Le cache du processeur est un cache matériel utilisé par l' unité centrale de traitement (CPU) d'un ordinateur pour réduire le coût moyen (temps ou énergie) d'accès aux données de la mémoire principale . Le cache est une mémoire plus petite et plus rapide, située plus près du cœur du processeur , qui stocke des copies des données provenant d' emplacements fréquemment utilisés de la mémoire principale , évitant ainsi d'avoir à toujours accéder à la mémoire principale, dont l'accès peut être des dizaines, voire des centaines de fois plus lent.
La mémoire cache est généralement implémentée avec de la mémoire vive statique (SRAM), qui nécessite plusieurs transistors pour stocker un seul bit . De ce fait, elle est coûteuse en termes d'espace occupé, et dans les processeurs modernes, le cache représente généralement la plus grande partie de la surface de la puce. La taille du cache doit être optimisée en tenant compte de la volonté de réduire la taille des puces et donc leur coût. Certaines conceptions modernes utilisent tout ou partie de leur cache avec de la mémoire eDRAM , physiquement plus compacte, plus lente que la SRAM, mais permettant une plus grande capacité de cache pour une surface de puce donnée.
La plupart des processeurs possèdent une hiérarchie de plusieurs niveaux de cache (L1, L2, souvent L3 et plus rarement L4), avec des caches distincts pour les instructions (cache d'instructions) et les données (cache de données) au niveau 1. Les différents niveaux sont implémentés dans différentes zones de la puce ; le cache L1 est situé au plus près d'un cœur du processeur et offre ainsi la vitesse la plus élevée grâce à des trajets de signaux courts, mais sa conception exige une grande précision. Les caches L2 sont physiquement séparés du processeur et fonctionnent plus lentement, mais ils sont moins contraignants pour le concepteur de la puce et peuvent être beaucoup plus grands sans impacter la conception du processeur. Les caches L3 sont généralement partagés entre plusieurs cœurs du processeur.
Il existe d'autres types de caches (qui ne sont pas pris en compte dans le calcul de la « taille du cache » des caches les plus importants mentionnés ci-dessus), comme le tampon de traduction d'adresses (TLB), qui fait partie de l' unité de gestion de la mémoire (MMU) présente dans la plupart des processeurs. Les sections d'entrée/sortie contiennent également souvent des tampons de données qui remplissent une fonction similaire.
mémoire principale , un processus en plusieurs étapes est utilisé, chacune introduisant un délai. Par exemple, pour lire une valeur en mémoire dans un système informatique simple, le processeur sélectionne d'abord l'adresse à accéder en l'exprimant sur le bus d'adresses et attend un temps fixe pour permettre à la valeur de se stabiliser. Le dispositif de mémoire contenant cette valeur, généralement de la DRAM , stocke cette valeur sous une forme à très faible consommation d'énergie, insuffisante pour être lue directement par le processeur. Ce dernier doit donc copier la valeur depuis le stockage vers un petit tampon connecté au bus de données . Il attend ensuite un certain temps pour permettre à cette valeur de se stabiliser avant de la lire sur le bus de données.En rapprochant physiquement la mémoire du processeur, on réduit le temps de stabilisation des bus. De plus, le remplacement de la DRAM par de la SRAM, qui stocke les valeurs sous une forme ne nécessitant pas d'amplification pour la lecture, élimine le délai interne à la mémoire. Le cache est ainsi beaucoup plus rapide, tant en lecture qu'en écriture. Cependant, la SRAM requiert entre quatre et six transistors par bit, selon son type, tandis que la DRAM utilise généralement un transistor et un condensateur par bit, ce qui lui permet de stocker une quantité de données bien supérieure sur une même surface de puce.
L'utilisation d'un format de mémoire plus rapide peut considérablement améliorer les performances. Lors d'une opération de lecture ou d'écriture en mémoire, le processeur vérifie si les données correspondantes sont déjà présentes dans le cache. Si c'est le cas, il privilégiera le cache à la mémoire principale, beaucoup plus lente.
De nombreux processeurs modernes pour ordinateurs de bureau , serveurs et applications industrielles possèdent au moins trois niveaux de cache indépendants (L1, L2 et L3) et différents types de cache :
- Tampon de recherche de traduction (TLB)
- Utilisé pour accélérer la traduction des adresses virtuelles en adresses physiques pour les instructions exécutables et les données. Un seul TLB peut être utilisé pour accéder aux instructions et aux données, ou bien un TLB d'instructions (ITLB) et un TLB de données (DTLB) distincts peuvent être utilisés. Cependant, le cache TLB fait partie de l' unité de gestion de la mémoire (MMU) et n'est pas directement lié aux caches du processeur.
- Cache d'instructions (I-cache)
- Utilisé pour accélérer la récupération des instructions exécutables ; certaines versions spécialisées incluent des caches de micro-opérations et des caches d’instructions cibles de branchement .
- Cache de données (D-cache)
- Utilisé pour accélérer la récupération et le stockage des données.
- Caches de niveau supérieur
- Les caches situés au-dessus du cache d'instructions et du cache de données sont généralement organisés sous forme de hiérarchie de niveaux de cache supplémentaires (L2, L3, etc.) ; voir également les caches multiniveaux ci-dessous.
Histoire

Parmi les premiers exemples de caches pour processeurs, on peut citer l' Atlas 2 et l' IBM System/360 modèle 85 dans les années 1960. Les premiers processeurs utilisant un cache ne disposaient que d'un seul niveau de cache ; contrairement aux caches de niveau 1 ultérieurs, celui-ci n'était pas divisé en L1d (pour les données) et L1i (pour les instructions). Le cache L1 divisé a fait son apparition en 1976 avec le processeur IBM 801 s'est généralisé à la fin des années 1980 et a fait son entrée sur le marché des processeurs embarqués en 1997 avec l'ARMv5TE. En 2015, même les SoC à moins d' un dollar utilisaient un cache L1 divisé. Ils disposaient également de caches L2 et, pour les processeurs plus puissants, de caches L3. Le cache L2 n'était généralement pas divisé et servait de stockage commun pour le cache L1 déjà divisé. Chaque cœur d'un processeur multicœur possédait un cache L1 dédié, généralement non partagé entre les cœurs. Le cache L2, ainsi que les caches de niveau inférieur, peuvent être partagés entre les cœurs. Le cache L4 est actuellement peu courant et est généralement constitué de mémoire vive dynamique (DRAM) sur une puce distincte, plutôt que de mémoire vive statique (SRAM). Une exception est l'utilisation de l'eDRAM pour tous les niveaux de cache, jusqu'au niveau L1. Historiquement, le cache L1 était également sur une puce distincte ; cependant, l'augmentation de la taille des puces a permis son intégration, ainsi que celle des autres niveaux de cache, à l'exception possible du dernier niveau. Chaque niveau de cache supplémentaire tend à être plus petit et plus rapide que les niveaux inférieurs.
Les caches (comme la RAM par le passé) ont généralement été dimensionnés selon des puissances de 2, 4, 8, 16, etc. KiB . Dès l'apparition des caches de l'ordre du Mio (c'est-à-dire pour les caches non-L1 plus volumineux), ce modèle a rapidement évolué, permettant ainsi des caches plus importants sans être contraints de doubler leur taille. On peut citer l'exemple du processeur Intel Core 2 Duo doté d'un cache L2 de 3 Mio en avril 2008. Ce phénomène s'est produit beaucoup plus tard pour les caches L1, dont la taille reste généralement faible (en KiB). L' IBM zEC12 de 2012 constitue toutefois une exception, avec un cache de données L1 exceptionnellement important de 96 KiB pour l'époque. On peut également citer l' IBM z13, équipé d'un cache d'instructions L1 de 96 KiB (et d' un cache de données L1 de 128 KiB) , et les processeurs Intel Ice Lake de 2018, disposant chacun d'un cache de données L1 de 48 KiB. En 2020, certains processeurs Intel Atom (jusqu'à 24 cœurs) disposaient de tailles de cache (multiples de) 4,5 Mio et 15 Mio.
Opération
Least Recently Used ), remplace l'entrée la moins récemment consultée.Le fait de marquer certaines plages mémoire comme non mises en cache peut améliorer les performances en évitant la mise en cache de régions mémoire rarement réutilisées. Cela évite la surcharge liée au chargement de données dans le cache sans réutilisation. Les entrées du cache peuvent également être désactivées ou verrouillées selon le contexte.
Rédiger des politiques
à écriture immédiate , chaque écriture dans le cache entraîne une écriture en mémoire principale. En revanche, dans un cache à écriture différée (ou cache de copie), les écritures ne sont pas immédiatement répliquées en mémoire principale ; les emplacements écrasés sont marqués comme modifiés et ne sont réécrits en mémoire principale que lorsqu'ils sont supprimés du cache. C'est pourquoi un défaut de lecture dans un cache à écriture différée peut parfois nécessiter deux accès mémoire : un premier pour écrire l'emplacement modifié en mémoire principale, puis un second pour lire le nouvel emplacement en mémoire. De plus, une écriture dans un emplacement mémoire principale qui n'est pas encore mappé dans un cache à écriture différée peut supprimer un emplacement déjà modifié, libérant ainsi cet espace de cache pour le nouvel emplacement mémoire.Il existe également des politiques intermédiaires. Le cache peut être en écriture immédiate, mais les écritures peuvent être temporairement stockées dans une file d'attente de données, généralement pour permettre le traitement simultané de plusieurs opérations (ce qui peut réduire les temps d'attente sur le bus et améliorer son utilisation).
Les données mises en cache en mémoire principale peuvent être modifiées par d'autres entités (par exemple, des périphériques utilisant l'accès direct à la mémoire (DMA) ou un autre cœur d'un processeur multicœur ), auquel cas la copie dans le cache peut devenir obsolète. Inversement, lorsqu'un processeur d'un système multiprocesseur met à jour des données dans le cache, les copies de ces données dans les caches associés aux autres processeurs deviennent obsolètes. Les protocoles de communication entre les gestionnaires de cache qui assurent la cohérence des données sont appelés protocoles de cohérence de cache .
performances du cache
La mesure des performances du cache est devenue cruciale ces derniers temps, l'écart de vitesse entre la mémoire et le processeur augmentant de façon exponentielle. Le cache a été introduit pour réduire cet écart. Il est donc important de savoir dans quelle mesure il parvient à combler cet écart, notamment dans les systèmes hautes performances. Le taux de succès et le taux d'échec du cache jouent un rôle déterminant dans ces performances. Pour améliorer le cache, la réduction du taux d'échec est une étape essentielle parmi d'autres. Diminuer le temps d'accès au cache contribue également à améliorer ses performances et facilite son optimisation.
blocages du processeur
Le temps nécessaire pour accéder à une ligne de cache en mémoire ( latence due à un défaut de cache) est important car le processeur ne pourra plus effectuer de tâches pendant l'attente. Lorsqu'il atteint cet état, on parle de blocage. À mesure que les processeurs deviennent plus rapides que la mémoire vive, les blocages dus aux défauts de cache réduisent considérablement le potentiel de calcul ; les processeurs modernes peuvent exécuter des centaines d'instructions pendant le temps nécessaire pour accéder à une seule ligne de cache en mémoire vive.
Diverses techniques ont été employées pour maintenir le processeur occupé pendant ce temps, notamment l'exécution hors séquence, où le processeur tente d'exécuter des instructions indépendantes après l'instruction en attente de données manquantes dans le cache. Une autre technologie, utilisée par de nombreux processeurs, est le multithreading simultané (SMT), qui permet à un thread alternatif d'utiliser le cœur du processeur pendant que le premier thread attend que les ressources nécessaires soient disponibles.
Associativité
Illustration des différentes manières dont les emplacements mémoire peuvent être mis en cache par des emplacements de cache particuliers La politique de placement détermine l'emplacement, dans le cache, de la copie d'une entrée particulière de la mémoire principale. Si cette politique peut choisir librement n'importe quel emplacement du cache, celui-ci est dit entièrement associatif . À l'inverse, si chaque entrée de la mémoire principale ne peut être placée qu'à un seul emplacement dans le cache, celui-ci est dit à correspondance directe . De nombreux caches adoptent un compromis : chaque entrée de la mémoire principale peut être placée à l'un des N emplacements possibles dans le cache ; on les qualifie alors de caches associatifs à N voies. Par exemple, le cache de données de niveau 1 d'un processeur AMD Athlon est associatif à deux voies, ce qui signifie que toute adresse mémoire peut être placée à l'un ou l'autre des deux emplacements possibles dans le cache de données de niveau 1.
Choisir la valeur optimale d'associativité implique un compromis . Si la politique de placement peut associer une adresse mémoire à dix emplacements, il faut parcourir ces dix entrées de cache pour vérifier sa présence dans le cache. Vérifier davantage d'emplacements consomme plus d'énergie et occupe plus de surface sur la puce, ce qui peut allonger le temps de lecture. En revanche, les caches à forte associativité subissent moins de défauts de cache (voir les défauts de conflit ), ce qui réduit le temps perdu par le processeur à lire la mémoire principale, plus lente. En règle générale, doubler l'associativité, en passant d'un mappage direct à un mappage à deux voies, ou de deux voies à quatre voies, a un impact similaire sur le taux d'accès réussi à celui obtenu en doublant la taille du cache. Cependant, augmenter l'associativité au-delà de quatre n'améliore pas autant le taux d'accès réussi et est généralement effectué pour d'autres raisons (voir l'aliasing virtuel ). Certains processeurs peuvent réduire dynamiquement l'associativité de leurs caches en mode basse consommation, ce qui permet de réaliser des économies d'énergie
Du plus simple mais le moins bon au plus complexe mais le meilleur :
- Cache à mappage direct – bon temps dans le meilleur des cas, mais imprévisible dans le pire des casLRU est particulièrement simple puisqu'un seul bit doit être stocké pour chaque paire.
Exécution spéculative
L'un des avantages d'un cache à correspondance directe est qu'il permet une recherche simple et rapide . Une fois l'adresse calculée, l'index du cache susceptible de contenir une copie de cet emplacement en mémoire est connu. Cette entrée de cache peut être lue, et le processeur peut poursuivre le traitement des données avant même d'avoir vérifié que l'étiquette correspond bien à l'adresse demandée.
L'idée d'utiliser les données mises en cache par le processeur avant même que la correspondance avec l'étiquette ne soit terminée s'applique également aux caches associatifs. Un sous-ensemble de l'étiquette, appelé indice , permet de sélectionner une seule entrée du cache correspondant à l'adresse demandée. Cette entrée sélectionnée peut ensuite être utilisée en parallèle avec la vérification de l'étiquette complète. Cette technique d'indice est particulièrement efficace dans le cadre de la traduction d'adresses, comme expliqué ci-dessous.
Cache associatif à double biais
D'autres schémas ont été proposés, comme le cache asymétrique où l'index de la voie 0 est direct, comme précédemment, tandis que celui de la voie 1 est généré par une fonction de hachage . Une bonne fonction de hachage a la propriété que les adresses en conflit avec le mappage direct tendent à ne plus l'être lorsqu'elles sont mappées avec la fonction de hachage. Ainsi, un programme est moins susceptible de subir un nombre anormalement élevé d'échecs de lecture dus à un schéma d'accès pathologique. L'inconvénient est la latence supplémentaire liée au calcul de la fonction de hachage . De plus, lors du chargement d'une nouvelle ligne et de la suppression d'une ancienne, il peut être difficile de déterminer quelle ligne existante a été la moins récemment utilisée, car la nouvelle ligne entre en conflit avec des données à différents index dans chaque voie ; le suivi LRU pour les caches non asymétriques est généralement effectué par ensemble. Néanmoins, les caches associatifs asymétriques présentent des avantages majeurs par rapport aux caches associatifs par ensembles classiques
Cache pseudo-associatif
Un cache associatif véritable teste simultanément toutes les possibilités, à l'aide d'un système de mémoire adressable par contenu (CASM) . Un cache pseudo-associatif teste chaque possibilité une à une. Le cache par hachage-rehachage et le cache associatif par colonnes sont des exemples de caches pseudo-associatifs.
Dans le cas courant de la découverte d'une correspondance de la première manière testée, un cache pseudo-associatif est aussi rapide qu'un cache à correspondance directe, mais il a un taux d'échec de conflit beaucoup plus faible qu'un cache à correspondance directe, plus proche du taux d'échec d'un cache entièrement associatif.
Cache multicolonne
Comparativement à un cache à correspondance directe, un cache associatif par ensembles utilise un nombre réduit de bits pour son index d'ensemble, qui correspond à un ensemble de cache contenant plusieurs voies ou blocs : par exemple, 2 blocs pour un cache associatif par ensembles à 2 voies et 4 blocs pour un cache associatif par ensembles à 4 voies. Les bits d'index non utilisés sont intégrés aux bits d'étiquette. Ainsi, un cache associatif par ensembles à 2 voies contribue 1 bit à l'étiquette, tandis qu'un cache associatif par ensembles à 4 voies y contribue 2 bits. Le principe du cache multicolonne est d'utiliser l'index d'ensemble pour associer un élément à un ensemble de cache, comme pour un cache associatif par ensembles classique, et d'utiliser les bits d'étiquette supplémentaires pour indexer une voie au sein de cet ensemble. Par exemple, dans un cache associatif par ensembles à 4 voies, les deux bits supplémentaires servent à indexer respectivement les voies 00, 01, 10 et 11. Ce double indexage de cache est appelé « mappage d'emplacement principal » et sa latence est équivalente à celle d'un accès direct. De nombreuses expériences sur la conception de caches multicolonnes montrent que le taux d'accès aux emplacements principaux atteint 90 %. Si un mappage de cache entre en conflit avec un bloc de cache situé à l'emplacement principal, ce bloc est déplacé vers un autre chemin de cache du même ensemble, appelé « emplacement sélectionné ». Le bloc nouvellement indexé étant le bloc le plus récemment utilisé (MRU), il est placé à l'emplacement principal du cache multicolonne en tenant compte de la localité temporelle. Le cache multicolonne étant conçu pour une forte associativité, le nombre de chemins dans chaque ensemble est élevé ; il est donc facile de trouver un emplacement sélectionné. Un index d'emplacement sélectionné est maintenu par un matériel supplémentaire pour l'emplacement principal d'un bloc de cache.expliqués ci-dessous .
La « taille » du cache correspond à la quantité de données de la mémoire principale qu'il peut contenir. Cette taille se calcule en multipliant le nombre d'octets stockés dans chaque bloc de données par le nombre de blocs stockés dans le cache. (Les bits d'étiquette, d'indicateur et de code de correction d'erreurs ne sont pas inclus dans la taille , bien qu'ils influent sur la surface physique du cache.)
Une adresse mémoire effective associée à la ligne de cache (bloc mémoire) est divisée ( MSB vers LSB ) en étiquette, index et décalage de bloc.
étiqueter indice décalage de bloc
L'index décrit le cache dans lequel les données ont été placées. Sa longueur est de bits pour
Le processeur Pentium 4 d'origine disposait également d'un cache L2 intégré associatif à huit voies de 256 Kio, avec des blocs de cache de 128 octets. Cela implique 32 − 8 − 7 = 17 bits pour le champ d'étiquette.
d'écoute de bus multi-maître du cache d'un processeur détecte une diffusion d'adresse provenant d'un autre processeur et constate que certains blocs de données du cache local sont désormais obsolètes et doivent être marqués comme invalides.Un cache de données nécessite généralement deux bits d'indicateur par ligne de cache : un bit de validité et un bit de modification . Lorsque le bit de modification est activé, cela signifie que la ligne de cache associée a été modifiée depuis sa lecture en mémoire principale (« modifiée »), c'est-à-dire que le processeur a écrit des données sur cette ligne et que la nouvelle valeur n'a pas encore été propagée jusqu'à la mémoire principale.
thread d'exécution , doit attendre (se bloquer) que l'instruction soit récupérée de la mémoire principale. Les défauts de lecture dans le cache de données entraînent généralement un délai plus court, car les instructions non dépendantes de la lecture peuvent être exécutées et poursuivre leur exécution jusqu'à ce que les données soient renvoyées par la mémoire principale, et les instructions dépendantes peuvent reprendre leur exécution. Les défauts d'écriture dans le cache de données entraînent généralement le délai le plus court, car l'écriture peut être mise en file d'attente et l'exécution des instructions suivantes est peu limitée ; le processeur peut continuer jusqu'à ce que la file d'attente soit pleine. Pour une présentation détaillée des types de défauts, consultez la section « Mesure et métriques des performances du cache » .mémoire virtuelle . En résumé, soit chaque programme exécuté sur la machine dispose de son propre espace d'adressage simplifié , contenant uniquement le code et les données de ce programme, soit tous les programmes s'exécutent dans un espace d'adressage virtuel commun. Un programme s'exécute en calculant, comparant, lisant et écrivant aux adresses de son espace d'adressage virtuel, plutôt qu'aux adresses de l'espace d'adressage physique, ce qui simplifie les programmes et facilite leur écriture.La mémoire virtuelle nécessite que le processeur traduise les adresses virtuelles générées par le programme en adresses physiques dans la mémoire principale. La partie du processeur qui effectue cette traduction est appelée unité de gestion de la mémoire (MMU). Le chemin rapide à travers la MMU peut effectuer ces traductions stockées dans le tampon de traduction (TLB), qui est un cache de correspondances entre la table des pages , la table des segments, ou les deux, du système d'exploitation .
Dans le cadre de la présente discussion, la traduction d'adresses présente trois caractéristiques importantes :
- Latence : L'adresse physique est disponible auprès de l'unité de gestion de la mémoire (MMU) un certain temps, peut-être quelques cycles, après que l'adresse virtuelle soit disponible auprès du générateur d'adresses.
- Gio peut être divisé en 1 048 576 pages de 4 Kio, chacune pouvant être mappée indépendamment. Plusieurs tailles de page peuvent être prises en charge ; voir la documentation sur la mémoire virtuelle pour plus de détails.
