résolu par un programme corécuratif (voir par exemple ici ).
Types de récursivité
Récursivité simple et récursivité multiple
La récursivité qui ne contient qu'une seule auto-référence est appeléeLa récursivité simple est appelée récursivité simple , tandis que la récursivité contenant plusieurs auto-références est appelée récursivité double.le parcours d'arbres, comme dans une recherche en profondeur.
La récursivité simple est souvent bien plus efficace que la récursivité multiple et peut généralement être remplacée par un calcul itératif, s'exécutant en temps linéaire et nécessitant un espace constant. La récursivité multiple, en revanche, peut nécessiter un temps et un espace exponentiels et est plus fondamentalement récursive, ne pouvant être remplacée par une itération sans une pile explicite.
Il est parfois possible de convertir une récursion multiple en une récursion simple (et, si nécessaire, en une itération). Par exemple, alors que le calcul de la suite de Fibonacci nécessite naïvement plusieurs itérations, puisque chaque valeur requiert deux valeurs précédentes, il peut être effectué par une récursion simple en passant deux valeurs successives comme paramètres.
Récursivité indirecte
récursivité mutuelle , terme plus symétrique, bien qu'il s'agisse simplement d'une nuance et non d'une notion différente. Autrement dit, si f appelle g , puis g appelle f, qui à son tour appelle g , du point de vue de f seule, f est indirectement récursive ; du point de vue de g seule, elle l'est également ; mais du point de vue des deux, f et g sont mutuellement récursives. De même, un ensemble de trois fonctions ou plus qui s'appellent mutuellement peut être qualifié d'ensemble de fonctions mutuellement récursives.Récursion anonyme
les fonctions anonymes ; on parle alors de récursivité anonyme .Récursivité structurelle versus récursivité générative
Comment concevoir des programmes , 2001 Ainsi, la caractéristique déterminante d'une fonction structurellement récursive est que l'argument de chaque appel récursif est le contenu d'un champ de l'entrée d'origine. La récursivité structurelle englobe la quasi-totalité des parcours d'arbres, y compris le traitement XML, la création et la recherche dans les arbres binaires, etc. Compte tenu de la structure algébrique des nombres naturels (un nombre naturel est soit zéro, soit le successeur d'un nombre naturel), des fonctions telles que la factorielle peuvent également être considérées comme relevant de la récursivité structurelle.
HtDP ( How to Design Programs ) désigne ce type de récursivité sous le nom de récursivité générative. Parmi les exemples de récursivité générative, on peut citer : le PGCD , le tri rapide , la recherche binaire , le tri fusion , la méthode de Newton , les fractales et l’intégration adaptative .
— Matthias Felleisen, Programmation fonctionnelle avancée , 2002
Cette distinction est importante pour prouver la terminaison d'une fonction.
- Il est facile de démontrer que toutes les fonctions structurellement récursives sur des structures de données finies ( définies par induction ) se terminent, par induction structurelle : intuitivement, chaque appel récursif reçoit une plus petite partie des données d'entrée, jusqu'à ce qu'un cas de base soit atteint.
- Les fonctions génératives récursives, en revanche, ne fournissent pas nécessairement des entrées plus petites à leurs appels récursifs ; la preuve de leur terminaison est donc plus complexe et éviter les boucles infinies exige une plus grande vigilance. Ces fonctions peuvent souvent être interprétées comme des fonctions corécursives : chaque étape génère de nouvelles données, à l’instar des approximations successives de la méthode de Newton. La terminaison de cette corécurisation requiert que les données satisfassent finalement une certaine condition, ce qui n’est pas garanti.
- En termes de variantes de boucle , la récursivité structurelle se produit lorsqu'il existe une variante de boucle évidente, à savoir la taille ou la complexité, qui commence par une valeur finie et diminue à chaque étape récursive.
- En revanche, la récursivité générative intervient lorsqu'il n'existe pas de variante de boucle aussi évidente, et que la terminaison dépend d'une fonction, telle que « l'erreur d'approximation », qui ne tend pas nécessairement vers zéro, et que la terminaison n'est donc pas garantie sans analyse plus approfondie.