Un des premiers systèmes de mémoire virtuelle, l' IBM M44/44X , nécessitait un accès à une table de correspondance stockée en mémoire centrale avant chaque accès programmé à la mémoire principale. En l'absence de cache, et la mémoire de la table de correspondance fonctionnant à la même vitesse que la mémoire principale, la vitesse d'accès à la mémoire était ainsi réduite de moitié. Deux machines anciennes utilisant une table des pages en mémoire principale pour la correspondance, l' IBM System/360 Modèle 67 et le GE 645 , disposaient toutes deux d'une petite mémoire associative servant de cache pour les accès à la table des pages en mémoire. Ces deux machines sont antérieures à la première machine dotée d'un cache pour la mémoire principale, l' IBM System/360 Modèle 85 ; le premier cache matériel utilisé dans un système informatique n'était donc pas un cache de données ou d'instructions, mais un TLB (Time-Level Block).
Les caches peuvent être divisés en quatre types, selon que l'index ou l'étiquette corresponde à des adresses physiques ou virtuelles :
- Les caches à indexation physique et étiquetage physique (PIPT) utilisent l'adresse physique à la fois pour l'index et l'étiquette. Bien que cette méthode soit simple et évite les problèmes d'aliasing, elle est également lente, car l'adresse physique doit être recherchée (ce qui peut entraîner un défaut de bloc de liste et un accès à la mémoire principale) avant que cette adresse puisse être recherchée dans le cache.
- Les caches VIVT ( Virtually Indexed, Virtually Tagged ) utilisent l'adresse virtuelle à la fois comme index et comme étiquette. Ce schéma de cache permet des recherches beaucoup plus rapides, car il n'est pas nécessaire de consulter l'unité de gestion de la mémoire (MMU) au préalable pour déterminer l'adresse physique correspondant à une adresse virtuelle donnée. Cependant, les caches VIVT souffrent de problèmes d'aliasing : plusieurs adresses virtuelles différentes peuvent désigner la même adresse physique. Ces adresses sont alors mises en cache séparément, bien qu'elles pointent vers la même zone mémoire, ce qui engendre des problèmes de cohérence. Bien que des solutions existent elles ne sont pas compatibles avec les protocoles de cohérence standard. Un autre problème est celui des homonymes : une même adresse virtuelle peut correspondre à plusieurs adresses physiques différentes. Il est impossible de distinguer ces correspondances en se basant uniquement sur l'index virtuel. Parmi les solutions potentielles, on peut citer : le vidage du cache après un changement de contexte , l'obligation d'utiliser des espaces d'adressage non chevauchants et l'attribution d'un identifiant d'espace d'adressage (ASID) à l'adresse virtuelle. De plus, le problème de la modification des correspondances entre adresses virtuelles et physiques nécessite la vidange du cache, car les adresses virtuelles ne sont plus valides. Ces problèmes disparaissent lorsque les étiquettes utilisent des adresses physiques (VIPT).
- Les caches à indexation virtuelle et étiquetage physique (VIPT) utilisent l'adresse virtuelle pour l'index et l'adresse physique dans l'étiquette. L'avantage par rapport aux caches PIPT réside dans une latence réduite, car la recherche dans le cache peut être effectuée en parallèle avec la traduction TLB. Cependant, l'étiquette ne peut être comparée que lorsque l'adresse physique est disponible. L'avantage par rapport aux caches VIVT est que, grâce à l'étiquette contenant l'adresse physique, le cache peut détecter les homonymes. Théoriquement, les caches VIPT nécessitent davantage de bits d'étiquette, car certains bits d'index peuvent différer entre les adresses virtuelle et physique (par exemple, les bits 12 et suivants pour les pages de 4 Kio) et devraient être inclus à la fois dans l'index virtuel et dans l'étiquette physique. En pratique, cela ne pose pas de problème car, afin d'éviter les problèmes de cohérence, les caches VIPT sont conçus sans ces bits d'index (par exemple, en limitant le nombre total de bits pour l'index et le décalage de bloc à 12 pour les pages de 4 Kio) ; la taille des caches VIPT est ainsi limitée à la taille de la page multipliée par l'associativité du cache.
- Les caches à indexation physique et étiquetage virtuel (PIVT) sont souvent considérés dans la littérature comme inutiles et inexistants . Pourtant, le MIPS R6000 utilise ce type de cache comme seule implémentation connue . Le R6000 est implémenté en logique à couplage d'émetteur , une technologie extrêmement rapide, mais inadaptée aux grandes mémoires telles qu'un TLB . Le R6000 résout ce problème en plaçant la mémoire TLB dans une partie réservée du cache de second niveau, dotée d'une minuscule « tranche » TLB haute vitesse intégrée. Le cache est indexé par l'adresse physique obtenue à partir de cette tranche TLB. Cependant, comme la tranche TLB ne traduit que les bits d'adresse virtuelle nécessaires à l'indexation du cache et n'utilise aucun étiquetage, des accès non autorisés au cache peuvent se produire. Ce problème est résolu par l'étiquetage avec l'adresse virtuelle.
La vitesse de cette récurrence (la latence de chargement ) est cruciale pour les performances du processeur, et c'est pourquoi la plupart des caches de niveau 1 modernes sont virtuellement indexés, ce qui permet au moins à la recherche TLB de l'unité de gestion de la mémoire (MMU) de se dérouler en parallèle avec la récupération des données de la mémoire RAM du cache.
Cependant, l'indexation virtuelle n'est pas optimale pour tous les niveaux de cache. Le coût de la gestion des alias virtuels augmente avec la taille du cache ; c'est pourquoi la plupart des caches de niveau 2 et plus sont indexés physiquement.
Historiquement, les caches utilisaient à la fois des adresses virtuelles et physiques pour leurs étiquettes, bien que l'étiquetage virtuel soit aujourd'hui rare. Si la recherche dans le TLB peut se terminer avant celle dans la RAM du cache, l'adresse physique est disponible à temps pour la comparaison des étiquettes, et l'étiquetage virtuel devient inutile. Les grands caches sont donc généralement étiquetés physiquement, tandis que seuls les petits caches à très faible latence utilisent l'étiquetage virtuel. Dans les processeurs généralistes récents, l'étiquetage virtuel a été remplacé par des indications virtuelles, comme décrit ci-dessous.
Problèmes d'homonymie et de synonymie
Un cache reposant sur l'indexation et l'étiquetage virtuels devient incohérent lorsqu'une même adresse virtuelle est associée à différentes adresses physiques ( homonymie ). Ce problème peut être résolu en utilisant l'adresse physique pour l'étiquetage, ou en stockant l'identifiant de l'espace d'adressage dans la ligne de cache. Cependant, cette dernière approche ne résout pas le problème des synonymes , où plusieurs lignes de cache finissent par stocker des données pour la même adresse physique. L'écriture à ces emplacements peut ne mettre à jour qu'un seul emplacement dans le cache, laissant les autres avec des données incohérentes. Ce problème peut être résolu en utilisant des dispositions mémoire non chevauchantes pour différents espaces d'adressage, ou bien en vidant le cache (ou une partie de celui-ci) lors de tout changement d'association.
Étiquettes et indices virtuels
Le principal avantage des étiquettes virtuelles est que, pour les caches associatifs, elles permettent d'effectuer la correspondance des étiquettes avant la traduction virtuelle-physique. Cependant, les sondages de cohérence et les évictions fournissent une adresse physique pour l'action. Le matériel doit disposer d'un moyen de convertir les adresses physiques en un index de cache, généralement en stockant à la fois les étiquettes physiques et virtuelles. Par comparaison, un cache à étiquettes physiques n'a pas besoin de conserver d'étiquettes virtuelles, ce qui est plus simple. Lorsqu'une correspondance virtuelle-physique est supprimée du TLB, les entrées de cache associées à ces adresses virtuelles doivent être vidées. De même, si des entrées de cache sont autorisées sur des pages non mappées par le TLB, ces entrées doivent être vidées lorsque les droits d'accès à ces pages sont modifiés dans la table des pages.
Le système d'exploitation peut également garantir qu'aucun alias virtuel ne réside simultanément dans le cache. Il assure cette garantie en appliquant la coloration des pages, décrite ci-dessous. Certains processeurs RISC anciens (SPARC, RS/6000) utilisaient cette approche. Elle n'est plus employée aujourd'hui, car le coût matériel de la détection et de la suppression des alias virtuels a diminué, tandis que la complexité logicielle et la perte de performance liées à une coloration parfaite des pages ont augmenté.
Il peut être utile de distinguer les deux fonctions des étiquettes dans un cache associatif : elles servent à déterminer le sens de sélection de l’ensemble d’entrées, et elles servent à déterminer si la recherche a réussi ou échoué. La seconde fonction doit toujours être correcte, mais la première peut occasionnellement faire des suppositions et donner une réponse erronée.
Certains processeurs (par exemple, les premiers SPARC) possèdent des caches à la fois virtuels et physiques. Les étiquettes virtuelles servent à la sélection du chemin d'accès, tandis que les étiquettes physiques déterminent si l'accès a réussi ou échoué. Ce type de cache bénéficie de la faible latence d'un cache à étiquettes virtuelles et de la simplicité d'interface logicielle d'un cache à étiquettes physiques. Il présente toutefois l'inconvénient supplémentaire des étiquettes dupliquées. De plus, lors du traitement d'un échec d'accès, les chemins d'accès alternatifs de la ligne de cache indexée doivent être analysés afin de détecter les alias virtuels et d'éliminer toute correspondance.
L'espace supplémentaire (et la latence accrue) peut être atténué en conservant des indications virtuelles pour chaque entrée de cache, au lieu d'étiquettes virtuelles. Ces indications sont un sous-ensemble ou un hachage de l'étiquette virtuelle et servent à sélectionner la zone de cache à partir de laquelle récupérer les données et une étiquette physique. Comme pour un cache à étiquettes virtuelles, il peut y avoir une correspondance entre une indication virtuelle et une différence d'étiquette physique. Dans ce cas, l'entrée de cache avec l'indication correspondante doit être supprimée afin que les accès au cache après son remplissage à cette adresse ne comportent qu'une seule correspondance d'indication. Étant donné que les indications virtuelles possèdent moins de bits de distinction que les étiquettes virtuelles, un cache utilisant des indications virtuelles subit davantage de défauts de cache liés à des conflits qu'un cache à étiquettes virtuelles.
La réduction ultime des indications virtuelles se trouve peut-être dans le Pentium 4 (cœurs Willamette et Northwood). Sur ces processeurs, l'indication virtuelle est réduite à deux bits et le cache est associatif par ensembles à quatre voies. Concrètement, le matériel maintient une simple permutation entre l'adresse virtuelle et l'index du cache, ce qui rend inutile l'utilisation de la mémoire associative (CAM) pour sélectionner la bonne adresse parmi les quatre voies d'accès.
Coloriage
l'optimisation des boucles imbriquées ), notamment dans le domaine du calcul haute performance (HPC) .Le problème, c'est que si toutes les pages utilisées à un instant donné peuvent avoir des couleurs virtuelles différentes, certaines peuvent avoir la même couleur physique. En fait, si le système d'exploitation attribue des pages physiques aux pages virtuelles de manière aléatoire et uniforme, il est fort probable que certaines pages aient la même couleur physique, et que les adresses de ces pages entrent alors en conflit dans le cache (c'est le paradoxe des anniversaires ).
La solution consiste à ce que le système d'exploitation tente d'attribuer des couleurs physiques différentes à des couleurs virtuelles différentes, une technique appelée coloration des pages . Bien que la correspondance exacte entre les couleurs virtuelles et physiques soit sans incidence sur les performances du système, les correspondances complexes sont difficiles à gérer et présentent peu d'avantages. C'est pourquoi la plupart des méthodes de coloration des pages visent simplement à conserver les mêmes couleurs physiques et virtuelles.
Si le système d'exploitation garantit que chaque page physique correspond à une seule couleur virtuelle, il n'y a pas d'alias virtuels et le processeur peut utiliser des caches indexés virtuellement sans avoir besoin de sondes d'alias virtuels supplémentaires lors de la gestion des défauts. Le système d'exploitation peut également vider le cache d'une page à chaque changement de couleur virtuelle. Comme indiqué précédemment, cette approche a été utilisée dans certaines architectures SPARC et RS/6000 de première génération.
La technique de coloration logicielle des pages a été utilisée pour partitionner efficacement le cache de dernier niveau (LLC) partagé dans les processeurs multicœurs. Cette gestion du LLC basée sur le système d'exploitation dans les processeurs multicœurs a été adoptée par Intel.
Hiérarchie de mémoire d'un serveur AMD Bulldozer Les processeurs modernes possèdent plusieurs caches sur puce interagissant entre eux. Le fonctionnement d'un cache particulier peut être entièrement spécifié par sa taille, la taille des blocs de cache, le nombre de blocs dans un ensemble, la politique de remplacement des ensembles de cache et la politique d'écriture du cache (écriture immédiate ou écriture différée).
Bien que tous les blocs d'un cache donné aient la même taille et la même associativité, les caches de « niveau supérieur » (appelés caches de niveau 1) possèdent généralement un nombre de blocs plus faible, une taille de bloc plus petite et un ensemble de blocs plus restreint, mais offrent des temps d'accès très courts. Les caches de « niveau inférieur » (c'est-à-dire de niveau 2 et inférieurs) possèdent un nombre de blocs progressivement plus important, une taille de bloc plus grande, un ensemble de blocs plus dense et des temps d'accès relativement plus longs, mais restent beaucoup plus rapides que la mémoire principale.
La politique de remplacement des entrées du cache est déterminée par un algorithme de cache choisi par les concepteurs du processeur. Dans certains cas, plusieurs algorithmes sont proposés pour différents types de charges de travail.
Caches spécialisées
Les processeurs pipelinés accèdent à la mémoire à partir de plusieurs points du pipeline : extraction des instructions, traduction d'adresses virtuelles en adresses physiques et extraction des données (voir le pipeline RISC classique ). Naturellement, on utilise des caches physiques différents pour chacun de ces points, afin qu'une même ressource physique ne soit pas affectée à deux points du pipeline. Le pipeline comporte ainsi naturellement au moins trois caches distincts (instructions, TLB et données), chacun spécialisé dans son rôle spécifique.
Cache de victimes
Norman Jouppi de DEC en 1990. La variante Crystalwell des processeurs Haswell d'Intel intégrait un cache eDRAM de niveau 4 de 128 Mio , servant de cache victime au cache de niveau 3 du processeur. Dans la microarchitecture Skylake, le cache de niveau 4 ne fonctionne plus comme cache victime.
Intel Pentium 4. Un cache de traces est un mécanisme permettant d'augmenter la bande passante de récupération des instructions et de diminuer la consommation d'énergie (dans le cas du Pentium 4) en stockant les traces des instructions qui ont déjà été récupérées et décodées. Un cache de traces stocke les instructions soit après leur décodage, soit au fur et à mesure de leur suppression. Généralement, les instructions sont ajoutées aux caches de traces par groupes représentant soit des blocs de base individuels , soit des traces d'instructions dynamiques. Le cache de traces du Pentium 4 stocke les micro-opérations résultant du décodage des instructions x86, offrant ainsi la fonctionnalité d'un cache de micro-opérations. Grâce à cela, la prochaine fois qu'une instruction sera nécessaire, il ne sera pas nécessaire de la décoder à nouveau en micro-opérations.
Cache de fusion d'écriture (WCC)
Le cache de coalescence d'écriture (WCC ) est un cache spécial faisant partie du cache L2 de la microarchitecture Bulldozer d' AMD . Les données écrites provenant des deux caches L1D du module transitent par le WCC, où elles sont mises en mémoire tampon et fusionnées. Le WCC a pour fonction de réduire le nombre d'écritures dans le cache L2.
les micro-opérations des instructions décodées, telles que reçues directement des décodeurs d'instructions ou du cache d'instructions. Lorsqu'une instruction doit être décodée, le cache μop vérifie si sa forme décodée s'y trouve ; si elle n'est pas disponible, l'instruction est décodée puis mise en cache.L'un des premiers travaux décrivant le cache μop comme une interface alternative pour la famille de processeurs Intel P6 est l'article de 2001 intitulé « Micro-Operation Cache: A Power Aware Frontend for Variable Instruction Length ISA » . Par la suite, Intel a intégré des caches μop dans ses processeurs Sandy Bridge et dans les microarchitectures successives telles qu'Ivy Bridge et Haswell : a implémenté un cache μop dans sa microarchitecture Zen .
L'accès à des instructions complètes pré-décodées élimine la nécessité de décoder à répétition des instructions complexes de longueur variable en micro-opérations plus simples de longueur fixe, et simplifie le processus de prédiction, d'accès, de rotation et d'alignement des instructions récupérées. Un cache de micro-opérations décharge efficacement le matériel d'accès et de décodage, réduisant ainsi la consommation d'énergie et améliorant la fourniture de micro-opérations décodées au processeur. Le cache de micro-opérations améliore également les performances en fournissant de manière plus constante les micro-opérations décodées au processeur et en éliminant divers goulots d'étranglement dans la logique d'accès et de décodage du processeur.
Un cache μop présente de nombreuses similitudes avec un cache de traces, mais il est beaucoup plus simple, ce qui lui confère une meilleure efficacité énergétique ; il est donc mieux adapté aux implémentations sur des appareils alimentés par batterie. Le principal inconvénient du cache de traces, à l’origine de son inefficacité énergétique, réside dans la complexité matérielle requise pour son heuristique de décision concernant la mise en cache et la réutilisation des traces d’instructions créées dynamiquement.
cache d'instructions de la cible de branchement
Un cache de cible de branchement , ou cache d'instructions de cible de branchement (nom utilisé sur les microprocesseurs ARM ) est un cache spécialisé qui stocke les premières instructions à l'adresse de destination d'un branchement. Il est utilisé par les processeurs basse consommation qui n'ont pas besoin d'un cache d'instructions classique, car leur système mémoire est capable de fournir les instructions suffisamment rapidement pour satisfaire le processeur. Cependant, cela ne s'applique qu'aux instructions consécutives ; le redémarrage de la récupération d'une instruction à une nouvelle adresse nécessite toujours plusieurs cycles de latence, ce qui provoque une brève oscillation du pipeline après un transfert de contrôle. Un cache de cible de branchement fournit les instructions pour ces quelques cycles, évitant ainsi un délai après la plupart des branchements.
Cela permet un fonctionnement à pleine vitesse avec un cache beaucoup plus petit qu'un cache d'instructions traditionnel à temps plein.
Cache intelligent
Le cache intelligent est une méthode de mise en cache de niveau 2 ou 3 pour plusieurs cœurs d'exécution, développée par Intel .
Le cache intelligent partage la mémoire cache entre les cœurs d'un processeur multicœur . Comparé à un cache dédié par cœur, le taux global d'échecs de cache diminue lorsque les cœurs n'ont pas besoin de parts égales de l'espace cache. Par conséquent, un seul cœur peut utiliser la totalité du cache de niveau 2 ou 3 tandis que les autres cœurs sont inactifs. De plus, le cache partagé accélère le partage de mémoire entre les différents cœurs d'exécution.
eDRAM et montés sur un module multi-puces , constituant ainsi un quatrième niveau de cache. Dans de rares cas, comme pour le processeur du mainframe IBM z15 (2019), tous les niveaux jusqu'au cache L1 sont implémentés en eDRAM, remplaçant entièrement la SRAM (pour le cache, la SRAM étant toujours utilisée pour les registres ). La gamme de processeurs Apple Silicon , basée sur l'architecture ARM et comprenant les A14 et M1 , dispose d'un cache L1i de 192 Kio pour chacun des cœurs hautes performances, une capacité exceptionnellement élevée ; en revanche, les cœurs basse consommation ne disposent que de 128 Kio. Depuis, d'autres processeurs tels que Lunar Lake d' Intel et Oryon de Qualcomm ont également implémenté des tailles de cache L1i similaires.Les avantages des caches L3 et L4 dépendent des modèles d'accès de l'application. Voici quelques exemples de produits intégrant des caches L3 et L4 :
- Alpha 21164 (1995) disposait d'un cache L3 hors puce de 1 à 64 Mio.
- L'AMD K6-III (1999) disposait d'un cache L3 basé sur la carte mère.
- IBM POWER4 (2001) disposait de caches L3 hors puce de 32 Mio par processeur, partagés entre plusieurs processeurs.
- L'Itanium 2 (2003) disposait d'un cache Itanium 2 (2003) MX 2 incorporait deux processeurs Itanium 2 ainsi qu'un cache L4 partagé de 64 Mio sur un module multi-puces compatible broche à broche avec un processeur Madison.
- Le produit Intel Xeon MP, nom de code « Tulsa » (2006), dispose de 16 Mio de cache L3 intégré partagé entre deux cœurs de processeur.
- AMD Phenom (2007) avec 2 Mio de cache L3.
- L'AMD Phenom II (2008) dispose d'un cache L3 unifié sur puce allant jusqu'à 6 Mio.
- Intel Core i7 (2008) possède un cache L3 unifié sur puce de 8 Mio, inclusif et partagé par tous les cœurs.
- Les processeurs Intel Haswell avec carte graphique intégrée Intel Iris Pro disposent de 128 Mio d'eDRAM faisant essentiellement office de cache L4.
Enfin, à l'autre extrémité de la hiérarchie mémoire, le fichier de registres du processeur peut être considéré comme le cache le plus petit et le plus rapide du système. Sa particularité réside dans le fait qu'il est géré par logiciel, généralement par le compilateur, qui alloue des registres pour stocker les valeurs extraites de la mémoire principale, par exemple pour l'optimisation des boucles imbriquées . Cependant, grâce au renommage des registres , la plupart des affectations de registres du compilateur sont réallouées dynamiquement par le matériel à l'exécution dans un banc de registres, permettant ainsi au processeur de rompre les dépendances de données erronées et d'atténuer les risques liés au pipeline.
Les fichiers de registres présentent parfois une hiérarchie : le Cray-1 (vers 1976) disposait de huit registres d’adresse « A » et de huit registres de données scalaires « S » généralement utilisables. Il comportait également 64 registres d’adresse « B » et 64 registres de données scalaires « T », dont l’accès était plus lent, mais plus rapide que la mémoire principale. Les registres « B » et « T » étaient nécessaires car le Cray-1 ne possédait pas de cache de données. (Le Cray-1 disposait toutefois d’un cache d’instructions.)
multicœur , la question se pose de savoir si les caches doivent être partagés ou locaux à chaque cœur. La mise en œuvre d'un cache partagé engendre inévitablement un câblage plus complexe. En revanche, disposer d'un cache par puce , plutôt que par cœur , réduit considérablement l'espace nécessaire et permet ainsi d'intégrer un cache de plus grande capacité.En règle générale, le partage du cache L1 est déconseillé car l'augmentation de latence qui en résulte ralentirait considérablement chaque cœur par rapport à une puce monocœur. Cependant, pour le cache de plus haut niveau (généralement L3, le dernier appelé avant l'accès à la mémoire), un cache global est souhaitable pour plusieurs raisons : il permet à un seul cœur d'utiliser l'intégralité du cache, réduit la redondance des données en autorisant différents processus ou threads à partager les données mises en cache, et simplifie les protocoles de cohérence de cache utilisés. Par exemple, une puce à huit cœurs avec trois niveaux de cache peut inclure un cache L1 par cœur, un cache L2 intermédiaire pour chaque paire de cœurs et un cache L3 partagé par tous les cœurs.