Problèmes de mise en œuvre
En pratique, plutôt qu'une fonction purement récursive (une seule vérification du cas de base, sinon une étape récursive), un certain nombre de modifications peuvent être apportées, par souci de clarté ou d'efficacité. Celles-ci incluent :
- Fonction d'encapsulation (en haut)
- Court-circuitage du cas de base, également appelé « récursivité à distance » (en bas)
- Algorithme hybride (en bas) – passage à un autre algorithme lorsque les données sont suffisamment petites
Par souci d'élégance, les fonctions d'encapsulation sont généralement privilégiées, tandis que le contournement du cas de base est mal vu, notamment dans le milieu universitaire. Les algorithmes hybrides sont souvent utilisés pour des raisons d'efficacité, afin de réduire la surcharge liée à la récursivité dans les cas simples ; la récursivité indirecte en est un cas particulier.
Fonction d'encapsulation
Une fonction wrapper est une fonction qui est appelée directement mais qui ne s'exécute pas récursivement, appelant plutôt une fonction auxiliaire distincte qui effectue réellement la récursivité.
Les fonctions d'encapsulation permettent de valider les paramètres (afin que la fonction récursive puisse les ignorer), d'effectuer l'initialisation (allocation de mémoire, initialisation des variables), notamment pour les variables auxiliaires telles que le niveau de récursion ou les calculs partiels pour la mémoïsation , et de gérer les exceptions et les erreurs. Dans les langages prenant en charge les fonctions imbriquées , la fonction auxiliaire peut être imbriquée dans la fonction d'encapsulation et utiliser une portée partagée. En l'absence de fonctions imbriquées, les fonctions auxiliaires sont alors des fonctions distinctes, si possible privées (puisqu'elles ne sont pas appelées directement), et les informations sont partagées avec la fonction d'encapsulation par passage par référence .
Court-circuit du boîtier de base
L'optimisation par court-circuit est surtout pertinente lorsque de nombreux cas de base sont rencontrés, comme les pointeurs nuls dans un arbre, ce qui peut engendrer des gains linéaires par rapport au nombre d'appels de fonction et donc des économies significatives pour les algorithmes en recherche en profondeur (DFS) d'un arbre binaire ; voir la section sur les arbres binaires pour une discussion récursive standard.
L'algorithme récursif standard pour un parcours en profondeur (DFS) est :
- Cas de base : si le nœud actuel est nul, renvoyer faux
- Étape récursive : sinon, vérifiez la valeur du nœud actuel, renvoyez vrai si elle correspond, sinon récursivez sur les enfants
En court-circuit, cela donne plutôt :
- vérifier la valeur du nœud actuel, renvoyer vrai si la correspondance est trouvée,
- sinon, pour les enfants, si la valeur n'est pas nulle, alors récursion.
Concernant les étapes standard, cela déplace la vérification du cas de base avant l'étape récursive. On peut également considérer ces étapes comme une variante de la vérification du cas de base et de l'étape récursive. Notez que cela nécessite une fonction d'encapsulation pour gérer le cas où l'arbre est vide (le nœud racine est nul).
Dans le cas d'un arbre binaire parfait de hauteur h, il y a 2 h +1 − 1 nœuds et 2 h +1 pointeurs nuls comme enfants (2 pour chacune des 2 h feuilles), donc le court-circuitage réduit de moitié le nombre d'appels de fonction dans le pire des cas.
En C, l'algorithme récursif standard peut être implémenté comme suit :
bool tree_contains ( struct BinaryTree * node , int i ) { if ( ! node ) { return false ; // cas de base } else if ( node- > data == i ) { return true ; } else { return tree_contains ( node- > left , i ) || tree_contains ( node- > right , i ); } }
L'algorithme court-circuité peut être implémenté comme suit :
Algorithme hybride
Les algorithmes récursifs sont souvent inefficaces pour les petits ensembles de données, en raison du coût des appels et retours de fonctions répétés. C'est pourquoi les implémentations efficaces d'algorithmes récursifs commencent généralement par l'algorithme récursif, puis basculent vers un autre algorithme lorsque la taille des données diminue. Un exemple important est le tri fusion , souvent implémenté en passant au tri par insertion non récursif lorsque les données sont suffisamment petites, comme dans le tri fusion par tuiles . Les algorithmes récursifs hybrides peuvent souvent être optimisés, comme Timsort , dérivé d'un tri fusion/tri par insertion hybride.
Récursivité versus itération
La récursivité et l'itération sont tout aussi expressives : la récursivité peut être remplacée par une itération avec une pile d'appels explicite , et inversement . Le choix de l'approche dépend du problème considéré et du langage utilisé. En programmation impérative , l'itération est privilégiée, notamment pour la récursivité simple, car elle évite la surcharge liée aux appels de fonctions et à la gestion de la pile d'appels. En revanche, la récursivité est généralement utilisée pour les récursions multiples. Dans les langages fonctionnels, la récursivité est privilégiée, l'optimisation par récursivité terminale n'entraînant qu'une faible surcharge. La mise en œuvre d'un algorithme par itération peut s'avérer complexe.
Comparez les modèles pour calculer x n défini par x n = f(n, x n-1 ) à partir de la base x :
fonction récursive(n) si n == base retourner x base sinon retourner f(n, récursive(n - 1)) | fonction itérative(n) x = x base pour i = base + 1 à n x = f(i, x) retourner x |
Pour un langage impératif, la surcharge consiste à définir la fonction, et pour un langage fonctionnel, la surcharge consiste à définir la variable d'accumulation x.
Par exemple, une fonction factorielle peut être implémentée de manière itérative en C en assignant des valeurs à une variable d'index de boucle et à une variable accumulateur, plutôt qu'en passant des arguments et en retournant des valeurs par récursion :
unsigned int factorielle ( unsigned int n ) { unsigned int produit = 1 ; // produit vide = 1 while ( n > 0 ) { produit *= n ; -- n ; } return produit ; }
Pouvoir expressif
La plupart des langages de programmation actuels permettent de spécifier directement des fonctions et des procédures récursives. Lorsqu'une telle fonction est appelée, l' environnement d'exécution du programme conserve la trace des différentes instances de la fonction (souvent à l'aide d'une pile d'appels , bien que d'autres méthodes puissent être utilisées). Toute fonction récursive peut être transformée en une fonction itérative en remplaçant les appels récursifs par des constructions de contrôle itératives et en simulant la pile d'appels par une pile gérée explicitement par le programme.
Inversement, toutes les fonctions et procédures itératives évaluables par ordinateur (voir la complétude de Turing ) peuvent être exprimées sous forme de fonctions récursives ; les structures de contrôle itératives telles que les boucles `while` et `for` sont couramment réécrites sous forme récursive dans les langages fonctionnels . Cependant, en pratique, cette réécriture dépend de l’élimination des appels terminaux , une fonctionnalité absente de tous les langages. C , Java et Python sont des exemples de langages courants où tout appel de fonction, y compris les appels terminaux , peut entraîner une allocation de mémoire sur la pile, contrairement à l’utilisation de boucles. Dans ces langages, un programme itératif fonctionnel réécrit sous forme récursive peut provoquer un débordement de la pile d’appels , bien que l’élimination des appels terminaux ne soit pas toujours prise en charge par la spécification du langage, et que différentes implémentations d’un même langage puissent présenter des capacités d’élimination des appels terminaux différentes.
Problèmes de performance
Dans les langages (tels que C et Java ) qui privilégient les constructions de boucles itératives, les programmes récursifs engendrent généralement un coût important en temps et en espace, en raison de la surcharge nécessaire à la gestion de la pile et de la relative lenteur des appels de fonction ; dans les langages fonctionnels , un appel de fonction (en particulier un appel terminal ) est généralement une opération très rapide, et la différence est généralement moins perceptible.