Un cache de niveau le plus élevé partagé (généralement L3, appelé avant l'accès à la mémoire) est généralement désigné sous le nom de cache de dernier niveau (LLC). Des techniques supplémentaires sont utilisées pour augmenter le niveau de parallélisme lorsque le LLC est partagé entre plusieurs cœurs, notamment en le divisant en plusieurs morceaux qui adressent des plages d'adresses mémoire spécifiques et peuvent être utilisés indépendamment.
Séparés versus unifiés
Dans une structure de cache séparée, les instructions et les données sont mises en cache séparément ; une ligne de cache sert donc soit aux instructions, soit aux données, mais pas aux deux. L’utilisation de tampons de traduction d’instructions et de données distincts présente divers avantages . Dans une structure unifiée, cette contrainte disparaît et les lignes de cache peuvent servir à la fois aux instructions et aux données.
AMD Athlon ) utilisent des caches exclusifs : les données sont garanties de se trouver dans au plus l'un des caches L1 ou L2, jamais dans les deux. D'autres processeurs encore (comme les Intel Pentium II , III et 4 ) n'exigent pas que les données du cache L1 résident également dans le cache L2, bien que cela soit souvent le cas. Il n'existe pas de nom universellement accepté pour cette politique intermédiaire ; deux appellations courantes sont « non exclusif » et « partiellement inclusif ».L’avantage des caches exclusifs réside dans leur capacité de stockage supérieure. Cet avantage est plus marqué lorsque le cache L1 exclusif est comparable au cache L2, et diminue si le cache L2 est beaucoup plus grand que le cache L1. En cas d’échec d’accès dans le cache L1 et de succès dans le cache L2, la ligne correspondante dans le cache L2 est échangée avec une ligne du cache L1. Cet échange est beaucoup plus complexe que la simple copie d’une ligne du cache L2 vers le cache L1, opération effectuée par un cache inclusif.
L'un des avantages des caches strictement inclusifs est que, lorsqu'un périphérique externe ou un autre processeur d'un système multiprocesseur souhaite supprimer une ligne de cache du processeur, il suffit que ce dernier consulte le cache L2. Dans les hiérarchies de caches n'imposant pas l'inclusion, le cache L1 doit également être consulté. En revanche, il existe une corrélation entre les associativités des caches L1 et L2 : si le cache L2 ne possède pas au moins autant de voies que l'ensemble des caches L1, l'associativité effective de ces derniers est limitée. Un autre inconvénient des caches inclusifs est que, lors de toute éviction dans le cache L2, les lignes (potentiellement) correspondantes dans le cache L1 doivent également être évincées afin de maintenir l'inclusivité. Cette opération est conséquente et entraîne un taux d'échecs de cache L1 plus élevé.
Un autre avantage des caches inclusifs est que le cache principal peut utiliser des lignes de cache plus larges, ce qui réduit la taille des étiquettes du cache secondaire. (Les caches exclusifs exigent que les deux caches aient des lignes de cache de même taille, afin que les lignes puissent être permutées en cas d'échec de cache L1 et de succès de cache L2.) Si le cache secondaire est dix fois plus grand que le cache principal, et que les données du cache sont dix fois plus grandes que les étiquettes de cache, la surface d'étiquettes ainsi économisée peut être comparable à la surface incrémentale nécessaire pour stocker les données du cache L1 dans le cache L2.
Mémoire du bloc-notes
La mémoire scratchpad (SPM), également connue sous le nom de mémoire scratchpad, mémoire RAM scratchpad ou mémoire locale dans la terminologie informatique, est une mémoire interne à haute vitesse utilisée pour le stockage temporaire de calculs, de données et d'autres travaux en cours.Exemple : le K8
Pour illustrer à la fois la spécialisation et la mise en cache multiniveau, voici la hiérarchie de cache du cœur K8 du processeur AMD Athlon 64.
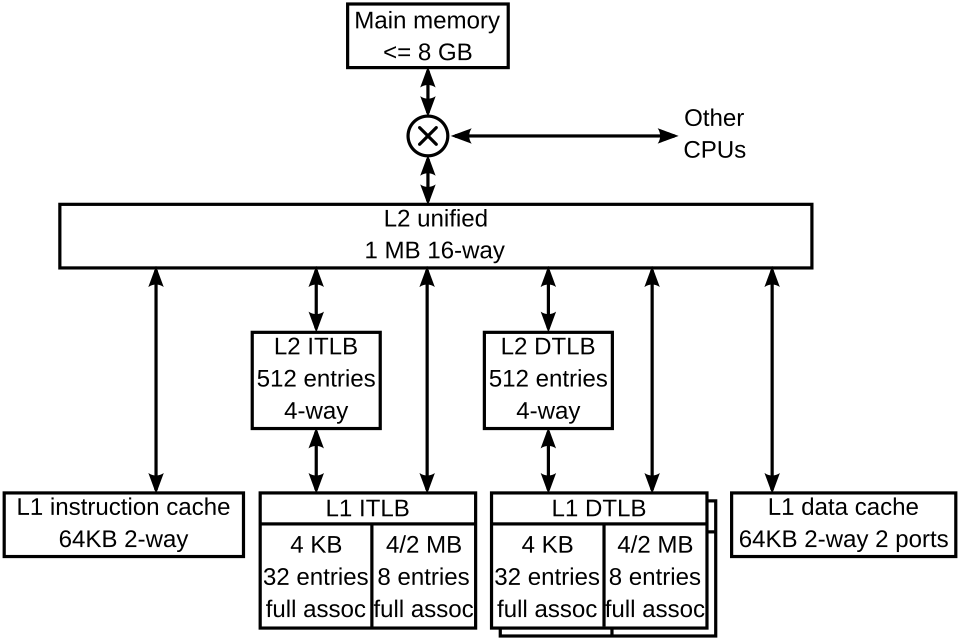
Hiérarchie du cache du cœur K8 du processeur AMD Athlon 64 Le K8 possède quatre caches spécialisés : un cache d’instructions, un TLB d’instructions , un TLB de données et un cache de données. Chacun de ces caches est spécialisé :
- Le cache d'instructions conserve des copies de lignes de mémoire de 64 octets et en extrait 16 à chaque cycle. Chaque octet de ce cache est stocké sur dix bits au lieu de huit, les bits supplémentaires marquant les limites des instructions (il s'agit d'un exemple de prédécodage). Le cache utilise uniquement la parité plutôt que la correction d'erreurs (ECC ), car la parité est plus petite et toute donnée corrompue peut être remplacée par des données fraîches extraites de la mémoire (qui contient toujours une copie à jour des instructions).
- Le TLB d'instructions conserve des copies des entrées de table des pages (PTE). À chaque cycle, l'adresse virtuelle de chaque instruction est traduite par ce TLB en une adresse physique. Chaque entrée occupe quatre ou huit octets en mémoire. Le K8 ayant une taille de page variable, chaque TLB est divisé en deux sections : l'une pour les PTE correspondant à des pages de 4 Kio, l'autre pour celles correspondant à des pages de 4 Mio ou 2 Mio. Cette division simplifie le circuit d'association dans chaque section. Le système d'exploitation associe des PTE de tailles différentes aux différentes sections de l'espace d'adressage virtuel.
- Le TLB de données possède deux copies contenant des entrées identiques. Ces deux copies permettent deux accès aux données par cycle pour traduire les adresses virtuelles en adresses physiques. À l'instar du TLB d'instructions, ce TLB est divisé en deux types d'entrées.
- Le cache de données conserve des copies de lignes de mémoire de 64 octets. Il est divisé en 8 banques (chacune stockant 8 Kio de données) et peut accéder à deux ensembles de données de 8 octets par cycle, à condition qu'ils se trouvent dans des banques différentes. Il existe deux copies des étiquettes, car chaque ligne de 64 octets est répartie entre les huit banques. Chaque copie d'étiquette gère l'un des deux accès par cycle.
Le K8 dispose également de caches à plusieurs niveaux. Il existe des TLB d'instructions et de données de second niveau, qui stockent uniquement des entrées de table de pages (PTE) mappant 4 KiB. Les caches d'instructions et de données, ainsi que les différents TLB, peuvent être alimentés par le vaste cache L2 unifié . Ce cache est exclusif aux caches d'instructions et de données L1, ce qui signifie que toute ligne de 8 octets ne peut se trouver que dans l'un des caches suivants : le cache d'instructions L1, le cache de données L1 ou le cache L2. Il est toutefois possible qu'une ligne du cache de données contienne une PTE présente également dans l'un des TLB ; le système d'exploitation assure la cohérence des TLB en vidant certaines portions de ces derniers lors de la mise à jour des tables de pages en mémoire.
Le K8 met également en cache des informations qui ne sont jamais stockées en mémoire : les informations de prédiction. Ces caches ne sont pas représentés sur le schéma ci-dessus. Comme c'est souvent le cas pour ce type de processeur, le K8 dispose d'une prédiction de branchement assez complexe , avec des tables permettant de prédire si des branchements seront effectués et d'autres tables prédisant les cibles des branchements et des sauts. Certaines de ces informations sont associées aux instructions, à la fois dans le cache d'instructions de niveau 1 et dans le cache secondaire unifié.
Le K8 utilise une astuce ingénieuse pour stocker les informations de prédiction avec les instructions dans le cache secondaire. Les lignes de ce cache sont protégées contre toute corruption accidentelle de données (par exemple, suite à l'impact d'une particule alpha ) par un système de correction d'erreurs (ECC) ou par parité , selon qu'elles proviennent du cache principal de données ou d'instructions. Le code de parité occupant moins de bits que le code ECC, les lignes du cache d'instructions disposent de quelques bits supplémentaires. Ces bits servent à stocker les informations de prédiction de branchement associées à ces instructions. Il en résulte un historique de branchement plus étendu pour le prédicteur de branchement, et donc une meilleure précision.
Plus de hiérarchies
D'autres processeurs disposent d'autres types de prédicteurs (par exemple, le prédicteur de contournement de stockage à chargement dans le DEC Alpha 21264 ).
Ces prédicteurs sont des caches, car ils stockent des informations dont le calcul est coûteux. Certains termes employés pour parler des prédicteurs sont les mêmes que ceux utilisés pour les caches (on parle par exemple de « succès » dans un prédicteur de branchement), mais les prédicteurs ne sont généralement pas considérés comme faisant partie de la hiérarchie des caches.
Le K8 assure la cohérence matérielle des caches d'instructions et de données, ce qui signifie qu'une instruction de stockage effectuée juste après une autre modifiera l'instruction suivante. D'autres processeurs, comme ceux des familles Alpha et MIPS, s'appuient sur le logiciel pour maintenir la cohérence du cache d'instructions. L'affichage des instructions de stockage dans le flux d'instructions n'est garanti que lorsqu'un programme appelle une fonction du système d'exploitation pour assurer cette cohérence.
Étiquette RAM

Tag RAM sur la carte d'un Intel Pentium III En génie informatique, une mémoire RAM étiquetée permet de spécifier quelle adresse mémoire est actuellement stockée dans le cache du processeur. Pour une conception simple à correspondance directe, une SRAM rapide peut être utilisée. Les caches associatifs de niveau supérieur utilisent généralement une mémoire adressable par contenu .
Mise en œuvre
Chemin de lecture pour un cache associatif à deux voies Le schéma ci-contre vise à clarifier l'utilisation des différents champs de l'adresse. Le bit 31 est le plus significatif, le bit 0 le moins significatif. Ce schéma représente les SRAM, l'indexation et le multiplexage d'un cache de 4 Kio, associatif par ensembles à deux voies, indexé et étiqueté virtuellement, avec des lignes de 64 octets (B), une largeur de lecture de 32 bits et une adresse virtuelle de 32 bits.
Le cache ayant une capacité de 4 KiB et comportant 64 lignes d'octets, il ne contient que 64 lignes. La lecture s'effectue par paires à partir d'une SRAM d'étiquettes de 32 lignes, chacune associée à une paire d'étiquettes de 21 bits. Bien que toute fonction des bits d'adresse virtuelle 31 à 6 puisse être utilisée pour indexer les SRAM d'étiquettes et de données, l'utilisation des bits de poids faible est plus simple.
De même, étant donné que le cache fait 4 KiB et possède un chemin de lecture de 4 B, et qu'il lit de deux manières pour chaque accès, la SRAM de données comporte 512 lignes de 8 octets de large.
Un cache plus moderne pourrait avoir une capacité de 16 Kio, être associatif par ensembles à 4 voies, indexé virtuellement, avec des indications virtuelles et un marquage physique, avec des lignes de 32 octets, une largeur de lecture de 32 bits et des adresses physiques de 36 bits. Le chemin de lecture pour un tel cache est très similaire à celui décrit précédemment. Au lieu d'étiquettes, ce sont des indications virtuelles qui sont lues et comparées à un sous-ensemble de l'adresse virtuelle. Plus tard dans le pipeline, l'adresse virtuelle est traduite en adresse physique par le TLB, et l'étiquette physique correspondante est lue (une seule, car l'indication virtuelle indique le sens de lecture dans le cache). Enfin, l'adresse physique est comparée à l'étiquette physique pour déterminer si une correspondance a été trouvée.
Certaines conceptions SPARC ont amélioré la vitesse de leurs caches L1 de quelques délais de porte en intégrant l'additionneur d'adresses virtuelles dans les décodeurs SRAM.aux registres . Mais depuis les années 1980 l'écart de performance entre le processeur et la mémoire n'a cessé de se creuser. Les microprocesseurs ont progressé beaucoup plus vite que la mémoire, notamment en termes de fréquence de fonctionnement , faisant de cette dernière un goulot d'étranglement. S'il était techniquement possible d'avoir une mémoire principale aussi rapide que le processeur, une solution plus économique a été privilégiée : utiliser une grande quantité de mémoire basse vitesse, tout en intégrant une petite mémoire cache haute vitesse pour compenser l'écart de performance. Cette approche a permis d'obtenir une capacité dix fois supérieure – pour un coût identique – avec une légère diminution des performances globales.
Premières implémentations TLB
Les premières utilisations documentées d'un TLB ont eu lieu sur le GE 645 et l' IBM 360/67 , qui utilisaient tous deux une mémoire associative comme TLB.
Cache de première instruction
La première utilisation documentée d'un cache d'instructions a eu lieu sur le CDC 6600.
Premier cache de données
La première utilisation documentée d'un cache de données a eu lieu sur le système IBM System/360 modèle 85.
Dans les microprocesseurs 68k
Le 68010 , sorti en 1982, dispose d'un « mode boucle » pouvant être considéré comme un cache d'instructions réduit et spécifique, accélérant les boucles composées de seulement deux instructions. Le 68020 , sorti en 1984, a remplacé ce mode par un cache d'instructions classique de 256 octets, devenant ainsi le premier processeur de la série 68k à intégrer une véritable mémoire cache sur puce.
Le 68030 , sorti en 1987, est essentiellement un cœur 68020 avec un cache de données supplémentaire de 256 octets, une unité de gestion de la mémoire sur puce (MMU), une réduction de processus et un mode rafale ajouté pour les caches.
Le 68040 , sorti en 1990, possède des caches d'instructions et de données séparés de quatre kilo-octets chacun.
Le 68060 , sorti en 1994, possède les éléments suivants : cache de données de 8 KiB (associatif à quatre voies), cache d'instructions de 8 KiB (associatif à quatre voies), tampon d'instructions FIFO de 96 octets, cache de branchement de 256 entrées et tampon MMU de cache de traduction d'adresses de 64 entrées (associatif à quatre voies).
Dans les microprocesseurs x86

Exemple de carte mère avec un microprocesseur i386 (33 MHz), 64 KiB de cache (25 ns ; 8 puces dans le coin inférieur gauche), 2 Mio de DRAM (70 ns ; 8 SIMM à droite du cache) et un contrôleur de cache ( Austek A38202 ; à droite du processeur). Avec l'arrivée des microprocesseurs x86 à des fréquences d'horloge de 20 MHz et plus (notamment l' A386) , de petites quantités de mémoire cache rapide ont commencé à être intégrées aux systèmes pour améliorer leurs performances. En effet, la DRAM utilisée comme mémoire principale présentait une latence importante, pouvant atteindre 120 ns, ainsi que des cycles de rafraîchissement. Le cache était constitué de cellules de mémoire SRAM , plus coûteuses mais nettement plus rapides, dont la latence était alors de l'ordre de 10 à 25 ns. Les premiers caches étaient externes au processeur et généralement situés sur la carte mère sous la forme de huit ou neuf composants DIP insérés dans des supports, permettant ainsi d'ajouter le cache en option ou de l'étendre.
Certaines versions du processeur Intel 386 pouvaient prendre en charge de 16 à 256 KiB de cache externe.
Avec le processeur 486 , un cache de 8 Kio était intégré directement à la puce. Ce cache était appelé cache de niveau 1 (L1) pour le différencier du cache de niveau 2 (L2), plus lent et situé sur la carte mère. Ces derniers étaient beaucoup plus volumineux, la taille la plus courante étant de 256 Kio. Certaines cartes mères disposaient d'emplacements pour la carte fille Intel 485Turbocache , dotée de 64 ou 128 Ko de mémoire cache. La popularité du cache sur carte mère s'est maintenue durant l' ère Pentium MMX , mais a été rendue obsolète par l'introduction de la SDRAM et l'écart croissant entre les fréquences d'horloge du bus et du processeur, ce qui a fait que le cache sur carte mère n'était plus que légèrement plus rapide que la mémoire principale.
L'évolution suivante en matière d'implémentation de cache dans les microprocesseurs x86 a commencé avec le Pentium Pro , qui a intégré le cache secondaire dans le même boîtier que le microprocesseur, cadencé à la même fréquence que ce dernier.
Les caches intégrés à la carte mère ont longtemps bénéficié d'une grande popularité grâce aux processeurs AMD K6-2 et AMD K6-III , qui utilisaient encore le socket 7 , précédemment employé par Intel avec des caches intégrés. Le K6-III intégrait 256 Kio de cache L2 et exploitait le cache intégré comme cache de troisième niveau, appelé L3 (des cartes mères avec jusqu'à 2 Mio de cache intégré ont été produites). Après l'obsolescence du socket 7, le cache intégré à la carte mère a disparu des systèmes x86.
Les caches à trois niveaux ont été réutilisés pour la première fois avec l'introduction du processeur Intel Xeon MP « Foster Core » , où le cache L3 a été ajouté à la puce du processeur. Il est devenu courant que la taille totale du cache augmente avec les nouvelles générations de processeurs, et récemment (en 2011), il n'est pas rare de trouver des caches de niveau 3 de plusieurs dizaines de mégaoctets
Intel a introduit un cache de niveau 4 intégré avec la microarchitecture Haswell . Les processeurs Crystalwell Haswell, équipés de la variante GT3e du processeur graphique intégré Intel Iris Pro, disposent de 128 Mio de mémoire DRAM embarquée ( eDRAM ) sur le même boîtier. Ce cache L4 est partagé dynamiquement entre le GPU et le CPU intégrés, et sert de cache victime au cache L3 du CPU.
Dans les microprocesseurs ARM
Le processeur Apple M1 dispose de 128 ou 192 Kio de cache d'instructions L1 par cœur (important pour la latence et les performances monocœur), selon le type de cœur. Il s'agit d'un cache L1 exceptionnellement important pour un processeur (et pas seulement pour un ordinateur portable). La taille totale de la mémoire cache n'est pas particulièrement élevée pour un ordinateur portable (c'est le total qui importe le plus pour le débit), et des tailles totales bien supérieures (par exemple, L3 ou L4) sont disponibles sur les ordinateurs centraux IBM.
Recherches actuelles
Les premières conceptions de cache se concentraient exclusivement sur le coût direct du cache et de la RAM , ainsi que sur la vitesse d'exécution moyenne. Les conceptions de cache plus récentes prennent également en compte l'efficacité énergétique , la tolérance aux pannes et d'autres objectifs.
Plusieurs outils sont à la disposition des architectes informatiques pour les aider à explorer les compromis entre le temps de cycle du cache, l'énergie et la surface ; le simulateur de cache CACTI et le simulateur de jeu d'instructions SimpleScalar sont deux options open-source.
Cache multiport
Un cache multiport est un cache capable de traiter plusieurs requêtes simultanément. Alors qu'un cache traditionnel utilise généralement une seule adresse mémoire, un cache multiport peut permettre de demander N adresses à la fois, N étant le nombre de ports connectés entre le processeur et le cache. L'avantage est qu'un processeur pipeliné peut accéder à la mémoire depuis différentes phases de son pipeline. Autre avantage : il rend possible le concept de processeurs superscalaires grâce à différents niveaux de cache.
Plus d articles de Worldlex Wiki
Revenez a l index pour explorer davantage de pages sur l histoire, la science, la culture, la geographie et la societe en francais.
Explorer l index
Rédiger des politiques
Il existe également des politiques intermédiaires. Le cache peut être en écriture immédiate, mais les écritures peuvent être temporairement stockées dans une file d'attente de données, généralement pour permettre le traitement simultané de plusieurs opérations (ce qui peut réduire les temps d'attente sur le bus et améliorer son utilisation).