À titre d'exemple concret, la différence de performance entre les implémentations récursive et itérative de l'exemple de la factorielle ci-dessus dépend fortement du compilateur utilisé. Dans les langages où les boucles sont privilégiées, la version itérative peut être plusieurs ordres de grandeur plus rapide que la version récursive. Dans les langages fonctionnels, la différence de temps d'exécution globale entre les deux implémentations peut être négligeable ; en effet, le coût de la multiplication des plus grands nombres avant les plus petits (ce que fait la version itérative présentée ici) peut largement compenser le gain de temps obtenu grâce à l'itération.
Espace de stockage
Dans certains langages de programmation, la taille maximale de la pile d'appels est bien inférieure à l'espace disponible dans le tas , et les algorithmes récursifs ont tendance à nécessiter plus d'espace de pile que les algorithmes itératifs. Par conséquent, ces langages limitent parfois la profondeur de récursion pour éviter les débordements de pile ; Python est un exemple de tel langage. Notez la mise en garde ci-dessous concernant le cas particulier de la récursion terminale .
Vulnérabilité
Les algorithmes récursifs étant sujets à des débordements de pile, ils peuvent être vulnérables aux entrées pathologiques ou malveillantes . Certains logiciels malveillants ciblent spécifiquement la pile d'appels d'un programme et exploitent sa nature intrinsèquement récursive. Même en l'absence de logiciel malveillant, un débordement de pile causé par une récursion non bornée peut être fatal au programme, et la logique de gestion des exceptions peut ne pas empêcher l'arrêt du processus correspondant .
Multiplier les problèmes récursifs
Les problèmes multirécursifs sont intrinsèquement récursifs, car ils nécessitent la gestion d'un état antérieur. Le parcours d'arbres, comme dans la recherche en profondeur, en est un exemple ; bien que des méthodes récursives et itératives soient utilisées elles contrastent avec le parcours de listes et la recherche linéaire dans une liste, qui constituent une méthode simplement récursive et donc naturellement itérative. Parmi les autres exemples, on peut citer les algorithmes de type « diviser pour régner » , tels que le tri rapide , et des fonctions comme la fonction d'Ackermann . Tous ces algorithmes peuvent être implémentés de manière itérative à l'aide d'une pile explicite , mais l'effort de programmation requis pour la gestion de la pile, ainsi que la complexité du programme résultant, surpassent sans doute les avantages de la solution itérative.
Refactorisation de la récursivité
Les algorithmes récursifs peuvent être remplacés par des versions non récursives. Une méthode de remplacement consiste à simuler les algorithmes récursifs en utilisant la mémoire du tas plutôt que la mémoire de la pile . Une autre solution consiste à développer un algorithme de remplacement entièrement basé sur des méthodes non récursives, ce qui peut s'avérer complexe. Par exemple, les algorithmes récursifs de recherche de caractères génériques , tels que l'algorithme wildmat de Rich Salz , étaient autrefois courants. Des algorithmes non récursifs, comme l' algorithme de Krauss pour la recherche de caractères génériques , ont été développés pour pallier les inconvénients de la récursivité et n'ont progressé que graduellement, grâce à des techniques telles que la collecte de tests et l'analyse des performances.
fonctions récursives terminales
Les fonctions récursives terminales sont des fonctions dont tous les appels récursifs sont des appels terminaux et n'accumulent donc aucune opération différée. Par exemple, la fonction pgcd (représentée ci-dessous) est récursive terminale. En revanche, la fonction factorielle (également ci-dessous) ne l'est pas ; son appel récursif n'étant pas terminal, elle accumule des multiplications différées qui doivent être effectuées après la fin du dernier appel récursif. Avec un compilateur ou un interpréteur qui traite les appels récursifs terminaux comme des sauts plutôt que comme des appels de fonction, une fonction récursive terminale telle que pgcd s'exécutera en utilisant un espace mémoire constant. Le programme est donc essentiellement itératif, ce qui équivaut à l'utilisation de structures de contrôle de langage impératif comme les boucles « for » et « while ».