Les données mises en cache en mémoire principale peuvent être modifiées par d'autres entités (par exemple, des périphériques utilisant l'accès direct à la mémoire (DMA) ou un autre cœur d'un processeur multicœur ), auquel cas la copie dans le cache peut devenir obsolète. Inversement, lorsqu'un processeur d'un système multiprocesseur met à jour des données dans le cache, les copies de ces données dans les caches associés aux autres processeurs deviennent obsolètes. Les protocoles de communication entre les gestionnaires de cache qui assurent la cohérence des données sont appelés protocoles de cohérence de cache .
performances du cache
La mesure des performances du cache est devenue cruciale ces derniers temps, l'écart de vitesse entre la mémoire et le processeur augmentant de façon exponentielle. Le cache a été introduit pour réduire cet écart. Il est donc important de savoir dans quelle mesure il parvient à combler cet écart, notamment dans les systèmes hautes performances. Le taux de succès et le taux d'échec du cache jouent un rôle déterminant dans ces performances. Pour améliorer le cache, la réduction du taux d'échec est une étape essentielle parmi d'autres. Diminuer le temps d'accès au cache contribue également à améliorer ses performances et facilite son optimisation.
blocages du processeur
Le temps nécessaire pour accéder à une ligne de cache en mémoire ( latence due à un défaut de cache) est important car le processeur ne pourra plus effectuer de tâches pendant l'attente. Lorsqu'il atteint cet état, on parle de blocage. À mesure que les processeurs deviennent plus rapides que la mémoire vive, les blocages dus aux défauts de cache réduisent considérablement le potentiel de calcul ; les processeurs modernes peuvent exécuter des centaines d'instructions pendant le temps nécessaire pour accéder à une seule ligne de cache en mémoire vive.
Diverses techniques ont été employées pour maintenir le processeur occupé pendant ce temps, notamment l'exécution hors séquence, où le processeur tente d'exécuter des instructions indépendantes après l'instruction en attente de données manquantes dans le cache. Une autre technologie, utilisée par de nombreux processeurs, est le multithreading simultané (SMT), qui permet à un thread alternatif d'utiliser le cœur du processeur pendant que le premier thread attend que les ressources nécessaires soient disponibles.
Associativité
La politique de placement détermine l'emplacement, dans le cache, de la copie d'une entrée particulière de la mémoire principale. Si cette politique peut choisir librement n'importe quel emplacement du cache, celui-ci est dit entièrement associatif . À l'inverse, si chaque entrée de la mémoire principale ne peut être placée qu'à un seul emplacement dans le cache, celui-ci est dit à correspondance directe . De nombreux caches adoptent un compromis : chaque entrée de la mémoire principale peut être placée à l'un des N emplacements possibles dans le cache ; on les qualifie alors de caches associatifs à N voies. Par exemple, le cache de données de niveau 1 d'un processeur AMD Athlon est associatif à deux voies, ce qui signifie que toute adresse mémoire peut être placée à l'un ou l'autre des deux emplacements possibles dans le cache de données de niveau 1.
Choisir la valeur optimale d'associativité implique un compromis . Si la politique de placement peut associer une adresse mémoire à dix emplacements, il faut parcourir ces dix entrées de cache pour vérifier sa présence dans le cache. Vérifier davantage d'emplacements consomme plus d'énergie et occupe plus de surface sur la puce, ce qui peut allonger le temps de lecture. En revanche, les caches à forte associativité subissent moins de défauts de cache (voir les défauts de conflit ), ce qui réduit le temps perdu par le processeur à lire la mémoire principale, plus lente. En règle générale, doubler l'associativité, en passant d'un mappage direct à un mappage à deux voies, ou de deux voies à quatre voies, a un impact similaire sur le taux d'accès réussi à celui obtenu en doublant la taille du cache. Cependant, augmenter l'associativité au-delà de quatre n'améliore pas autant le taux d'accès réussi et est généralement effectué pour d'autres raisons (voir l'aliasing virtuel ). Certains processeurs peuvent réduire dynamiquement l'associativité de leurs caches en mode basse consommation, ce qui permet de réaliser des économies d'énergie
Du plus simple mais le moins bon au plus complexe mais le meilleur :
- Cache à mappage direct – bon temps dans le meilleur des cas, mais imprévisible dans le pire des casLRU est particulièrement simple puisqu'un seul bit doit être stocké pour chaque paire.
Exécution spéculative
L'un des avantages d'un cache à correspondance directe est qu'il permet une recherche simple et rapide . Une fois l'adresse calculée, l'index du cache susceptible de contenir une copie de cet emplacement en mémoire est connu. Cette entrée de cache peut être lue, et le processeur peut poursuivre le traitement des données avant même d'avoir vérifié que l'étiquette correspond bien à l'adresse demandée.
L'idée d'utiliser les données mises en cache par le processeur avant même que la correspondance avec l'étiquette ne soit terminée s'applique également aux caches associatifs. Un sous-ensemble de l'étiquette, appelé indice , permet de sélectionner une seule entrée du cache correspondant à l'adresse demandée. Cette entrée sélectionnée peut ensuite être utilisée en parallèle avec la vérification de l'étiquette complète. Cette technique d'indice est particulièrement efficace dans le cadre de la traduction d'adresses, comme expliqué ci-dessous.
Cache associatif à double biais
D'autres schémas ont été proposés, comme le cache asymétrique où l'index de la voie 0 est direct, comme précédemment, tandis que celui de la voie 1 est généré par une fonction de hachage . Une bonne fonction de hachage a la propriété que les adresses en conflit avec le mappage direct tendent à ne plus l'être lorsqu'elles sont mappées avec la fonction de hachage. Ainsi, un programme est moins susceptible de subir un nombre anormalement élevé d'échecs de lecture dus à un schéma d'accès pathologique. L'inconvénient est la latence supplémentaire liée au calcul de la fonction de hachage . De plus, lors du chargement d'une nouvelle ligne et de la suppression d'une ancienne, il peut être difficile de déterminer quelle ligne existante a été la moins récemment utilisée, car la nouvelle ligne entre en conflit avec des données à différents index dans chaque voie ; le suivi LRU pour les caches non asymétriques est généralement effectué par ensemble. Néanmoins, les caches associatifs asymétriques présentent des avantages majeurs par rapport aux caches associatifs par ensembles classiques
Cache pseudo-associatif
Un cache associatif véritable teste simultanément toutes les possibilités, à l'aide d'un système de mémoire adressable par contenu (CASM) . Un cache pseudo-associatif teste chaque possibilité une à une. Le cache par hachage-rehachage et le cache associatif par colonnes sont des exemples de caches pseudo-associatifs.
Dans le cas courant de la découverte d'une correspondance de la première manière testée, un cache pseudo-associatif est aussi rapide qu'un cache à correspondance directe, mais il a un taux d'échec de conflit beaucoup plus faible qu'un cache à correspondance directe, plus proche du taux d'échec d'un cache entièrement associatif.
Cache multicolonne
Comparativement à un cache à correspondance directe, un cache associatif par ensembles utilise un nombre réduit de bits pour son index d'ensemble, qui correspond à un ensemble de cache contenant plusieurs voies ou blocs : par exemple, 2 blocs pour un cache associatif par ensembles à 2 voies et 4 blocs pour un cache associatif par ensembles à 4 voies. Les bits d'index non utilisés sont intégrés aux bits d'étiquette. Ainsi, un cache associatif par ensembles à 2 voies contribue 1 bit à l'étiquette, tandis qu'un cache associatif par ensembles à 4 voies y contribue 2 bits. Le principe du cache multicolonne est d'utiliser l'index d'ensemble pour associer un élément à un ensemble de cache, comme pour un cache associatif par ensembles classique, et d'utiliser les bits d'étiquette supplémentaires pour indexer une voie au sein de cet ensemble. Par exemple, dans un cache associatif par ensembles à 4 voies, les deux bits supplémentaires servent à indexer respectivement les voies 00, 01, 10 et 11. Ce double indexage de cache est appelé « mappage d'emplacement principal » et sa latence est équivalente à celle d'un accès direct. De nombreuses expériences sur la conception de caches multicolonnes montrent que le taux d'accès aux emplacements principaux atteint 90 %. Si un mappage de cache entre en conflit avec un bloc de cache situé à l'emplacement principal, ce bloc est déplacé vers un autre chemin de cache du même ensemble, appelé « emplacement sélectionné ». Le bloc nouvellement indexé étant le bloc le plus récemment utilisé (MRU), il est placé à l'emplacement principal du cache multicolonne en tenant compte de la localité temporelle. Le cache multicolonne étant conçu pour une forte associativité, le nombre de chemins dans chaque ensemble est élevé ; il est donc facile de trouver un emplacement sélectionné. Un index d'emplacement sélectionné est maintenu par un matériel supplémentaire pour l'emplacement principal d'un bloc de cache.expliqués ci-dessous .
La « taille » du cache correspond à la quantité de données de la mémoire principale qu'il peut contenir. Cette taille se calcule en multipliant le nombre d'octets stockés dans chaque bloc de données par le nombre de blocs stockés dans le cache. (Les bits d'étiquette, d'indicateur et de code de correction d'erreurs ne sont pas inclus dans la taille , bien qu'ils influent sur la surface physique du cache.)
Une adresse mémoire effective associée à la ligne de cache (bloc mémoire) est divisée ( MSB vers LSB ) en étiquette, index et décalage de bloc.
| étiqueter | indice | décalage de bloc |
L'index décrit le cache dans lequel les données ont été placées. Sa longueur est de bits pour
Le processeur Pentium 4 d'origine disposait également d'un cache L2 intégré associatif à huit voies de 256 Kio, avec des blocs de cache de 128 octets. Cela implique 32 − 8 − 7 = 17 bits pour le champ d'étiquette.
d'écoute de bus multi-maître du cache d'un processeur détecte une diffusion d'adresse provenant d'un autre processeur et constate que certains blocs de données du cache local sont désormais obsolètes et doivent être marqués comme invalides.Un cache de données nécessite généralement deux bits d'indicateur par ligne de cache : un bit de validité et un bit de modification . Lorsque le bit de modification est activé, cela signifie que la ligne de cache associée a été modifiée depuis sa lecture en mémoire principale (« modifiée »), c'est-à-dire que le processeur a écrit des données sur cette ligne et que la nouvelle valeur n'a pas encore été propagée jusqu'à la mémoire principale.
thread d'exécution , doit attendre (se bloquer) que l'instruction soit récupérée de la mémoire principale. Les défauts de lecture dans le cache de données entraînent généralement un délai plus court, car les instructions non dépendantes de la lecture peuvent être exécutées et poursuivre leur exécution jusqu'à ce que les données soient renvoyées par la mémoire principale, et les instructions dépendantes peuvent reprendre leur exécution. Les défauts d'écriture dans le cache de données entraînent généralement le délai le plus court, car l'écriture peut être mise en file d'attente et l'exécution des instructions suivantes est peu limitée ; le processeur peut continuer jusqu'à ce que la file d'attente soit pleine. Pour une présentation détaillée des types de défauts, consultez la section « Mesure et métriques des performances du cache » .mémoire virtuelle . En résumé, soit chaque programme exécuté sur la machine dispose de son propre espace d'adressage simplifié , contenant uniquement le code et les données de ce programme, soit tous les programmes s'exécutent dans un espace d'adressage virtuel commun. Un programme s'exécute en calculant, comparant, lisant et écrivant aux adresses de son espace d'adressage virtuel, plutôt qu'aux adresses de l'espace d'adressage physique, ce qui simplifie les programmes et facilite leur écriture.La mémoire virtuelle nécessite que le processeur traduise les adresses virtuelles générées par le programme en adresses physiques dans la mémoire principale. La partie du processeur qui effectue cette traduction est appelée unité de gestion de la mémoire (MMU). Le chemin rapide à travers la MMU peut effectuer ces traductions stockées dans le tampon de traduction (TLB), qui est un cache de correspondances entre la table des pages , la table des segments, ou les deux, du système d'exploitation .
Dans le cadre de la présente discussion, la traduction d'adresses présente trois caractéristiques importantes :
- Latence : L'adresse physique est disponible auprès de l'unité de gestion de la mémoire (MMU) un certain temps, peut-être quelques cycles, après que l'adresse virtuelle soit disponible auprès du générateur d'adresses.
- Gio peut être divisé en 1 048 576 pages de 4 Kio, chacune pouvant être mappée indépendamment. Plusieurs tailles de page peuvent être prises en charge ; voir la documentation sur la mémoire virtuelle pour plus de détails.
Un des premiers systèmes de mémoire virtuelle, l' IBM M44/44X , nécessitait un accès à une table de correspondance stockée en mémoire centrale avant chaque accès programmé à la mémoire principale. En l'absence de cache, et la mémoire de la table de correspondance fonctionnant à la même vitesse que la mémoire principale, la vitesse d'accès à la mémoire était ainsi réduite de moitié. Deux machines anciennes utilisant une table des pages en mémoire principale pour la correspondance, l' IBM System/360 Modèle 67 et le GE 645 , disposaient toutes deux d'une petite mémoire associative servant de cache pour les accès à la table des pages en mémoire. Ces deux machines sont antérieures à la première machine dotée d'un cache pour la mémoire principale, l' IBM System/360 Modèle 85 ; le premier cache matériel utilisé dans un système informatique n'était donc pas un cache de données ou d'instructions, mais un TLB (Time-Level Block).
Les caches peuvent être divisés en quatre types, selon que l'index ou l'étiquette corresponde à des adresses physiques ou virtuelles :
- Les caches à indexation physique et étiquetage physique (PIPT) utilisent l'adresse physique à la fois pour l'index et l'étiquette. Bien que cette méthode soit simple et évite les problèmes d'aliasing, elle est également lente, car l'adresse physique doit être recherchée (ce qui peut entraîner un défaut de bloc de liste et un accès à la mémoire principale) avant que cette adresse puisse être recherchée dans le cache.
- Les caches VIVT ( Virtually Indexed, Virtually Tagged ) utilisent l'adresse virtuelle à la fois comme index et comme étiquette. Ce schéma de cache permet des recherches beaucoup plus rapides, car il n'est pas nécessaire de consulter l'unité de gestion de la mémoire (MMU) au préalable pour déterminer l'adresse physique correspondant à une adresse virtuelle donnée. Cependant, les caches VIVT souffrent de problèmes d'aliasing : plusieurs adresses virtuelles différentes peuvent désigner la même adresse physique. Ces adresses sont alors mises en cache séparément, bien qu'elles pointent vers la même zone mémoire, ce qui engendre des problèmes de cohérence. Bien que des solutions existent elles ne sont pas compatibles avec les protocoles de cohérence standard. Un autre problème est celui des homonymes : une même adresse virtuelle peut correspondre à plusieurs adresses physiques différentes. Il est impossible de distinguer ces correspondances en se basant uniquement sur l'index virtuel. Parmi les solutions potentielles, on peut citer : le vidage du cache après un changement de contexte , l'obligation d'utiliser des espaces d'adressage non chevauchants et l'attribution d'un identifiant d'espace d'adressage (ASID) à l'adresse virtuelle. De plus, le problème de la modification des correspondances entre adresses virtuelles et physiques nécessite la vidange du cache, car les adresses virtuelles ne sont plus valides. Ces problèmes disparaissent lorsque les étiquettes utilisent des adresses physiques (VIPT).
- Les caches à indexation virtuelle et étiquetage physique (VIPT) utilisent l'adresse virtuelle pour l'index et l'adresse physique dans l'étiquette. L'avantage par rapport aux caches PIPT réside dans une latence réduite, car la recherche dans le cache peut être effectuée en parallèle avec la traduction TLB. Cependant, l'étiquette ne peut être comparée que lorsque l'adresse physique est disponible. L'avantage par rapport aux caches VIVT est que, grâce à l'étiquette contenant l'adresse physique, le cache peut détecter les homonymes. Théoriquement, les caches VIPT nécessitent davantage de bits d'étiquette, car certains bits d'index peuvent différer entre les adresses virtuelle et physique (par exemple, les bits 12 et suivants pour les pages de 4 Kio) et devraient être inclus à la fois dans l'index virtuel et dans l'étiquette physique. En pratique, cela ne pose pas de problème car, afin d'éviter les problèmes de cohérence, les caches VIPT sont conçus sans ces bits d'index (par exemple, en limitant le nombre total de bits pour l'index et le décalage de bloc à 12 pour les pages de 4 Kio) ; la taille des caches VIPT est ainsi limitée à la taille de la page multipliée par l'associativité du cache.
- Les caches à indexation physique et étiquetage virtuel (PIVT) sont souvent considérés dans la littérature comme inutiles et inexistants . Pourtant, le MIPS R6000 utilise ce type de cache comme seule implémentation connue . Le R6000 est implémenté en logique à couplage d'émetteur , une technologie extrêmement rapide, mais inadaptée aux grandes mémoires telles qu'un TLB . Le R6000 résout ce problème en plaçant la mémoire TLB dans une partie réservée du cache de second niveau, dotée d'une minuscule « tranche » TLB haute vitesse intégrée. Le cache est indexé par l'adresse physique obtenue à partir de cette tranche TLB. Cependant, comme la tranche TLB ne traduit que les bits d'adresse virtuelle nécessaires à l'indexation du cache et n'utilise aucun étiquetage, des accès non autorisés au cache peuvent se produire. Ce problème est résolu par l'étiquetage avec l'adresse virtuelle.
La vitesse de cette récurrence (la latence de chargement ) est cruciale pour les performances du processeur, et c'est pourquoi la plupart des caches de niveau 1 modernes sont virtuellement indexés, ce qui permet au moins à la recherche TLB de l'unité de gestion de la mémoire (MMU) de se dérouler en parallèle avec la récupération des données de la mémoire RAM du cache.
Cependant, l'indexation virtuelle n'est pas optimale pour tous les niveaux de cache. Le coût de la gestion des alias virtuels augmente avec la taille du cache ; c'est pourquoi la plupart des caches de niveau 2 et plus sont indexés physiquement.
Historiquement, les caches utilisaient à la fois des adresses virtuelles et physiques pour leurs étiquettes, bien que l'étiquetage virtuel soit aujourd'hui rare. Si la recherche dans le TLB peut se terminer avant celle dans la RAM du cache, l'adresse physique est disponible à temps pour la comparaison des étiquettes, et l'étiquetage virtuel devient inutile. Les grands caches sont donc généralement étiquetés physiquement, tandis que seuls les petits caches à très faible latence utilisent l'étiquetage virtuel. Dans les processeurs généralistes récents, l'étiquetage virtuel a été remplacé par des indications virtuelles, comme décrit ci-dessous.
Problèmes d'homonymie et de synonymie
Un cache reposant sur l'indexation et l'étiquetage virtuels devient incohérent lorsqu'une même adresse virtuelle est associée à différentes adresses physiques ( homonymie ). Ce problème peut être résolu en utilisant l'adresse physique pour l'étiquetage, ou en stockant l'identifiant de l'espace d'adressage dans la ligne de cache. Cependant, cette dernière approche ne résout pas le problème des synonymes , où plusieurs lignes de cache finissent par stocker des données pour la même adresse physique. L'écriture à ces emplacements peut ne mettre à jour qu'un seul emplacement dans le cache, laissant les autres avec des données incohérentes. Ce problème peut être résolu en utilisant des dispositions mémoire non chevauchantes pour différents espaces d'adressage, ou bien en vidant le cache (ou une partie de celui-ci) lors de tout changement d'association.
Étiquettes et indices virtuels
Le principal avantage des étiquettes virtuelles est que, pour les caches associatifs, elles permettent d'effectuer la correspondance des étiquettes avant la traduction virtuelle-physique. Cependant, les sondages de cohérence et les évictions fournissent une adresse physique pour l'action. Le matériel doit disposer d'un moyen de convertir les adresses physiques en un index de cache, généralement en stockant à la fois les étiquettes physiques et virtuelles. Par comparaison, un cache à étiquettes physiques n'a pas besoin de conserver d'étiquettes virtuelles, ce qui est plus simple. Lorsqu'une correspondance virtuelle-physique est supprimée du TLB, les entrées de cache associées à ces adresses virtuelles doivent être vidées. De même, si des entrées de cache sont autorisées sur des pages non mappées par le TLB, ces entrées doivent être vidées lorsque les droits d'accès à ces pages sont modifiés dans la table des pages.
Le système d'exploitation peut également garantir qu'aucun alias virtuel ne réside simultanément dans le cache. Il assure cette garantie en appliquant la coloration des pages, décrite ci-dessous. Certains processeurs RISC anciens (SPARC, RS/6000) utilisaient cette approche. Elle n'est plus employée aujourd'hui, car le coût matériel de la détection et de la suppression des alias virtuels a diminué, tandis que la complexité logicielle et la perte de performance liées à une coloration parfaite des pages ont augmenté.
Il peut être utile de distinguer les deux fonctions des étiquettes dans un cache associatif : elles servent à déterminer le sens de sélection de l’ensemble d’entrées, et elles servent à déterminer si la recherche a réussi ou échoué. La seconde fonction doit toujours être correcte, mais la première peut occasionnellement faire des suppositions et donner une réponse erronée.
Certains processeurs (par exemple, les premiers SPARC) possèdent des caches à la fois virtuels et physiques. Les étiquettes virtuelles servent à la sélection du chemin d'accès, tandis que les étiquettes physiques déterminent si l'accès a réussi ou échoué. Ce type de cache bénéficie de la faible latence d'un cache à étiquettes virtuelles et de la simplicité d'interface logicielle d'un cache à étiquettes physiques. Il présente toutefois l'inconvénient supplémentaire des étiquettes dupliquées. De plus, lors du traitement d'un échec d'accès, les chemins d'accès alternatifs de la ligne de cache indexée doivent être analysés afin de détecter les alias virtuels et d'éliminer toute correspondance.
L'espace supplémentaire (et la latence accrue) peut être atténué en conservant des indications virtuelles pour chaque entrée de cache, au lieu d'étiquettes virtuelles. Ces indications sont un sous-ensemble ou un hachage de l'étiquette virtuelle et servent à sélectionner la zone de cache à partir de laquelle récupérer les données et une étiquette physique. Comme pour un cache à étiquettes virtuelles, il peut y avoir une correspondance entre une indication virtuelle et une différence d'étiquette physique. Dans ce cas, l'entrée de cache avec l'indication correspondante doit être supprimée afin que les accès au cache après son remplissage à cette adresse ne comportent qu'une seule correspondance d'indication. Étant donné que les indications virtuelles possèdent moins de bits de distinction que les étiquettes virtuelles, un cache utilisant des indications virtuelles subit davantage de défauts de cache liés à des conflits qu'un cache à étiquettes virtuelles.
La réduction ultime des indications virtuelles se trouve peut-être dans le Pentium 4 (cœurs Willamette et Northwood). Sur ces processeurs, l'indication virtuelle est réduite à deux bits et le cache est associatif par ensembles à quatre voies. Concrètement, le matériel maintient une simple permutation entre l'adresse virtuelle et l'index du cache, ce qui rend inutile l'utilisation de la mémoire associative (CAM) pour sélectionner la bonne adresse parmi les quatre voies d'accès.
Coloriage
l'optimisation des boucles imbriquées ), notamment dans le domaine du calcul haute performance (HPC) .Le problème, c'est que si toutes les pages utilisées à un instant donné peuvent avoir des couleurs virtuelles différentes, certaines peuvent avoir la même couleur physique. En fait, si le système d'exploitation attribue des pages physiques aux pages virtuelles de manière aléatoire et uniforme, il est fort probable que certaines pages aient la même couleur physique, et que les adresses de ces pages entrent alors en conflit dans le cache (c'est le paradoxe des anniversaires ).
La solution consiste à ce que le système d'exploitation tente d'attribuer des couleurs physiques différentes à des couleurs virtuelles différentes, une technique appelée coloration des pages . Bien que la correspondance exacte entre les couleurs virtuelles et physiques soit sans incidence sur les performances du système, les correspondances complexes sont difficiles à gérer et présentent peu d'avantages. C'est pourquoi la plupart des méthodes de coloration des pages visent simplement à conserver les mêmes couleurs physiques et virtuelles.
Si le système d'exploitation garantit que chaque page physique correspond à une seule couleur virtuelle, il n'y a pas d'alias virtuels et le processeur peut utiliser des caches indexés virtuellement sans avoir besoin de sondes d'alias virtuels supplémentaires lors de la gestion des défauts. Le système d'exploitation peut également vider le cache d'une page à chaque changement de couleur virtuelle. Comme indiqué précédemment, cette approche a été utilisée dans certaines architectures SPARC et RS/6000 de première génération.
La technique de coloration logicielle des pages a été utilisée pour partitionner efficacement le cache de dernier niveau (LLC) partagé dans les processeurs multicœurs. Cette gestion du LLC basée sur le système d'exploitation dans les processeurs multicœurs a été adoptée par Intel.
Hiérarchie de mémoire d'un serveur AMD Bulldozer Les processeurs modernes possèdent plusieurs caches sur puce interagissant entre eux. Le fonctionnement d'un cache particulier peut être entièrement spécifié par sa taille, la taille des blocs de cache, le nombre de blocs dans un ensemble, la politique de remplacement des ensembles de cache et la politique d'écriture du cache (écriture immédiate ou écriture différée).
Bien que tous les blocs d'un cache donné aient la même taille et la même associativité, les caches de « niveau supérieur » (appelés caches de niveau 1) possèdent généralement un nombre de blocs plus faible, une taille de bloc plus petite et un ensemble de blocs plus restreint, mais offrent des temps d'accès très courts. Les caches de « niveau inférieur » (c'est-à-dire de niveau 2 et inférieurs) possèdent un nombre de blocs progressivement plus important, une taille de bloc plus grande, un ensemble de blocs plus dense et des temps d'accès relativement plus longs, mais restent beaucoup plus rapides que la mémoire principale.
La politique de remplacement des entrées du cache est déterminée par un algorithme de cache choisi par les concepteurs du processeur. Dans certains cas, plusieurs algorithmes sont proposés pour différents types de charges de travail.
Caches spécialisées
Les processeurs pipelinés accèdent à la mémoire à partir de plusieurs points du pipeline : extraction des instructions, traduction d'adresses virtuelles en adresses physiques et extraction des données (voir le pipeline RISC classique ). Naturellement, on utilise des caches physiques différents pour chacun de ces points, afin qu'une même ressource physique ne soit pas affectée à deux points du pipeline. Le pipeline comporte ainsi naturellement au moins trois caches distincts (instructions, TLB et données), chacun spécialisé dans son rôle spécifique.
Cache de victimes
Norman Jouppi de DEC en 1990. La variante Crystalwell des processeurs Haswell d'Intel intégrait un cache eDRAM de niveau 4 de 128 Mio , servant de cache victime au cache de niveau 3 du processeur. Dans la microarchitecture Skylake, le cache de niveau 4 ne fonctionne plus comme cache victime.
Intel Pentium 4. Un cache de traces est un mécanisme permettant d'augmenter la bande passante de récupération des instructions et de diminuer la consommation d'énergie (dans le cas du Pentium 4) en stockant les traces des instructions qui ont déjà été récupérées et décodées. Un cache de traces stocke les instructions soit après leur décodage, soit au fur et à mesure de leur suppression. Généralement, les instructions sont ajoutées aux caches de traces par groupes représentant soit des blocs de base individuels , soit des traces d'instructions dynamiques. Le cache de traces du Pentium 4 stocke les micro-opérations résultant du décodage des instructions x86, offrant ainsi la fonctionnalité d'un cache de micro-opérations. Grâce à cela, la prochaine fois qu'une instruction sera nécessaire, il ne sera pas nécessaire de la décoder à nouveau en micro-opérations.
Cache de fusion d'écriture (WCC)
Le cache de coalescence d'écriture (WCC ) est un cache spécial faisant partie du cache L2 de la microarchitecture Bulldozer d' AMD . Les données écrites provenant des deux caches L1D du module transitent par le WCC, où elles sont mises en mémoire tampon et fusionnées. Le WCC a pour fonction de réduire le nombre d'écritures dans le cache L2.
les micro-opérations des instructions décodées, telles que reçues directement des décodeurs d'instructions ou du cache d'instructions. Lorsqu'une instruction doit être décodée, le cache μop vérifie si sa forme décodée s'y trouve ; si elle n'est pas disponible, l'instruction est décodée puis mise en cache.L'un des premiers travaux décrivant le cache μop comme une interface alternative pour la famille de processeurs Intel P6 est l'article de 2001 intitulé « Micro-Operation Cache: A Power Aware Frontend for Variable Instruction Length ISA » . Par la suite, Intel a intégré des caches μop dans ses processeurs Sandy Bridge et dans les microarchitectures successives telles qu'Ivy Bridge et Haswell : a implémenté un cache μop dans sa microarchitecture Zen .
L'accès à des instructions complètes pré-décodées élimine la nécessité de décoder à répétition des instructions complexes de longueur variable en micro-opérations plus simples de longueur fixe, et simplifie le processus de prédiction, d'accès, de rotation et d'alignement des instructions récupérées. Un cache de micro-opérations décharge efficacement le matériel d'accès et de décodage, réduisant ainsi la consommation d'énergie et améliorant la fourniture de micro-opérations décodées au processeur. Le cache de micro-opérations améliore également les performances en fournissant de manière plus constante les micro-opérations décodées au processeur et en éliminant divers goulots d'étranglement dans la logique d'accès et de décodage du processeur.
Un cache μop présente de nombreuses similitudes avec un cache de traces, mais il est beaucoup plus simple, ce qui lui confère une meilleure efficacité énergétique ; il est donc mieux adapté aux implémentations sur des appareils alimentés par batterie. Le principal inconvénient du cache de traces, à l’origine de son inefficacité énergétique, réside dans la complexité matérielle requise pour son heuristique de décision concernant la mise en cache et la réutilisation des traces d’instructions créées dynamiquement.
cache d'instructions de la cible de branchement
Un cache de cible de branchement , ou cache d'instructions de cible de branchement (nom utilisé sur les microprocesseurs ARM ) est un cache spécialisé qui stocke les premières instructions à l'adresse de destination d'un branchement. Il est utilisé par les processeurs basse consommation qui n'ont pas besoin d'un cache d'instructions classique, car leur système mémoire est capable de fournir les instructions suffisamment rapidement pour satisfaire le processeur. Cependant, cela ne s'applique qu'aux instructions consécutives ; le redémarrage de la récupération d'une instruction à une nouvelle adresse nécessite toujours plusieurs cycles de latence, ce qui provoque une brève oscillation du pipeline après un transfert de contrôle. Un cache de cible de branchement fournit les instructions pour ces quelques cycles, évitant ainsi un délai après la plupart des branchements.
Cela permet un fonctionnement à pleine vitesse avec un cache beaucoup plus petit qu'un cache d'instructions traditionnel à temps plein.
Cache intelligent
Le cache intelligent est une méthode de mise en cache de niveau 2 ou 3 pour plusieurs cœurs d'exécution, développée par Intel .
Le cache intelligent partage la mémoire cache entre les cœurs d'un processeur multicœur . Comparé à un cache dédié par cœur, le taux global d'échecs de cache diminue lorsque les cœurs n'ont pas besoin de parts égales de l'espace cache. Par conséquent, un seul cœur peut utiliser la totalité du cache de niveau 2 ou 3 tandis que les autres cœurs sont inactifs. De plus, le cache partagé accélère le partage de mémoire entre les différents cœurs d'exécution.
eDRAM et montés sur un module multi-puces , constituant ainsi un quatrième niveau de cache. Dans de rares cas, comme pour le processeur du mainframe IBM z15 (2019), tous les niveaux jusqu'au cache L1 sont implémentés en eDRAM, remplaçant entièrement la SRAM (pour le cache, la SRAM étant toujours utilisée pour les registres ). La gamme de processeurs Apple Silicon , basée sur l'architecture ARM et comprenant les A14 et M1 , dispose d'un cache L1i de 192 Kio pour chacun des cœurs hautes performances, une capacité exceptionnellement élevée ; en revanche, les cœurs basse consommation ne disposent que de 128 Kio. Depuis, d'autres processeurs tels que Lunar Lake d' Intel et Oryon de Qualcomm ont également implémenté des tailles de cache L1i similaires.Les avantages des caches L3 et L4 dépendent des modèles d'accès de l'application. Voici quelques exemples de produits intégrant des caches L3 et L4 :
- Alpha 21164 (1995) disposait d'un cache L3 hors puce de 1 à 64 Mio.
- L'AMD K6-III (1999) disposait d'un cache L3 basé sur la carte mère.
- IBM POWER4 (2001) disposait de caches L3 hors puce de 32 Mio par processeur, partagés entre plusieurs processeurs.
- L'Itanium 2 (2003) disposait d'un cache Itanium 2 (2003) MX 2 incorporait deux processeurs Itanium 2 ainsi qu'un cache L4 partagé de 64 Mio sur un module multi-puces compatible broche à broche avec un processeur Madison.
- Le produit Intel Xeon MP, nom de code « Tulsa » (2006), dispose de 16 Mio de cache L3 intégré partagé entre deux cœurs de processeur.
- AMD Phenom (2007) avec 2 Mio de cache L3.
- L'AMD Phenom II (2008) dispose d'un cache L3 unifié sur puce allant jusqu'à 6 Mio.
- Intel Core i7 (2008) possède un cache L3 unifié sur puce de 8 Mio, inclusif et partagé par tous les cœurs.
- Les processeurs Intel Haswell avec carte graphique intégrée Intel Iris Pro disposent de 128 Mio d'eDRAM faisant essentiellement office de cache L4.
Enfin, à l'autre extrémité de la hiérarchie mémoire, le fichier de registres du processeur peut être considéré comme le cache le plus petit et le plus rapide du système. Sa particularité réside dans le fait qu'il est géré par logiciel, généralement par le compilateur, qui alloue des registres pour stocker les valeurs extraites de la mémoire principale, par exemple pour l'optimisation des boucles imbriquées . Cependant, grâce au renommage des registres , la plupart des affectations de registres du compilateur sont réallouées dynamiquement par le matériel à l'exécution dans un banc de registres, permettant ainsi au processeur de rompre les dépendances de données erronées et d'atténuer les risques liés au pipeline.
Les fichiers de registres présentent parfois une hiérarchie : le Cray-1 (vers 1976) disposait de huit registres d’adresse « A » et de huit registres de données scalaires « S » généralement utilisables. Il comportait également 64 registres d’adresse « B » et 64 registres de données scalaires « T », dont l’accès était plus lent, mais plus rapide que la mémoire principale. Les registres « B » et « T » étaient nécessaires car le Cray-1 ne possédait pas de cache de données. (Le Cray-1 disposait toutefois d’un cache d’instructions.)
multicœur , la question se pose de savoir si les caches doivent être partagés ou locaux à chaque cœur. La mise en œuvre d'un cache partagé engendre inévitablement un câblage plus complexe. En revanche, disposer d'un cache par puce , plutôt que par cœur , réduit considérablement l'espace nécessaire et permet ainsi d'intégrer un cache de plus grande capacité.En règle générale, le partage du cache L1 est déconseillé car l'augmentation de latence qui en résulte ralentirait considérablement chaque cœur par rapport à une puce monocœur. Cependant, pour le cache de plus haut niveau (généralement L3, le dernier appelé avant l'accès à la mémoire), un cache global est souhaitable pour plusieurs raisons : il permet à un seul cœur d'utiliser l'intégralité du cache, réduit la redondance des données en autorisant différents processus ou threads à partager les données mises en cache, et simplifie les protocoles de cohérence de cache utilisés. Par exemple, une puce à huit cœurs avec trois niveaux de cache peut inclure un cache L1 par cœur, un cache L2 intermédiaire pour chaque paire de cœurs et un cache L3 partagé par tous les cœurs.
Un cache de niveau le plus élevé partagé (généralement L3, appelé avant l'accès à la mémoire) est généralement désigné sous le nom de cache de dernier niveau (LLC). Des techniques supplémentaires sont utilisées pour augmenter le niveau de parallélisme lorsque le LLC est partagé entre plusieurs cœurs, notamment en le divisant en plusieurs morceaux qui adressent des plages d'adresses mémoire spécifiques et peuvent être utilisés indépendamment.
Séparés versus unifiés
Dans une structure de cache séparée, les instructions et les données sont mises en cache séparément ; une ligne de cache sert donc soit aux instructions, soit aux données, mais pas aux deux. L’utilisation de tampons de traduction d’instructions et de données distincts présente divers avantages . Dans une structure unifiée, cette contrainte disparaît et les lignes de cache peuvent servir à la fois aux instructions et aux données.
AMD Athlon ) utilisent des caches exclusifs : les données sont garanties de se trouver dans au plus l'un des caches L1 ou L2, jamais dans les deux. D'autres processeurs encore (comme les Intel Pentium II , III et 4 ) n'exigent pas que les données du cache L1 résident également dans le cache L2, bien que cela soit souvent le cas. Il n'existe pas de nom universellement accepté pour cette politique intermédiaire ; deux appellations courantes sont « non exclusif » et « partiellement inclusif ».L’avantage des caches exclusifs réside dans leur capacité de stockage supérieure. Cet avantage est plus marqué lorsque le cache L1 exclusif est comparable au cache L2, et diminue si le cache L2 est beaucoup plus grand que le cache L1. En cas d’échec d’accès dans le cache L1 et de succès dans le cache L2, la ligne correspondante dans le cache L2 est échangée avec une ligne du cache L1. Cet échange est beaucoup plus complexe que la simple copie d’une ligne du cache L2 vers le cache L1, opération effectuée par un cache inclusif.
L'un des avantages des caches strictement inclusifs est que, lorsqu'un périphérique externe ou un autre processeur d'un système multiprocesseur souhaite supprimer une ligne de cache du processeur, il suffit que ce dernier consulte le cache L2. Dans les hiérarchies de caches n'imposant pas l'inclusion, le cache L1 doit également être consulté. En revanche, il existe une corrélation entre les associativités des caches L1 et L2 : si le cache L2 ne possède pas au moins autant de voies que l'ensemble des caches L1, l'associativité effective de ces derniers est limitée. Un autre inconvénient des caches inclusifs est que, lors de toute éviction dans le cache L2, les lignes (potentiellement) correspondantes dans le cache L1 doivent également être évincées afin de maintenir l'inclusivité. Cette opération est conséquente et entraîne un taux d'échecs de cache L1 plus élevé.
Un autre avantage des caches inclusifs est que le cache principal peut utiliser des lignes de cache plus larges, ce qui réduit la taille des étiquettes du cache secondaire. (Les caches exclusifs exigent que les deux caches aient des lignes de cache de même taille, afin que les lignes puissent être permutées en cas d'échec de cache L1 et de succès de cache L2.) Si le cache secondaire est dix fois plus grand que le cache principal, et que les données du cache sont dix fois plus grandes que les étiquettes de cache, la surface d'étiquettes ainsi économisée peut être comparable à la surface incrémentale nécessaire pour stocker les données du cache L1 dans le cache L2.
Mémoire du bloc-notes
La mémoire scratchpad (SPM), également connue sous le nom de mémoire scratchpad, mémoire RAM scratchpad ou mémoire locale dans la terminologie informatique, est une mémoire interne à haute vitesse utilisée pour le stockage temporaire de calculs, de données et d'autres travaux en cours.Exemple : le K8
Pour illustrer à la fois la spécialisation et la mise en cache multiniveau, voici la hiérarchie de cache du cœur K8 du processeur AMD Athlon 64.
Hiérarchie du cache du cœur K8 du processeur AMD Athlon 64 Le K8 possède quatre caches spécialisés : un cache d’instructions, un TLB d’instructions , un TLB de données et un cache de données. Chacun de ces caches est spécialisé :
- Le cache d'instructions conserve des copies de lignes de mémoire de 64 octets et en extrait 16 à chaque cycle. Chaque octet de ce cache est stocké sur dix bits au lieu de huit, les bits supplémentaires marquant les limites des instructions (il s'agit d'un exemple de prédécodage). Le cache utilise uniquement la parité plutôt que la correction d'erreurs (ECC ), car la parité est plus petite et toute donnée corrompue peut être remplacée par des données fraîches extraites de la mémoire (qui contient toujours une copie à jour des instructions).
- Le TLB d'instructions conserve des copies des entrées de table des pages (PTE). À chaque cycle, l'adresse virtuelle de chaque instruction est traduite par ce TLB en une adresse physique. Chaque entrée occupe quatre ou huit octets en mémoire. Le K8 ayant une taille de page variable, chaque TLB est divisé en deux sections : l'une pour les PTE correspondant à des pages de 4 Kio, l'autre pour celles correspondant à des pages de 4 Mio ou 2 Mio. Cette division simplifie le circuit d'association dans chaque section. Le système d'exploitation associe des PTE de tailles différentes aux différentes sections de l'espace d'adressage virtuel.
- Le TLB de données possède deux copies contenant des entrées identiques. Ces deux copies permettent deux accès aux données par cycle pour traduire les adresses virtuelles en adresses physiques. À l'instar du TLB d'instructions, ce TLB est divisé en deux types d'entrées.
- Le cache de données conserve des copies de lignes de mémoire de 64 octets. Il est divisé en 8 banques (chacune stockant 8 Kio de données) et peut accéder à deux ensembles de données de 8 octets par cycle, à condition qu'ils se trouvent dans des banques différentes. Il existe deux copies des étiquettes, car chaque ligne de 64 octets est répartie entre les huit banques. Chaque copie d'étiquette gère l'un des deux accès par cycle.
Le K8 dispose également de caches à plusieurs niveaux. Il existe des TLB d'instructions et de données de second niveau, qui stockent uniquement des entrées de table de pages (PTE) mappant 4 KiB. Les caches d'instructions et de données, ainsi que les différents TLB, peuvent être alimentés par le vaste cache L2 unifié . Ce cache est exclusif aux caches d'instructions et de données L1, ce qui signifie que toute ligne de 8 octets ne peut se trouver que dans l'un des caches suivants : le cache d'instructions L1, le cache de données L1 ou le cache L2. Il est toutefois possible qu'une ligne du cache de données contienne une PTE présente également dans l'un des TLB ; le système d'exploitation assure la cohérence des TLB en vidant certaines portions de ces derniers lors de la mise à jour des tables de pages en mémoire.
Le K8 met également en cache des informations qui ne sont jamais stockées en mémoire : les informations de prédiction. Ces caches ne sont pas représentés sur le schéma ci-dessus. Comme c'est souvent le cas pour ce type de processeur, le K8 dispose d'une prédiction de branchement assez complexe , avec des tables permettant de prédire si des branchements seront effectués et d'autres tables prédisant les cibles des branchements et des sauts. Certaines de ces informations sont associées aux instructions, à la fois dans le cache d'instructions de niveau 1 et dans le cache secondaire unifié.
Le K8 utilise une astuce ingénieuse pour stocker les informations de prédiction avec les instructions dans le cache secondaire. Les lignes de ce cache sont protégées contre toute corruption accidentelle de données (par exemple, suite à l'impact d'une particule alpha ) par un système de correction d'erreurs (ECC) ou par parité , selon qu'elles proviennent du cache principal de données ou d'instructions. Le code de parité occupant moins de bits que le code ECC, les lignes du cache d'instructions disposent de quelques bits supplémentaires. Ces bits servent à stocker les informations de prédiction de branchement associées à ces instructions. Il en résulte un historique de branchement plus étendu pour le prédicteur de branchement, et donc une meilleure précision.
Plus de hiérarchies
D'autres processeurs disposent d'autres types de prédicteurs (par exemple, le prédicteur de contournement de stockage à chargement dans le DEC Alpha 21264 ).
Ces prédicteurs sont des caches, car ils stockent des informations dont le calcul est coûteux. Certains termes employés pour parler des prédicteurs sont les mêmes que ceux utilisés pour les caches (on parle par exemple de « succès » dans un prédicteur de branchement), mais les prédicteurs ne sont généralement pas considérés comme faisant partie de la hiérarchie des caches.
Le K8 assure la cohérence matérielle des caches d'instructions et de données, ce qui signifie qu'une instruction de stockage effectuée juste après une autre modifiera l'instruction suivante. D'autres processeurs, comme ceux des familles Alpha et MIPS, s'appuient sur le logiciel pour maintenir la cohérence du cache d'instructions. L'affichage des instructions de stockage dans le flux d'instructions n'est garanti que lorsqu'un programme appelle une fonction du système d'exploitation pour assurer cette cohérence.
Étiquette RAM
Tag RAM sur la carte d'un Intel Pentium III En génie informatique, une mémoire RAM étiquetée permet de spécifier quelle adresse mémoire est actuellement stockée dans le cache du processeur. Pour une conception simple à correspondance directe, une SRAM rapide peut être utilisée. Les caches associatifs de niveau supérieur utilisent généralement une mémoire adressable par contenu .