| Récursivité terminale : | Augmenter la récursivité : | ||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
= y >= 0 * @returns the GCD of x and y */ int gcd(int x, int y) { if (y == 0) { return x; } else { return gcd(y, x % y); } } " /** * @brief Calcule le PGCD à l'aide de l'algorithme d'Euclide * @param x un entier * @param y un entier tel que x >= y >= 0 * @returns le PGCD de x et y */ int gcd ( int x , int y ) { if ( y == 0 ) { return x ; } else { return gcd ( y , x % y ); } } | pile d'appels ; lorsque l'appel récursif se termine, il reprend directement à la position de retour précédemment sauvegardée. Par conséquent, dans les langages qui reconnaissent cette propriété des appels terminaux, la récursivité terminale permet de gagner de l'espace et du temps. Ordre d'exécutionConsidérons ces deux fonctions : Fonction 1" , num ); if ( num < 4 ) { fonction récursive ( num + 1 ); } }
Fonction 2" , num ); }
Le résultat de la fonction 2 est celui de la fonction 1 avec les lignes inversées. Lorsqu'une fonction s'appelle elle-même une seule fois, les instructions placées avant l'appel récursif sont exécutées une fois par récursion, avant toute instruction placée après l'appel récursif. Ces dernières sont exécutées de manière répétée une fois le nombre maximal de récursions atteint. Notez également que l' ordre des instructions d'impression est inversé, ce qui est dû à la manière dont les fonctions et les instructions sont stockées sur la pile d'appels . Procédures récursivesFactorielleUn exemple classique de procédure récursive est la fonction utilisée pour calculer la factorielle d'un nombre naturel :
La fonction peut également être écrite sous forme de relation de récurrence : Cette évaluation de la relation de récurrence illustre le calcul qui serait effectué pour évaluer le pseudocode ci-dessus :
Cette fonction factorielle peut également être décrite sans utiliser la récursivité en utilisant les constructions de boucle typiques des langages de programmation impératifs :
Le code impératif ci-dessus est équivalent à cette définition mathématique utilisant une variable accumulateur 0\\\end{cases}}\end{aligned La définition ci-dessus se traduit directement dans les langages de programmation fonctionnelle tels que Scheme ; il s'agit d'un exemple d'itération implémentée de manière récursive. Plus grand commun diviseurL' algorithme d'Euclide , qui calcule le plus grand commun diviseur de deux entiers, peut être écrit de manière récursive. Définition de la fonction :
Relation de récurrence pour le plus grand commun diviseur, où exprime le reste de :
Le programme récursif ci-dessus est récursif terminal ; il est équivalent à un algorithme itératif, et le calcul présenté illustre les étapes d'évaluation qui seraient effectuées par un langage éliminant les appels terminaux. Ci-dessous figure une version du même algorithme utilisant une itération explicite, adaptée à un langage ne supprimant pas les appels terminaux. En stockant son état exclusivement dans les variables x et y et en utilisant une boucle, le programme évite les appels récursifs et l'augmentation de la pile d'appels.
L'algorithme itératif nécessite une variable temporaire, et même en connaissant l'algorithme d'Euclide, il est plus difficile de comprendre le processus par simple inspection, bien que les deux algorithmes soient très similaires dans leurs étapes. Tours de Hanoï Relation de récurrence pour Hanoi :
Exemples d'implémentation :
Bien que toutes les fonctions récursives n'aient pas de solution explicite, la suite des tours de Hanoï peut être réduite à une formule explicite.