Mise en œuvre
Chemin de lecture pour un cache associatif à deux voies Le schéma ci-contre vise à clarifier l'utilisation des différents champs de l'adresse. Le bit 31 est le plus significatif, le bit 0 le moins significatif. Ce schéma représente les SRAM, l'indexation et le multiplexage d'un cache de 4 Kio, associatif par ensembles à deux voies, indexé et étiqueté virtuellement, avec des lignes de 64 octets (B), une largeur de lecture de 32 bits et une adresse virtuelle de 32 bits.
Le cache ayant une capacité de 4 KiB et comportant 64 lignes d'octets, il ne contient que 64 lignes. La lecture s'effectue par paires à partir d'une SRAM d'étiquettes de 32 lignes, chacune associée à une paire d'étiquettes de 21 bits. Bien que toute fonction des bits d'adresse virtuelle 31 à 6 puisse être utilisée pour indexer les SRAM d'étiquettes et de données, l'utilisation des bits de poids faible est plus simple.
De même, étant donné que le cache fait 4 KiB et possède un chemin de lecture de 4 B, et qu'il lit de deux manières pour chaque accès, la SRAM de données comporte 512 lignes de 8 octets de large.
Un cache plus moderne pourrait avoir une capacité de 16 Kio, être associatif par ensembles à 4 voies, indexé virtuellement, avec des indications virtuelles et un marquage physique, avec des lignes de 32 octets, une largeur de lecture de 32 bits et des adresses physiques de 36 bits. Le chemin de lecture pour un tel cache est très similaire à celui décrit précédemment. Au lieu d'étiquettes, ce sont des indications virtuelles qui sont lues et comparées à un sous-ensemble de l'adresse virtuelle. Plus tard dans le pipeline, l'adresse virtuelle est traduite en adresse physique par le TLB, et l'étiquette physique correspondante est lue (une seule, car l'indication virtuelle indique le sens de lecture dans le cache). Enfin, l'adresse physique est comparée à l'étiquette physique pour déterminer si une correspondance a été trouvée.
Certaines conceptions SPARC ont amélioré la vitesse de leurs caches L1 de quelques délais de porte en intégrant l'additionneur d'adresses virtuelles dans les décodeurs SRAM.aux registres . Mais depuis les années 1980 l'écart de performance entre le processeur et la mémoire n'a cessé de se creuser. Les microprocesseurs ont progressé beaucoup plus vite que la mémoire, notamment en termes de fréquence de fonctionnement , faisant de cette dernière un goulot d'étranglement. S'il était techniquement possible d'avoir une mémoire principale aussi rapide que le processeur, une solution plus économique a été privilégiée : utiliser une grande quantité de mémoire basse vitesse, tout en intégrant une petite mémoire cache haute vitesse pour compenser l'écart de performance. Cette approche a permis d'obtenir une capacité dix fois supérieure – pour un coût identique – avec une légère diminution des performances globales.
Premières implémentations TLB
Les premières utilisations documentées d'un TLB ont eu lieu sur le GE 645 et l' IBM 360/67 , qui utilisaient tous deux une mémoire associative comme TLB.
Cache de première instruction
La première utilisation documentée d'un cache d'instructions a eu lieu sur le CDC 6600.
Premier cache de données
La première utilisation documentée d'un cache de données a eu lieu sur le système IBM System/360 modèle 85.
Dans les microprocesseurs 68k
Le 68010 , sorti en 1982, dispose d'un « mode boucle » pouvant être considéré comme un cache d'instructions réduit et spécifique, accélérant les boucles composées de seulement deux instructions. Le 68020 , sorti en 1984, a remplacé ce mode par un cache d'instructions classique de 256 octets, devenant ainsi le premier processeur de la série 68k à intégrer une véritable mémoire cache sur puce.
Le 68030 , sorti en 1987, est essentiellement un cœur 68020 avec un cache de données supplémentaire de 256 octets, une unité de gestion de la mémoire sur puce (MMU), une réduction de processus et un mode rafale ajouté pour les caches.
Le 68040 , sorti en 1990, possède des caches d'instructions et de données séparés de quatre kilo-octets chacun.
Le 68060 , sorti en 1994, possède les éléments suivants : cache de données de 8 KiB (associatif à quatre voies), cache d'instructions de 8 KiB (associatif à quatre voies), tampon d'instructions FIFO de 96 octets, cache de branchement de 256 entrées et tampon MMU de cache de traduction d'adresses de 64 entrées (associatif à quatre voies).
Dans les microprocesseurs x86
Exemple de carte mère avec un microprocesseur i386 (33 MHz), 64 KiB de cache (25 ns ; 8 puces dans le coin inférieur gauche), 2 Mio de DRAM (70 ns ; 8 SIMM à droite du cache) et un contrôleur de cache ( Austek A38202 ; à droite du processeur). Avec l'arrivée des microprocesseurs x86 à des fréquences d'horloge de 20 MHz et plus (notamment l' A386) , de petites quantités de mémoire cache rapide ont commencé à être intégrées aux systèmes pour améliorer leurs performances. En effet, la DRAM utilisée comme mémoire principale présentait une latence importante, pouvant atteindre 120 ns, ainsi que des cycles de rafraîchissement. Le cache était constitué de cellules de mémoire SRAM , plus coûteuses mais nettement plus rapides, dont la latence était alors de l'ordre de 10 à 25 ns. Les premiers caches étaient externes au processeur et généralement situés sur la carte mère sous la forme de huit ou neuf composants DIP insérés dans des supports, permettant ainsi d'ajouter le cache en option ou de l'étendre.
Certaines versions du processeur Intel 386 pouvaient prendre en charge de 16 à 256 KiB de cache externe.
Avec le processeur 486 , un cache de 8 Kio était intégré directement à la puce. Ce cache était appelé cache de niveau 1 (L1) pour le différencier du cache de niveau 2 (L2), plus lent et situé sur la carte mère. Ces derniers étaient beaucoup plus volumineux, la taille la plus courante étant de 256 Kio. Certaines cartes mères disposaient d'emplacements pour la carte fille Intel 485Turbocache , dotée de 64 ou 128 Ko de mémoire cache. La popularité du cache sur carte mère s'est maintenue durant l' ère Pentium MMX , mais a été rendue obsolète par l'introduction de la SDRAM et l'écart croissant entre les fréquences d'horloge du bus et du processeur, ce qui a fait que le cache sur carte mère n'était plus que légèrement plus rapide que la mémoire principale.
L'évolution suivante en matière d'implémentation de cache dans les microprocesseurs x86 a commencé avec le Pentium Pro , qui a intégré le cache secondaire dans le même boîtier que le microprocesseur, cadencé à la même fréquence que ce dernier.
Les caches intégrés à la carte mère ont longtemps bénéficié d'une grande popularité grâce aux processeurs AMD K6-2 et AMD K6-III , qui utilisaient encore le socket 7 , précédemment employé par Intel avec des caches intégrés. Le K6-III intégrait 256 Kio de cache L2 et exploitait le cache intégré comme cache de troisième niveau, appelé L3 (des cartes mères avec jusqu'à 2 Mio de cache intégré ont été produites). Après l'obsolescence du socket 7, le cache intégré à la carte mère a disparu des systèmes x86.
Les caches à trois niveaux ont été réutilisés pour la première fois avec l'introduction du processeur Intel Xeon MP « Foster Core » , où le cache L3 a été ajouté à la puce du processeur. Il est devenu courant que la taille totale du cache augmente avec les nouvelles générations de processeurs, et récemment (en 2011), il n'est pas rare de trouver des caches de niveau 3 de plusieurs dizaines de mégaoctets
Intel a introduit un cache de niveau 4 intégré avec la microarchitecture Haswell . Les processeurs Crystalwell Haswell, équipés de la variante GT3e du processeur graphique intégré Intel Iris Pro, disposent de 128 Mio de mémoire DRAM embarquée ( eDRAM ) sur le même boîtier. Ce cache L4 est partagé dynamiquement entre le GPU et le CPU intégrés, et sert de cache victime au cache L3 du CPU.
Dans les microprocesseurs ARM
Le processeur Apple M1 dispose de 128 ou 192 Kio de cache d'instructions L1 par cœur (important pour la latence et les performances monocœur), selon le type de cœur. Il s'agit d'un cache L1 exceptionnellement important pour un processeur (et pas seulement pour un ordinateur portable). La taille totale de la mémoire cache n'est pas particulièrement élevée pour un ordinateur portable (c'est le total qui importe le plus pour le débit), et des tailles totales bien supérieures (par exemple, L3 ou L4) sont disponibles sur les ordinateurs centraux IBM.
Recherches actuelles
Les premières conceptions de cache se concentraient exclusivement sur le coût direct du cache et de la RAM , ainsi que sur la vitesse d'exécution moyenne. Les conceptions de cache plus récentes prennent également en compte l'efficacité énergétique , la tolérance aux pannes et d'autres objectifs.
Plusieurs outils sont à la disposition des architectes informatiques pour les aider à explorer les compromis entre le temps de cycle du cache, l'énergie et la surface ; le simulateur de cache CACTI et le simulateur de jeu d'instructions SimpleScalar sont deux options open-source.
Cache multiport
Un cache multiport est un cache capable de traiter plusieurs requêtes simultanément. Alors qu'un cache traditionnel utilise généralement une seule adresse mémoire, un cache multiport peut permettre de demander N adresses à la fois, N étant le nombre de ports connectés entre le processeur et le cache. L'avantage est qu'un processeur pipeliné peut accéder à la mémoire depuis différentes phases de son pipeline. Autre avantage : il rend possible le concept de processeurs superscalaires grâce à différents niveaux de cache.
Plus d articles de Worldlex Wiki
Revenez a l index pour explorer davantage de pages sur l histoire, la science, la culture, la geographie et la societe en francais.
Explorer l index
thread d'exécution , doit attendre (se bloquer) que l'instruction soit récupérée de la mémoire principale. Les défauts de lecture dans le cache de données entraînent généralement un délai plus court, car les instructions non dépendantes de la lecture peuvent être exécutées et poursuivre leur exécution jusqu'à ce que les données soient renvoyées par la mémoire principale, et les instructions dépendantes peuvent reprendre leur exécution. Les défauts d'écriture dans le cache de données entraînent généralement le délai le plus court, car l'écriture peut être mise en file d'attente et l'exécution des instructions suivantes est peu limitée ; le processeur peut continuer jusqu'à ce que la file d'attente soit pleine. Pour une présentation détaillée des types de défauts, consultez la section « Mesure et métriques des performances du cache » .mémoire virtuelle . En résumé, soit chaque programme exécuté sur la machine dispose de son propre espace d'adressage simplifié , contenant uniquement le code et les données de ce programme, soit tous les programmes s'exécutent dans un espace d'adressage virtuel commun. Un programme s'exécute en calculant, comparant, lisant et écrivant aux adresses de son espace d'adressage virtuel, plutôt qu'aux adresses de l'espace d'adressage physique, ce qui simplifie les programmes et facilite leur écriture.La mémoire virtuelle nécessite que le processeur traduise les adresses virtuelles générées par le programme en adresses physiques dans la mémoire principale. La partie du processeur qui effectue cette traduction est appelée unité de gestion de la mémoire (MMU). Le chemin rapide à travers la MMU peut effectuer ces traductions stockées dans le tampon de traduction (TLB), qui est un cache de correspondances entre la table des pages , la table des segments, ou les deux, du système d'exploitation .
Dans le cadre de la présente discussion, la traduction d'adresses présente trois caractéristiques importantes :
- Latence : L'adresse physique est disponible auprès de l'unité de gestion de la mémoire (MMU) un certain temps, peut-être quelques cycles, après que l'adresse virtuelle soit disponible auprès du générateur d'adresses.
- Gio peut être divisé en 1 048 576 pages de 4 Kio, chacune pouvant être mappée indépendamment. Plusieurs tailles de page peuvent être prises en charge ; voir la documentation sur la mémoire virtuelle pour plus de détails.
Un des premiers systèmes de mémoire virtuelle, l' IBM M44/44X , nécessitait un accès à une table de correspondance stockée en mémoire centrale avant chaque accès programmé à la mémoire principale. En l'absence de cache, et la mémoire de la table de correspondance fonctionnant à la même vitesse que la mémoire principale, la vitesse d'accès à la mémoire était ainsi réduite de moitié. Deux machines anciennes utilisant une table des pages en mémoire principale pour la correspondance, l' IBM System/360 Modèle 67 et le GE 645 , disposaient toutes deux d'une petite mémoire associative servant de cache pour les accès à la table des pages en mémoire. Ces deux machines sont antérieures à la première machine dotée d'un cache pour la mémoire principale, l' IBM System/360 Modèle 85 ; le premier cache matériel utilisé dans un système informatique n'était donc pas un cache de données ou d'instructions, mais un TLB (Time-Level Block).
Les caches peuvent être divisés en quatre types, selon que l'index ou l'étiquette corresponde à des adresses physiques ou virtuelles :
- Les caches à indexation physique et étiquetage physique (PIPT) utilisent l'adresse physique à la fois pour l'index et l'étiquette. Bien que cette méthode soit simple et évite les problèmes d'aliasing, elle est également lente, car l'adresse physique doit être recherchée (ce qui peut entraîner un défaut de bloc de liste et un accès à la mémoire principale) avant que cette adresse puisse être recherchée dans le cache.
- Les caches VIVT ( Virtually Indexed, Virtually Tagged ) utilisent l'adresse virtuelle à la fois comme index et comme étiquette. Ce schéma de cache permet des recherches beaucoup plus rapides, car il n'est pas nécessaire de consulter l'unité de gestion de la mémoire (MMU) au préalable pour déterminer l'adresse physique correspondant à une adresse virtuelle donnée. Cependant, les caches VIVT souffrent de problèmes d'aliasing : plusieurs adresses virtuelles différentes peuvent désigner la même adresse physique. Ces adresses sont alors mises en cache séparément, bien qu'elles pointent vers la même zone mémoire, ce qui engendre des problèmes de cohérence. Bien que des solutions existent elles ne sont pas compatibles avec les protocoles de cohérence standard. Un autre problème est celui des homonymes : une même adresse virtuelle peut correspondre à plusieurs adresses physiques différentes. Il est impossible de distinguer ces correspondances en se basant uniquement sur l'index virtuel. Parmi les solutions potentielles, on peut citer : le vidage du cache après un changement de contexte , l'obligation d'utiliser des espaces d'adressage non chevauchants et l'attribution d'un identifiant d'espace d'adressage (ASID) à l'adresse virtuelle. De plus, le problème de la modification des correspondances entre adresses virtuelles et physiques nécessite la vidange du cache, car les adresses virtuelles ne sont plus valides. Ces problèmes disparaissent lorsque les étiquettes utilisent des adresses physiques (VIPT).
- Les caches à indexation virtuelle et étiquetage physique (VIPT) utilisent l'adresse virtuelle pour l'index et l'adresse physique dans l'étiquette. L'avantage par rapport aux caches PIPT réside dans une latence réduite, car la recherche dans le cache peut être effectuée en parallèle avec la traduction TLB. Cependant, l'étiquette ne peut être comparée que lorsque l'adresse physique est disponible. L'avantage par rapport aux caches VIVT est que, grâce à l'étiquette contenant l'adresse physique, le cache peut détecter les homonymes. Théoriquement, les caches VIPT nécessitent davantage de bits d'étiquette, car certains bits d'index peuvent différer entre les adresses virtuelle et physique (par exemple, les bits 12 et suivants pour les pages de 4 Kio) et devraient être inclus à la fois dans l'index virtuel et dans l'étiquette physique. En pratique, cela ne pose pas de problème car, afin d'éviter les problèmes de cohérence, les caches VIPT sont conçus sans ces bits d'index (par exemple, en limitant le nombre total de bits pour l'index et le décalage de bloc à 12 pour les pages de 4 Kio) ; la taille des caches VIPT est ainsi limitée à la taille de la page multipliée par l'associativité du cache.
- Les caches à indexation physique et étiquetage virtuel (PIVT) sont souvent considérés dans la littérature comme inutiles et inexistants . Pourtant, le MIPS R6000 utilise ce type de cache comme seule implémentation connue . Le R6000 est implémenté en logique à couplage d'émetteur , une technologie extrêmement rapide, mais inadaptée aux grandes mémoires telles qu'un TLB . Le R6000 résout ce problème en plaçant la mémoire TLB dans une partie réservée du cache de second niveau, dotée d'une minuscule « tranche » TLB haute vitesse intégrée. Le cache est indexé par l'adresse physique obtenue à partir de cette tranche TLB. Cependant, comme la tranche TLB ne traduit que les bits d'adresse virtuelle nécessaires à l'indexation du cache et n'utilise aucun étiquetage, des accès non autorisés au cache peuvent se produire. Ce problème est résolu par l'étiquetage avec l'adresse virtuelle.
La vitesse de cette récurrence (la latence de chargement ) est cruciale pour les performances du processeur, et c'est pourquoi la plupart des caches de niveau 1 modernes sont virtuellement indexés, ce qui permet au moins à la recherche TLB de l'unité de gestion de la mémoire (MMU) de se dérouler en parallèle avec la récupération des données de la mémoire RAM du cache.
Cependant, l'indexation virtuelle n'est pas optimale pour tous les niveaux de cache. Le coût de la gestion des alias virtuels augmente avec la taille du cache ; c'est pourquoi la plupart des caches de niveau 2 et plus sont indexés physiquement.
Historiquement, les caches utilisaient à la fois des adresses virtuelles et physiques pour leurs étiquettes, bien que l'étiquetage virtuel soit aujourd'hui rare. Si la recherche dans le TLB peut se terminer avant celle dans la RAM du cache, l'adresse physique est disponible à temps pour la comparaison des étiquettes, et l'étiquetage virtuel devient inutile. Les grands caches sont donc généralement étiquetés physiquement, tandis que seuls les petits caches à très faible latence utilisent l'étiquetage virtuel. Dans les processeurs généralistes récents, l'étiquetage virtuel a été remplacé par des indications virtuelles, comme décrit ci-dessous.
Problèmes d'homonymie et de synonymie
Un cache reposant sur l'indexation et l'étiquetage virtuels devient incohérent lorsqu'une même adresse virtuelle est associée à différentes adresses physiques ( homonymie ). Ce problème peut être résolu en utilisant l'adresse physique pour l'étiquetage, ou en stockant l'identifiant de l'espace d'adressage dans la ligne de cache. Cependant, cette dernière approche ne résout pas le problème des synonymes , où plusieurs lignes de cache finissent par stocker des données pour la même adresse physique. L'écriture à ces emplacements peut ne mettre à jour qu'un seul emplacement dans le cache, laissant les autres avec des données incohérentes. Ce problème peut être résolu en utilisant des dispositions mémoire non chevauchantes pour différents espaces d'adressage, ou bien en vidant le cache (ou une partie de celui-ci) lors de tout changement d'association.
Étiquettes et indices virtuels
Le principal avantage des étiquettes virtuelles est que, pour les caches associatifs, elles permettent d'effectuer la correspondance des étiquettes avant la traduction virtuelle-physique. Cependant, les sondages de cohérence et les évictions fournissent une adresse physique pour l'action. Le matériel doit disposer d'un moyen de convertir les adresses physiques en un index de cache, généralement en stockant à la fois les étiquettes physiques et virtuelles. Par comparaison, un cache à étiquettes physiques n'a pas besoin de conserver d'étiquettes virtuelles, ce qui est plus simple. Lorsqu'une correspondance virtuelle-physique est supprimée du TLB, les entrées de cache associées à ces adresses virtuelles doivent être vidées. De même, si des entrées de cache sont autorisées sur des pages non mappées par le TLB, ces entrées doivent être vidées lorsque les droits d'accès à ces pages sont modifiés dans la table des pages.
Le système d'exploitation peut également garantir qu'aucun alias virtuel ne réside simultanément dans le cache. Il assure cette garantie en appliquant la coloration des pages, décrite ci-dessous. Certains processeurs RISC anciens (SPARC, RS/6000) utilisaient cette approche. Elle n'est plus employée aujourd'hui, car le coût matériel de la détection et de la suppression des alias virtuels a diminué, tandis que la complexité logicielle et la perte de performance liées à une coloration parfaite des pages ont augmenté.
Il peut être utile de distinguer les deux fonctions des étiquettes dans un cache associatif : elles servent à déterminer le sens de sélection de l’ensemble d’entrées, et elles servent à déterminer si la recherche a réussi ou échoué. La seconde fonction doit toujours être correcte, mais la première peut occasionnellement faire des suppositions et donner une réponse erronée.
Certains processeurs (par exemple, les premiers SPARC) possèdent des caches à la fois virtuels et physiques. Les étiquettes virtuelles servent à la sélection du chemin d'accès, tandis que les étiquettes physiques déterminent si l'accès a réussi ou échoué. Ce type de cache bénéficie de la faible latence d'un cache à étiquettes virtuelles et de la simplicité d'interface logicielle d'un cache à étiquettes physiques. Il présente toutefois l'inconvénient supplémentaire des étiquettes dupliquées. De plus, lors du traitement d'un échec d'accès, les chemins d'accès alternatifs de la ligne de cache indexée doivent être analysés afin de détecter les alias virtuels et d'éliminer toute correspondance.
L'espace supplémentaire (et la latence accrue) peut être atténué en conservant des indications virtuelles pour chaque entrée de cache, au lieu d'étiquettes virtuelles. Ces indications sont un sous-ensemble ou un hachage de l'étiquette virtuelle et servent à sélectionner la zone de cache à partir de laquelle récupérer les données et une étiquette physique. Comme pour un cache à étiquettes virtuelles, il peut y avoir une correspondance entre une indication virtuelle et une différence d'étiquette physique. Dans ce cas, l'entrée de cache avec l'indication correspondante doit être supprimée afin que les accès au cache après son remplissage à cette adresse ne comportent qu'une seule correspondance d'indication. Étant donné que les indications virtuelles possèdent moins de bits de distinction que les étiquettes virtuelles, un cache utilisant des indications virtuelles subit davantage de défauts de cache liés à des conflits qu'un cache à étiquettes virtuelles.
La réduction ultime des indications virtuelles se trouve peut-être dans le Pentium 4 (cœurs Willamette et Northwood). Sur ces processeurs, l'indication virtuelle est réduite à deux bits et le cache est associatif par ensembles à quatre voies. Concrètement, le matériel maintient une simple permutation entre l'adresse virtuelle et l'index du cache, ce qui rend inutile l'utilisation de la mémoire associative (CAM) pour sélectionner la bonne adresse parmi les quatre voies d'accès.