Recherche binaireL' algorithme de recherche dichotomique est une méthode de recherche d' un élément unique dans un tableau trié . À chaque itération, le tableau est divisé en deux. Le principe consiste à choisir un point médian proche du centre du tableau, à comparer la valeur à ce point avec la valeur recherchée, puis à déterminer si la valeur recherchée est présente au milieu du tableau, si sa valeur est supérieure à la valeur recherchée, ou si sa valeur est inférieure à la valeur recherchée. La récursivité est utilisée dans cet algorithme car, à chaque itération, un nouveau tableau est créé en divisant l'ancien en deux. La procédure de recherche binaire est ensuite appelée récursivement sur ce nouveau tableau (plus petit). Généralement, la taille du tableau est ajustée en modifiant les indices de début et de fin. L'algorithme présente une complexité logarithmique car il divise le domaine du problème en deux à chaque itération. Exemple d'implémentation de la recherche binaire en C : end) { return -1; // Stop condition (base case) } else if (data[mid] == target) { return mid; // Found, return index } else if (data[mid] > target) { // Data is greater than target, search lower half return binary_search(data, target, start, mid - 1); } else { // Data is less than target, search upper half return binary_search(data, target, mid + 1, end); } } " /** * @brief Appelle la fonction binary_search avec les conditions initiales appropriées. * @param data un tableau d'entiers TRIÉ par ordre CROISSANT * @param target l'entier à rechercher * @param count le nombre total d'éléments dans le tableau * @returns le résultat de binary_search */ int search ( int data [], int target , int count ) { // Start = 0 (indice de début) // End = count - 1 (indice de fin) return binary_search ( data , target , 0 , count - 1 ); }/** * @brief Algorithme de recherche binaire. * @param data un tableau d'entiers TRIÉ par ordre CROISSANT * @param target l'entier à rechercher * @param start l'indice minimum du tableau * @param end l'indice maximum du tableau * @returns la position de l'entier à rechercher dans le tableau data, -1 s'il n'est pas trouvé */ int binary_search ( int data [], int target , int start , int end ) { //Obtenir le milieu. int mid = start + ( end - start ) / 2 ; //Division entièreif ( start > end ) { return -1 ; // Condition d'arrêt (cas de base) } else if ( data [ mid ] == target ) { return mid ; // Trouvé, retourner l'index } else if ( data [ mid ] > target ) { // Les données sont supérieures à la cible, rechercher dans la moitié inférieure return binary_search ( data , target , start , mid - 1 ); } else { // Les données sont inférieures à la cible, rechercher dans la moitié supérieure return binary_search ( data , target , mid + 1 , end ); } } Structures de données récursives (récursivité structurelle)
Les exemples de cette section illustrent ce que l'on appelle la « récursivité structurelle ». Ce terme fait référence au fait que les procédures récursives agissent sur des données définies de manière récursive.
Listes chaînéesArbres binairesL'exemple ci-dessus illustre un parcours infixe d'un arbre binaire. Un arbre binaire de recherche est un cas particulier d'arbre binaire où les éléments de données de chaque nœud sont ordonnés. traversée du système de fichiersÉtant donné que le nombre de fichiers dans un système de fichiers peut varier, la récursivité est la seule méthode pratique pour le parcourir et ainsi énumérer son contenu. Le parcours d'un système de fichiers est très similaire au parcours d'un arbre ; par conséquent, les concepts sous-jacents au parcours d'un arbre sont applicables au parcours d'un système de fichiers. Plus précisément, le code ci-dessous illustre un parcours préfixe d'un système de fichiers. l'itération : les fichiers et les répertoires sont parcourus, et chaque répertoire est ouvert de manière récursive. La méthode « rtraverse » est un exemple de récursivité directe, tandis que la méthode « traversée » est une fonction enveloppe. Le scénario de base est qu'il y aura toujours un nombre fixe de fichiers et/ou de répertoires dans un système de fichiers donné. Efficacité temporelle des algorithmes récursifsL' efficacité temporelle des algorithmes récursifs peut être exprimée par une relation de récurrence en notation grand O. Elle peut alors (généralement) être simplifiée en un seul terme grand O. Règle simplifiée (théorème maître) |


 0\\\end{cases
0\\\end{cases  0\\\end{cases
0\\\end{cases  0
0