Coloriage
l'optimisation des boucles imbriquées ), notamment dans le domaine du calcul haute performance (HPC) .Le problème, c'est que si toutes les pages utilisées à un instant donné peuvent avoir des couleurs virtuelles différentes, certaines peuvent avoir la même couleur physique. En fait, si le système d'exploitation attribue des pages physiques aux pages virtuelles de manière aléatoire et uniforme, il est fort probable que certaines pages aient la même couleur physique, et que les adresses de ces pages entrent alors en conflit dans le cache (c'est le paradoxe des anniversaires ).
La solution consiste à ce que le système d'exploitation tente d'attribuer des couleurs physiques différentes à des couleurs virtuelles différentes, une technique appelée coloration des pages . Bien que la correspondance exacte entre les couleurs virtuelles et physiques soit sans incidence sur les performances du système, les correspondances complexes sont difficiles à gérer et présentent peu d'avantages. C'est pourquoi la plupart des méthodes de coloration des pages visent simplement à conserver les mêmes couleurs physiques et virtuelles.
Si le système d'exploitation garantit que chaque page physique correspond à une seule couleur virtuelle, il n'y a pas d'alias virtuels et le processeur peut utiliser des caches indexés virtuellement sans avoir besoin de sondes d'alias virtuels supplémentaires lors de la gestion des défauts. Le système d'exploitation peut également vider le cache d'une page à chaque changement de couleur virtuelle. Comme indiqué précédemment, cette approche a été utilisée dans certaines architectures SPARC et RS/6000 de première génération.
La technique de coloration logicielle des pages a été utilisée pour partitionner efficacement le cache de dernier niveau (LLC) partagé dans les processeurs multicœurs. Cette gestion du LLC basée sur le système d'exploitation dans les processeurs multicœurs a été adoptée par Intel.
Hiérarchie de mémoire d'un serveur AMD Bulldozer Les processeurs modernes possèdent plusieurs caches sur puce interagissant entre eux. Le fonctionnement d'un cache particulier peut être entièrement spécifié par sa taille, la taille des blocs de cache, le nombre de blocs dans un ensemble, la politique de remplacement des ensembles de cache et la politique d'écriture du cache (écriture immédiate ou écriture différée).
Bien que tous les blocs d'un cache donné aient la même taille et la même associativité, les caches de « niveau supérieur » (appelés caches de niveau 1) possèdent généralement un nombre de blocs plus faible, une taille de bloc plus petite et un ensemble de blocs plus restreint, mais offrent des temps d'accès très courts. Les caches de « niveau inférieur » (c'est-à-dire de niveau 2 et inférieurs) possèdent un nombre de blocs progressivement plus important, une taille de bloc plus grande, un ensemble de blocs plus dense et des temps d'accès relativement plus longs, mais restent beaucoup plus rapides que la mémoire principale.
La politique de remplacement des entrées du cache est déterminée par un algorithme de cache choisi par les concepteurs du processeur. Dans certains cas, plusieurs algorithmes sont proposés pour différents types de charges de travail.
Caches spécialisées
Les processeurs pipelinés accèdent à la mémoire à partir de plusieurs points du pipeline : extraction des instructions, traduction d'adresses virtuelles en adresses physiques et extraction des données (voir le pipeline RISC classique ). Naturellement, on utilise des caches physiques différents pour chacun de ces points, afin qu'une même ressource physique ne soit pas affectée à deux points du pipeline. Le pipeline comporte ainsi naturellement au moins trois caches distincts (instructions, TLB et données), chacun spécialisé dans son rôle spécifique.
Cache de victimes
Norman Jouppi de DEC en 1990. La variante Crystalwell des processeurs Haswell d'Intel intégrait un cache eDRAM de niveau 4 de 128 Mio , servant de cache victime au cache de niveau 3 du processeur. Dans la microarchitecture Skylake, le cache de niveau 4 ne fonctionne plus comme cache victime.
Intel Pentium 4. Un cache de traces est un mécanisme permettant d'augmenter la bande passante de récupération des instructions et de diminuer la consommation d'énergie (dans le cas du Pentium 4) en stockant les traces des instructions qui ont déjà été récupérées et décodées. Un cache de traces stocke les instructions soit après leur décodage, soit au fur et à mesure de leur suppression. Généralement, les instructions sont ajoutées aux caches de traces par groupes représentant soit des blocs de base individuels , soit des traces d'instructions dynamiques. Le cache de traces du Pentium 4 stocke les micro-opérations résultant du décodage des instructions x86, offrant ainsi la fonctionnalité d'un cache de micro-opérations. Grâce à cela, la prochaine fois qu'une instruction sera nécessaire, il ne sera pas nécessaire de la décoder à nouveau en micro-opérations.
Cache de fusion d'écriture (WCC)
Le cache de coalescence d'écriture (WCC ) est un cache spécial faisant partie du cache L2 de la microarchitecture Bulldozer d' AMD . Les données écrites provenant des deux caches L1D du module transitent par le WCC, où elles sont mises en mémoire tampon et fusionnées. Le WCC a pour fonction de réduire le nombre d'écritures dans le cache L2.
les micro-opérations des instructions décodées, telles que reçues directement des décodeurs d'instructions ou du cache d'instructions. Lorsqu'une instruction doit être décodée, le cache μop vérifie si sa forme décodée s'y trouve ; si elle n'est pas disponible, l'instruction est décodée puis mise en cache.L'un des premiers travaux décrivant le cache μop comme une interface alternative pour la famille de processeurs Intel P6 est l'article de 2001 intitulé « Micro-Operation Cache: A Power Aware Frontend for Variable Instruction Length ISA » . Par la suite, Intel a intégré des caches μop dans ses processeurs Sandy Bridge et dans les microarchitectures successives telles qu'Ivy Bridge et Haswell : a implémenté un cache μop dans sa microarchitecture Zen .
L'accès à des instructions complètes pré-décodées élimine la nécessité de décoder à répétition des instructions complexes de longueur variable en micro-opérations plus simples de longueur fixe, et simplifie le processus de prédiction, d'accès, de rotation et d'alignement des instructions récupérées. Un cache de micro-opérations décharge efficacement le matériel d'accès et de décodage, réduisant ainsi la consommation d'énergie et améliorant la fourniture de micro-opérations décodées au processeur. Le cache de micro-opérations améliore également les performances en fournissant de manière plus constante les micro-opérations décodées au processeur et en éliminant divers goulots d'étranglement dans la logique d'accès et de décodage du processeur.
Un cache μop présente de nombreuses similitudes avec un cache de traces, mais il est beaucoup plus simple, ce qui lui confère une meilleure efficacité énergétique ; il est donc mieux adapté aux implémentations sur des appareils alimentés par batterie. Le principal inconvénient du cache de traces, à l’origine de son inefficacité énergétique, réside dans la complexité matérielle requise pour son heuristique de décision concernant la mise en cache et la réutilisation des traces d’instructions créées dynamiquement.
cache d'instructions de la cible de branchement
Un cache de cible de branchement , ou cache d'instructions de cible de branchement (nom utilisé sur les microprocesseurs ARM ) est un cache spécialisé qui stocke les premières instructions à l'adresse de destination d'un branchement. Il est utilisé par les processeurs basse consommation qui n'ont pas besoin d'un cache d'instructions classique, car leur système mémoire est capable de fournir les instructions suffisamment rapidement pour satisfaire le processeur. Cependant, cela ne s'applique qu'aux instructions consécutives ; le redémarrage de la récupération d'une instruction à une nouvelle adresse nécessite toujours plusieurs cycles de latence, ce qui provoque une brève oscillation du pipeline après un transfert de contrôle. Un cache de cible de branchement fournit les instructions pour ces quelques cycles, évitant ainsi un délai après la plupart des branchements.
Cela permet un fonctionnement à pleine vitesse avec un cache beaucoup plus petit qu'un cache d'instructions traditionnel à temps plein.
Cache intelligent
Le cache intelligent est une méthode de mise en cache de niveau 2 ou 3 pour plusieurs cœurs d'exécution, développée par Intel .
Le cache intelligent partage la mémoire cache entre les cœurs d'un processeur multicœur . Comparé à un cache dédié par cœur, le taux global d'échecs de cache diminue lorsque les cœurs n'ont pas besoin de parts égales de l'espace cache. Par conséquent, un seul cœur peut utiliser la totalité du cache de niveau 2 ou 3 tandis que les autres cœurs sont inactifs. De plus, le cache partagé accélère le partage de mémoire entre les différents cœurs d'exécution.
eDRAM et montés sur un module multi-puces , constituant ainsi un quatrième niveau de cache. Dans de rares cas, comme pour le processeur du mainframe IBM z15 (2019), tous les niveaux jusqu'au cache L1 sont implémentés en eDRAM, remplaçant entièrement la SRAM (pour le cache, la SRAM étant toujours utilisée pour les registres ). La gamme de processeurs Apple Silicon , basée sur l'architecture ARM et comprenant les A14 et M1 , dispose d'un cache L1i de 192 Kio pour chacun des cœurs hautes performances, une capacité exceptionnellement élevée ; en revanche, les cœurs basse consommation ne disposent que de 128 Kio. Depuis, d'autres processeurs tels que Lunar Lake d' Intel et Oryon de Qualcomm ont également implémenté des tailles de cache L1i similaires.Les avantages des caches L3 et L4 dépendent des modèles d'accès de l'application. Voici quelques exemples de produits intégrant des caches L3 et L4 :
- Alpha 21164 (1995) disposait d'un cache L3 hors puce de 1 à 64 Mio.
- L'AMD K6-III (1999) disposait d'un cache L3 basé sur la carte mère.
- IBM POWER4 (2001) disposait de caches L3 hors puce de 32 Mio par processeur, partagés entre plusieurs processeurs.
- L'Itanium 2 (2003) disposait d'un cache Itanium 2 (2003) MX 2 incorporait deux processeurs Itanium 2 ainsi qu'un cache L4 partagé de 64 Mio sur un module multi-puces compatible broche à broche avec un processeur Madison.
- Le produit Intel Xeon MP, nom de code « Tulsa » (2006), dispose de 16 Mio de cache L3 intégré partagé entre deux cœurs de processeur.
- AMD Phenom (2007) avec 2 Mio de cache L3.
- L'AMD Phenom II (2008) dispose d'un cache L3 unifié sur puce allant jusqu'à 6 Mio.
- Intel Core i7 (2008) possède un cache L3 unifié sur puce de 8 Mio, inclusif et partagé par tous les cœurs.
- Les processeurs Intel Haswell avec carte graphique intégrée Intel Iris Pro disposent de 128 Mio d'eDRAM faisant essentiellement office de cache L4.
Enfin, à l'autre extrémité de la hiérarchie mémoire, le fichier de registres du processeur peut être considéré comme le cache le plus petit et le plus rapide du système. Sa particularité réside dans le fait qu'il est géré par logiciel, généralement par le compilateur, qui alloue des registres pour stocker les valeurs extraites de la mémoire principale, par exemple pour l'optimisation des boucles imbriquées . Cependant, grâce au renommage des registres , la plupart des affectations de registres du compilateur sont réallouées dynamiquement par le matériel à l'exécution dans un banc de registres, permettant ainsi au processeur de rompre les dépendances de données erronées et d'atténuer les risques liés au pipeline.
Les fichiers de registres présentent parfois une hiérarchie : le Cray-1 (vers 1976) disposait de huit registres d’adresse « A » et de huit registres de données scalaires « S » généralement utilisables. Il comportait également 64 registres d’adresse « B » et 64 registres de données scalaires « T », dont l’accès était plus lent, mais plus rapide que la mémoire principale. Les registres « B » et « T » étaient nécessaires car le Cray-1 ne possédait pas de cache de données. (Le Cray-1 disposait toutefois d’un cache d’instructions.)
multicœur , la question se pose de savoir si les caches doivent être partagés ou locaux à chaque cœur. La mise en œuvre d'un cache partagé engendre inévitablement un câblage plus complexe. En revanche, disposer d'un cache par puce , plutôt que par cœur , réduit considérablement l'espace nécessaire et permet ainsi d'intégrer un cache de plus grande capacité.En règle générale, le partage du cache L1 est déconseillé car l'augmentation de latence qui en résulte ralentirait considérablement chaque cœur par rapport à une puce monocœur. Cependant, pour le cache de plus haut niveau (généralement L3, le dernier appelé avant l'accès à la mémoire), un cache global est souhaitable pour plusieurs raisons : il permet à un seul cœur d'utiliser l'intégralité du cache, réduit la redondance des données en autorisant différents processus ou threads à partager les données mises en cache, et simplifie les protocoles de cohérence de cache utilisés. Par exemple, une puce à huit cœurs avec trois niveaux de cache peut inclure un cache L1 par cœur, un cache L2 intermédiaire pour chaque paire de cœurs et un cache L3 partagé par tous les cœurs.
Un cache de niveau le plus élevé partagé (généralement L3, appelé avant l'accès à la mémoire) est généralement désigné sous le nom de cache de dernier niveau (LLC). Des techniques supplémentaires sont utilisées pour augmenter le niveau de parallélisme lorsque le LLC est partagé entre plusieurs cœurs, notamment en le divisant en plusieurs morceaux qui adressent des plages d'adresses mémoire spécifiques et peuvent être utilisés indépendamment.
Séparés versus unifiés
Dans une structure de cache séparée, les instructions et les données sont mises en cache séparément ; une ligne de cache sert donc soit aux instructions, soit aux données, mais pas aux deux. L’utilisation de tampons de traduction d’instructions et de données distincts présente divers avantages . Dans une structure unifiée, cette contrainte disparaît et les lignes de cache peuvent servir à la fois aux instructions et aux données.
AMD Athlon ) utilisent des caches exclusifs : les données sont garanties de se trouver dans au plus l'un des caches L1 ou L2, jamais dans les deux. D'autres processeurs encore (comme les Intel Pentium II , III et 4 ) n'exigent pas que les données du cache L1 résident également dans le cache L2, bien que cela soit souvent le cas. Il n'existe pas de nom universellement accepté pour cette politique intermédiaire ; deux appellations courantes sont « non exclusif » et « partiellement inclusif ».L’avantage des caches exclusifs réside dans leur capacité de stockage supérieure. Cet avantage est plus marqué lorsque le cache L1 exclusif est comparable au cache L2, et diminue si le cache L2 est beaucoup plus grand que le cache L1. En cas d’échec d’accès dans le cache L1 et de succès dans le cache L2, la ligne correspondante dans le cache L2 est échangée avec une ligne du cache L1. Cet échange est beaucoup plus complexe que la simple copie d’une ligne du cache L2 vers le cache L1, opération effectuée par un cache inclusif.
L'un des avantages des caches strictement inclusifs est que, lorsqu'un périphérique externe ou un autre processeur d'un système multiprocesseur souhaite supprimer une ligne de cache du processeur, il suffit que ce dernier consulte le cache L2. Dans les hiérarchies de caches n'imposant pas l'inclusion, le cache L1 doit également être consulté. En revanche, il existe une corrélation entre les associativités des caches L1 et L2 : si le cache L2 ne possède pas au moins autant de voies que l'ensemble des caches L1, l'associativité effective de ces derniers est limitée. Un autre inconvénient des caches inclusifs est que, lors de toute éviction dans le cache L2, les lignes (potentiellement) correspondantes dans le cache L1 doivent également être évincées afin de maintenir l'inclusivité. Cette opération est conséquente et entraîne un taux d'échecs de cache L1 plus élevé.
Un autre avantage des caches inclusifs est que le cache principal peut utiliser des lignes de cache plus larges, ce qui réduit la taille des étiquettes du cache secondaire. (Les caches exclusifs exigent que les deux caches aient des lignes de cache de même taille, afin que les lignes puissent être permutées en cas d'échec de cache L1 et de succès de cache L2.) Si le cache secondaire est dix fois plus grand que le cache principal, et que les données du cache sont dix fois plus grandes que les étiquettes de cache, la surface d'étiquettes ainsi économisée peut être comparable à la surface incrémentale nécessaire pour stocker les données du cache L1 dans le cache L2.
Mémoire du bloc-notes
La mémoire scratchpad (SPM), également connue sous le nom de mémoire scratchpad, mémoire RAM scratchpad ou mémoire locale dans la terminologie informatique, est une mémoire interne à haute vitesse utilisée pour le stockage temporaire de calculs, de données et d'autres travaux en cours.Exemple : le K8
Pour illustrer à la fois la spécialisation et la mise en cache multiniveau, voici la hiérarchie de cache du cœur K8 du processeur AMD Athlon 64.
Hiérarchie du cache du cœur K8 du processeur AMD Athlon 64 Le K8 possède quatre caches spécialisés : un cache d’instructions, un TLB d’instructions , un TLB de données et un cache de données. Chacun de ces caches est spécialisé :
- Le cache d'instructions conserve des copies de lignes de mémoire de 64 octets et en extrait 16 à chaque cycle. Chaque octet de ce cache est stocké sur dix bits au lieu de huit, les bits supplémentaires marquant les limites des instructions (il s'agit d'un exemple de prédécodage). Le cache utilise uniquement la parité plutôt que la correction d'erreurs (ECC ), car la parité est plus petite et toute donnée corrompue peut être remplacée par des données fraîches extraites de la mémoire (qui contient toujours une copie à jour des instructions).
- Le TLB d'instructions conserve des copies des entrées de table des pages (PTE). À chaque cycle, l'adresse virtuelle de chaque instruction est traduite par ce TLB en une adresse physique. Chaque entrée occupe quatre ou huit octets en mémoire. Le K8 ayant une taille de page variable, chaque TLB est divisé en deux sections : l'une pour les PTE correspondant à des pages de 4 Kio, l'autre pour celles correspondant à des pages de 4 Mio ou 2 Mio. Cette division simplifie le circuit d'association dans chaque section. Le système d'exploitation associe des PTE de tailles différentes aux différentes sections de l'espace d'adressage virtuel.
- Le TLB de données possède deux copies contenant des entrées identiques. Ces deux copies permettent deux accès aux données par cycle pour traduire les adresses virtuelles en adresses physiques. À l'instar du TLB d'instructions, ce TLB est divisé en deux types d'entrées.
- Le cache de données conserve des copies de lignes de mémoire de 64 octets. Il est divisé en 8 banques (chacune stockant 8 Kio de données) et peut accéder à deux ensembles de données de 8 octets par cycle, à condition qu'ils se trouvent dans des banques différentes. Il existe deux copies des étiquettes, car chaque ligne de 64 octets est répartie entre les huit banques. Chaque copie d'étiquette gère l'un des deux accès par cycle.
Le K8 dispose également de caches à plusieurs niveaux. Il existe des TLB d'instructions et de données de second niveau, qui stockent uniquement des entrées de table de pages (PTE) mappant 4 KiB. Les caches d'instructions et de données, ainsi que les différents TLB, peuvent être alimentés par le vaste cache L2 unifié . Ce cache est exclusif aux caches d'instructions et de données L1, ce qui signifie que toute ligne de 8 octets ne peut se trouver que dans l'un des caches suivants : le cache d'instructions L1, le cache de données L1 ou le cache L2. Il est toutefois possible qu'une ligne du cache de données contienne une PTE présente également dans l'un des TLB ; le système d'exploitation assure la cohérence des TLB en vidant certaines portions de ces derniers lors de la mise à jour des tables de pages en mémoire.
Le K8 met également en cache des informations qui ne sont jamais stockées en mémoire : les informations de prédiction. Ces caches ne sont pas représentés sur le schéma ci-dessus. Comme c'est souvent le cas pour ce type de processeur, le K8 dispose d'une prédiction de branchement assez complexe , avec des tables permettant de prédire si des branchements seront effectués et d'autres tables prédisant les cibles des branchements et des sauts. Certaines de ces informations sont associées aux instructions, à la fois dans le cache d'instructions de niveau 1 et dans le cache secondaire unifié.
Le K8 utilise une astuce ingénieuse pour stocker les informations de prédiction avec les instructions dans le cache secondaire. Les lignes de ce cache sont protégées contre toute corruption accidentelle de données (par exemple, suite à l'impact d'une particule alpha ) par un système de correction d'erreurs (ECC) ou par parité , selon qu'elles proviennent du cache principal de données ou d'instructions. Le code de parité occupant moins de bits que le code ECC, les lignes du cache d'instructions disposent de quelques bits supplémentaires. Ces bits servent à stocker les informations de prédiction de branchement associées à ces instructions. Il en résulte un historique de branchement plus étendu pour le prédicteur de branchement, et donc une meilleure précision.
Plus de hiérarchies
D'autres processeurs disposent d'autres types de prédicteurs (par exemple, le prédicteur de contournement de stockage à chargement dans le DEC Alpha 21264 ).
Ces prédicteurs sont des caches, car ils stockent des informations dont le calcul est coûteux. Certains termes employés pour parler des prédicteurs sont les mêmes que ceux utilisés pour les caches (on parle par exemple de « succès » dans un prédicteur de branchement), mais les prédicteurs ne sont généralement pas considérés comme faisant partie de la hiérarchie des caches.
Le K8 assure la cohérence matérielle des caches d'instructions et de données, ce qui signifie qu'une instruction de stockage effectuée juste après une autre modifiera l'instruction suivante. D'autres processeurs, comme ceux des familles Alpha et MIPS, s'appuient sur le logiciel pour maintenir la cohérence du cache d'instructions. L'affichage des instructions de stockage dans le flux d'instructions n'est garanti que lorsqu'un programme appelle une fonction du système d'exploitation pour assurer cette cohérence.
Étiquette RAM
Tag RAM sur la carte d'un Intel Pentium III En génie informatique, une mémoire RAM étiquetée permet de spécifier quelle adresse mémoire est actuellement stockée dans le cache du processeur. Pour une conception simple à correspondance directe, une SRAM rapide peut être utilisée. Les caches associatifs de niveau supérieur utilisent généralement une mémoire adressable par contenu .
Mise en œuvre
Chemin de lecture pour un cache associatif à deux voies Le schéma ci-contre vise à clarifier l'utilisation des différents champs de l'adresse. Le bit 31 est le plus significatif, le bit 0 le moins significatif. Ce schéma représente les SRAM, l'indexation et le multiplexage d'un cache de 4 Kio, associatif par ensembles à deux voies, indexé et étiqueté virtuellement, avec des lignes de 64 octets (B), une largeur de lecture de 32 bits et une adresse virtuelle de 32 bits.
Le cache ayant une capacité de 4 KiB et comportant 64 lignes d'octets, il ne contient que 64 lignes. La lecture s'effectue par paires à partir d'une SRAM d'étiquettes de 32 lignes, chacune associée à une paire d'étiquettes de 21 bits. Bien que toute fonction des bits d'adresse virtuelle 31 à 6 puisse être utilisée pour indexer les SRAM d'étiquettes et de données, l'utilisation des bits de poids faible est plus simple.
De même, étant donné que le cache fait 4 KiB et possède un chemin de lecture de 4 B, et qu'il lit de deux manières pour chaque accès, la SRAM de données comporte 512 lignes de 8 octets de large.
Un cache plus moderne pourrait avoir une capacité de 16 Kio, être associatif par ensembles à 4 voies, indexé virtuellement, avec des indications virtuelles et un marquage physique, avec des lignes de 32 octets, une largeur de lecture de 32 bits et des adresses physiques de 36 bits. Le chemin de lecture pour un tel cache est très similaire à celui décrit précédemment. Au lieu d'étiquettes, ce sont des indications virtuelles qui sont lues et comparées à un sous-ensemble de l'adresse virtuelle. Plus tard dans le pipeline, l'adresse virtuelle est traduite en adresse physique par le TLB, et l'étiquette physique correspondante est lue (une seule, car l'indication virtuelle indique le sens de lecture dans le cache). Enfin, l'adresse physique est comparée à l'étiquette physique pour déterminer si une correspondance a été trouvée.
Certaines conceptions SPARC ont amélioré la vitesse de leurs caches L1 de quelques délais de porte en intégrant l'additionneur d'adresses virtuelles dans les décodeurs SRAM.aux registres . Mais depuis les années 1980 l'écart de performance entre le processeur et la mémoire n'a cessé de se creuser. Les microprocesseurs ont progressé beaucoup plus vite que la mémoire, notamment en termes de fréquence de fonctionnement , faisant de cette dernière un goulot d'étranglement. S'il était techniquement possible d'avoir une mémoire principale aussi rapide que le processeur, une solution plus économique a été privilégiée : utiliser une grande quantité de mémoire basse vitesse, tout en intégrant une petite mémoire cache haute vitesse pour compenser l'écart de performance. Cette approche a permis d'obtenir une capacité dix fois supérieure – pour un coût identique – avec une légère diminution des performances globales.
Premières implémentations TLB
Les premières utilisations documentées d'un TLB ont eu lieu sur le GE 645 et l' IBM 360/67 , qui utilisaient tous deux une mémoire associative comme TLB.
Cache de première instruction
La première utilisation documentée d'un cache d'instructions a eu lieu sur le CDC 6600.
Premier cache de données
La première utilisation documentée d'un cache de données a eu lieu sur le système IBM System/360 modèle 85.
Dans les microprocesseurs 68k
Le 68010 , sorti en 1982, dispose d'un « mode boucle » pouvant être considéré comme un cache d'instructions réduit et spécifique, accélérant les boucles composées de seulement deux instructions. Le 68020 , sorti en 1984, a remplacé ce mode par un cache d'instructions classique de 256 octets, devenant ainsi le premier processeur de la série 68k à intégrer une véritable mémoire cache sur puce.
Le 68030 , sorti en 1987, est essentiellement un cœur 68020 avec un cache de données supplémentaire de 256 octets, une unité de gestion de la mémoire sur puce (MMU), une réduction de processus et un mode rafale ajouté pour les caches.
Le 68040 , sorti en 1990, possède des caches d'instructions et de données séparés de quatre kilo-octets chacun.
Le 68060 , sorti en 1994, possède les éléments suivants : cache de données de 8 KiB (associatif à quatre voies), cache d'instructions de 8 KiB (associatif à quatre voies), tampon d'instructions FIFO de 96 octets, cache de branchement de 256 entrées et tampon MMU de cache de traduction d'adresses de 64 entrées (associatif à quatre voies).
Dans les microprocesseurs x86
Exemple de carte mère avec un microprocesseur i386 (33 MHz), 64 KiB de cache (25 ns ; 8 puces dans le coin inférieur gauche), 2 Mio de DRAM (70 ns ; 8 SIMM à droite du cache) et un contrôleur de cache ( Austek A38202 ; à droite du processeur). Avec l'arrivée des microprocesseurs x86 à des fréquences d'horloge de 20 MHz et plus (notamment l' A386) , de petites quantités de mémoire cache rapide ont commencé à être intégrées aux systèmes pour améliorer leurs performances. En effet, la DRAM utilisée comme mémoire principale présentait une latence importante, pouvant atteindre 120 ns, ainsi que des cycles de rafraîchissement. Le cache était constitué de cellules de mémoire SRAM , plus coûteuses mais nettement plus rapides, dont la latence était alors de l'ordre de 10 à 25 ns. Les premiers caches étaient externes au processeur et généralement situés sur la carte mère sous la forme de huit ou neuf composants DIP insérés dans des supports, permettant ainsi d'ajouter le cache en option ou de l'étendre.
Certaines versions du processeur Intel 386 pouvaient prendre en charge de 16 à 256 KiB de cache externe.
Avec le processeur 486 , un cache de 8 Kio était intégré directement à la puce. Ce cache était appelé cache de niveau 1 (L1) pour le différencier du cache de niveau 2 (L2), plus lent et situé sur la carte mère. Ces derniers étaient beaucoup plus volumineux, la taille la plus courante étant de 256 Kio. Certaines cartes mères disposaient d'emplacements pour la carte fille Intel 485Turbocache , dotée de 64 ou 128 Ko de mémoire cache. La popularité du cache sur carte mère s'est maintenue durant l' ère Pentium MMX , mais a été rendue obsolète par l'introduction de la SDRAM et l'écart croissant entre les fréquences d'horloge du bus et du processeur, ce qui a fait que le cache sur carte mère n'était plus que légèrement plus rapide que la mémoire principale.
L'évolution suivante en matière d'implémentation de cache dans les microprocesseurs x86 a commencé avec le Pentium Pro , qui a intégré le cache secondaire dans le même boîtier que le microprocesseur, cadencé à la même fréquence que ce dernier.
Les caches intégrés à la carte mère ont longtemps bénéficié d'une grande popularité grâce aux processeurs AMD K6-2 et AMD K6-III , qui utilisaient encore le socket 7 , précédemment employé par Intel avec des caches intégrés. Le K6-III intégrait 256 Kio de cache L2 et exploitait le cache intégré comme cache de troisième niveau, appelé L3 (des cartes mères avec jusqu'à 2 Mio de cache intégré ont été produites). Après l'obsolescence du socket 7, le cache intégré à la carte mère a disparu des systèmes x86.
Les caches à trois niveaux ont été réutilisés pour la première fois avec l'introduction du processeur Intel Xeon MP « Foster Core » , où le cache L3 a été ajouté à la puce du processeur. Il est devenu courant que la taille totale du cache augmente avec les nouvelles générations de processeurs, et récemment (en 2011), il n'est pas rare de trouver des caches de niveau 3 de plusieurs dizaines de mégaoctets
Intel a introduit un cache de niveau 4 intégré avec la microarchitecture Haswell . Les processeurs Crystalwell Haswell, équipés de la variante GT3e du processeur graphique intégré Intel Iris Pro, disposent de 128 Mio de mémoire DRAM embarquée ( eDRAM ) sur le même boîtier. Ce cache L4 est partagé dynamiquement entre le GPU et le CPU intégrés, et sert de cache victime au cache L3 du CPU.
Dans les microprocesseurs ARM
Le processeur Apple M1 dispose de 128 ou 192 Kio de cache d'instructions L1 par cœur (important pour la latence et les performances monocœur), selon le type de cœur. Il s'agit d'un cache L1 exceptionnellement important pour un processeur (et pas seulement pour un ordinateur portable). La taille totale de la mémoire cache n'est pas particulièrement élevée pour un ordinateur portable (c'est le total qui importe le plus pour le débit), et des tailles totales bien supérieures (par exemple, L3 ou L4) sont disponibles sur les ordinateurs centraux IBM.
Recherches actuelles
Les premières conceptions de cache se concentraient exclusivement sur le coût direct du cache et de la RAM , ainsi que sur la vitesse d'exécution moyenne. Les conceptions de cache plus récentes prennent également en compte l'efficacité énergétique , la tolérance aux pannes et d'autres objectifs.
Plusieurs outils sont à la disposition des architectes informatiques pour les aider à explorer les compromis entre le temps de cycle du cache, l'énergie et la surface ; le simulateur de cache CACTI et le simulateur de jeu d'instructions SimpleScalar sont deux options open-source.
Cache multiport
Un cache multiport est un cache capable de traiter plusieurs requêtes simultanément. Alors qu'un cache traditionnel utilise généralement une seule adresse mémoire, un cache multiport peut permettre de demander N adresses à la fois, N étant le nombre de ports connectés entre le processeur et le cache. L'avantage est qu'un processeur pipeliné peut accéder à la mémoire depuis différentes phases de son pipeline. Autre avantage : il rend possible le concept de processeurs superscalaires grâce à différents niveaux de cache.
Plus d articles de Worldlex Wiki
Revenez a l index pour explorer davantage de pages sur l histoire, la science, la culture, la geographie et la societe en francais.
Explorer l index
mémoire virtuelle . En résumé, soit chaque programme exécuté sur la machine dispose de son propre espace d'adressage simplifié , contenant uniquement le code et les données de ce programme, soit tous les programmes s'exécutent dans un espace d'adressage virtuel commun. Un programme s'exécute en calculant, comparant, lisant et écrivant aux adresses de son espace d'adressage virtuel, plutôt qu'aux adresses de l'espace d'adressage physique, ce qui simplifie les programmes et facilite leur écriture.La mémoire virtuelle nécessite que le processeur traduise les adresses virtuelles générées par le programme en adresses physiques dans la mémoire principale. La partie du processeur qui effectue cette traduction est appelée unité de gestion de la mémoire (MMU). Le chemin rapide à travers la MMU peut effectuer ces traductions stockées dans le tampon de traduction (TLB), qui est un cache de correspondances entre la table des pages , la table des segments, ou les deux, du système d'exploitation .
Dans le cadre de la présente discussion, la traduction d'adresses présente trois caractéristiques importantes :
- Latence : L'adresse physique est disponible auprès de l'unité de gestion de la mémoire (MMU) un certain temps, peut-être quelques cycles, après que l'adresse virtuelle soit disponible auprès du générateur d'adresses.
- Gio peut être divisé en 1 048 576 pages de 4 Kio, chacune pouvant être mappée indépendamment. Plusieurs tailles de page peuvent être prises en charge ; voir la documentation sur la mémoire virtuelle pour plus de détails.
Un des premiers systèmes de mémoire virtuelle, l' IBM M44/44X , nécessitait un accès à une table de correspondance stockée en mémoire centrale avant chaque accès programmé à la mémoire principale. En l'absence de cache, et la mémoire de la table de correspondance fonctionnant à la même vitesse que la mémoire principale, la vitesse d'accès à la mémoire était ainsi réduite de moitié. Deux machines anciennes utilisant une table des pages en mémoire principale pour la correspondance, l' IBM System/360 Modèle 67 et le GE 645 , disposaient toutes deux d'une petite mémoire associative servant de cache pour les accès à la table des pages en mémoire. Ces deux machines sont antérieures à la première machine dotée d'un cache pour la mémoire principale, l' IBM System/360 Modèle 85 ; le premier cache matériel utilisé dans un système informatique n'était donc pas un cache de données ou d'instructions, mais un TLB (Time-Level Block).
Les caches peuvent être divisés en quatre types, selon que l'index ou l'étiquette corresponde à des adresses physiques ou virtuelles :
- Les caches à indexation physique et étiquetage physique (PIPT) utilisent l'adresse physique à la fois pour l'index et l'étiquette. Bien que cette méthode soit simple et évite les problèmes d'aliasing, elle est également lente, car l'adresse physique doit être recherchée (ce qui peut entraîner un défaut de bloc de liste et un accès à la mémoire principale) avant que cette adresse puisse être recherchée dans le cache.
- Les caches VIVT ( Virtually Indexed, Virtually Tagged ) utilisent l'adresse virtuelle à la fois comme index et comme étiquette. Ce schéma de cache permet des recherches beaucoup plus rapides, car il n'est pas nécessaire de consulter l'unité de gestion de la mémoire (MMU) au préalable pour déterminer l'adresse physique correspondant à une adresse virtuelle donnée. Cependant, les caches VIVT souffrent de problèmes d'aliasing : plusieurs adresses virtuelles différentes peuvent désigner la même adresse physique. Ces adresses sont alors mises en cache séparément, bien qu'elles pointent vers la même zone mémoire, ce qui engendre des problèmes de cohérence. Bien que des solutions existent elles ne sont pas compatibles avec les protocoles de cohérence standard. Un autre problème est celui des homonymes : une même adresse virtuelle peut correspondre à plusieurs adresses physiques différentes. Il est impossible de distinguer ces correspondances en se basant uniquement sur l'index virtuel. Parmi les solutions potentielles, on peut citer : le vidage du cache après un changement de contexte , l'obligation d'utiliser des espaces d'adressage non chevauchants et l'attribution d'un identifiant d'espace d'adressage (ASID) à l'adresse virtuelle. De plus, le problème de la modification des correspondances entre adresses virtuelles et physiques nécessite la vidange du cache, car les adresses virtuelles ne sont plus valides. Ces problèmes disparaissent lorsque les étiquettes utilisent des adresses physiques (VIPT).
- Les caches à indexation virtuelle et étiquetage physique (VIPT) utilisent l'adresse virtuelle pour l'index et l'adresse physique dans l'étiquette. L'avantage par rapport aux caches PIPT réside dans une latence réduite, car la recherche dans le cache peut être effectuée en parallèle avec la traduction TLB. Cependant, l'étiquette ne peut être comparée que lorsque l'adresse physique est disponible. L'avantage par rapport aux caches VIVT est que, grâce à l'étiquette contenant l'adresse physique, le cache peut détecter les homonymes. Théoriquement, les caches VIPT nécessitent davantage de bits d'étiquette, car certains bits d'index peuvent différer entre les adresses virtuelle et physique (par exemple, les bits 12 et suivants pour les pages de 4 Kio) et devraient être inclus à la fois dans l'index virtuel et dans l'étiquette physique. En pratique, cela ne pose pas de problème car, afin d'éviter les problèmes de cohérence, les caches VIPT sont conçus sans ces bits d'index (par exemple, en limitant le nombre total de bits pour l'index et le décalage de bloc à 12 pour les pages de 4 Kio) ; la taille des caches VIPT est ainsi limitée à la taille de la page multipliée par l'associativité du cache.
- Les caches à indexation physique et étiquetage virtuel (PIVT) sont souvent considérés dans la littérature comme inutiles et inexistants . Pourtant, le MIPS R6000 utilise ce type de cache comme seule implémentation connue . Le R6000 est implémenté en logique à couplage d'émetteur , une technologie extrêmement rapide, mais inadaptée aux grandes mémoires telles qu'un TLB . Le R6000 résout ce problème en plaçant la mémoire TLB dans une partie réservée du cache de second niveau, dotée d'une minuscule « tranche » TLB haute vitesse intégrée. Le cache est indexé par l'adresse physique obtenue à partir de cette tranche TLB. Cependant, comme la tranche TLB ne traduit que les bits d'adresse virtuelle nécessaires à l'indexation du cache et n'utilise aucun étiquetage, des accès non autorisés au cache peuvent se produire. Ce problème est résolu par l'étiquetage avec l'adresse virtuelle.
La vitesse de cette récurrence (la latence de chargement ) est cruciale pour les performances du processeur, et c'est pourquoi la plupart des caches de niveau 1 modernes sont virtuellement indexés, ce qui permet au moins à la recherche TLB de l'unité de gestion de la mémoire (MMU) de se dérouler en parallèle avec la récupération des données de la mémoire RAM du cache.
Cependant, l'indexation virtuelle n'est pas optimale pour tous les niveaux de cache. Le coût de la gestion des alias virtuels augmente avec la taille du cache ; c'est pourquoi la plupart des caches de niveau 2 et plus sont indexés physiquement.
Historiquement, les caches utilisaient à la fois des adresses virtuelles et physiques pour leurs étiquettes, bien que l'étiquetage virtuel soit aujourd'hui rare. Si la recherche dans le TLB peut se terminer avant celle dans la RAM du cache, l'adresse physique est disponible à temps pour la comparaison des étiquettes, et l'étiquetage virtuel devient inutile. Les grands caches sont donc généralement étiquetés physiquement, tandis que seuls les petits caches à très faible latence utilisent l'étiquetage virtuel. Dans les processeurs généralistes récents, l'étiquetage virtuel a été remplacé par des indications virtuelles, comme décrit ci-dessous.
Problèmes d'homonymie et de synonymie
Un cache reposant sur l'indexation et l'étiquetage virtuels devient incohérent lorsqu'une même adresse virtuelle est associée à différentes adresses physiques ( homonymie ). Ce problème peut être résolu en utilisant l'adresse physique pour l'étiquetage, ou en stockant l'identifiant de l'espace d'adressage dans la ligne de cache. Cependant, cette dernière approche ne résout pas le problème des synonymes , où plusieurs lignes de cache finissent par stocker des données pour la même adresse physique. L'écriture à ces emplacements peut ne mettre à jour qu'un seul emplacement dans le cache, laissant les autres avec des données incohérentes. Ce problème peut être résolu en utilisant des dispositions mémoire non chevauchantes pour différents espaces d'adressage, ou bien en vidant le cache (ou une partie de celui-ci) lors de tout changement d'association.
Étiquettes et indices virtuels
Le principal avantage des étiquettes virtuelles est que, pour les caches associatifs, elles permettent d'effectuer la correspondance des étiquettes avant la traduction virtuelle-physique. Cependant, les sondages de cohérence et les évictions fournissent une adresse physique pour l'action. Le matériel doit disposer d'un moyen de convertir les adresses physiques en un index de cache, généralement en stockant à la fois les étiquettes physiques et virtuelles. Par comparaison, un cache à étiquettes physiques n'a pas besoin de conserver d'étiquettes virtuelles, ce qui est plus simple. Lorsqu'une correspondance virtuelle-physique est supprimée du TLB, les entrées de cache associées à ces adresses virtuelles doivent être vidées. De même, si des entrées de cache sont autorisées sur des pages non mappées par le TLB, ces entrées doivent être vidées lorsque les droits d'accès à ces pages sont modifiés dans la table des pages.
Le système d'exploitation peut également garantir qu'aucun alias virtuel ne réside simultanément dans le cache. Il assure cette garantie en appliquant la coloration des pages, décrite ci-dessous. Certains processeurs RISC anciens (SPARC, RS/6000) utilisaient cette approche. Elle n'est plus employée aujourd'hui, car le coût matériel de la détection et de la suppression des alias virtuels a diminué, tandis que la complexité logicielle et la perte de performance liées à une coloration parfaite des pages ont augmenté.
Il peut être utile de distinguer les deux fonctions des étiquettes dans un cache associatif : elles servent à déterminer le sens de sélection de l’ensemble d’entrées, et elles servent à déterminer si la recherche a réussi ou échoué. La seconde fonction doit toujours être correcte, mais la première peut occasionnellement faire des suppositions et donner une réponse erronée.
Certains processeurs (par exemple, les premiers SPARC) possèdent des caches à la fois virtuels et physiques. Les étiquettes virtuelles servent à la sélection du chemin d'accès, tandis que les étiquettes physiques déterminent si l'accès a réussi ou échoué. Ce type de cache bénéficie de la faible latence d'un cache à étiquettes virtuelles et de la simplicité d'interface logicielle d'un cache à étiquettes physiques. Il présente toutefois l'inconvénient supplémentaire des étiquettes dupliquées. De plus, lors du traitement d'un échec d'accès, les chemins d'accès alternatifs de la ligne de cache indexée doivent être analysés afin de détecter les alias virtuels et d'éliminer toute correspondance.
L'espace supplémentaire (et la latence accrue) peut être atténué en conservant des indications virtuelles pour chaque entrée de cache, au lieu d'étiquettes virtuelles. Ces indications sont un sous-ensemble ou un hachage de l'étiquette virtuelle et servent à sélectionner la zone de cache à partir de laquelle récupérer les données et une étiquette physique. Comme pour un cache à étiquettes virtuelles, il peut y avoir une correspondance entre une indication virtuelle et une différence d'étiquette physique. Dans ce cas, l'entrée de cache avec l'indication correspondante doit être supprimée afin que les accès au cache après son remplissage à cette adresse ne comportent qu'une seule correspondance d'indication. Étant donné que les indications virtuelles possèdent moins de bits de distinction que les étiquettes virtuelles, un cache utilisant des indications virtuelles subit davantage de défauts de cache liés à des conflits qu'un cache à étiquettes virtuelles.
La réduction ultime des indications virtuelles se trouve peut-être dans le Pentium 4 (cœurs Willamette et Northwood). Sur ces processeurs, l'indication virtuelle est réduite à deux bits et le cache est associatif par ensembles à quatre voies. Concrètement, le matériel maintient une simple permutation entre l'adresse virtuelle et l'index du cache, ce qui rend inutile l'utilisation de la mémoire associative (CAM) pour sélectionner la bonne adresse parmi les quatre voies d'accès.
Coloriage
l'optimisation des boucles imbriquées ), notamment dans le domaine du calcul haute performance (HPC) .Le problème, c'est que si toutes les pages utilisées à un instant donné peuvent avoir des couleurs virtuelles différentes, certaines peuvent avoir la même couleur physique. En fait, si le système d'exploitation attribue des pages physiques aux pages virtuelles de manière aléatoire et uniforme, il est fort probable que certaines pages aient la même couleur physique, et que les adresses de ces pages entrent alors en conflit dans le cache (c'est le paradoxe des anniversaires ).
La solution consiste à ce que le système d'exploitation tente d'attribuer des couleurs physiques différentes à des couleurs virtuelles différentes, une technique appelée coloration des pages . Bien que la correspondance exacte entre les couleurs virtuelles et physiques soit sans incidence sur les performances du système, les correspondances complexes sont difficiles à gérer et présentent peu d'avantages. C'est pourquoi la plupart des méthodes de coloration des pages visent simplement à conserver les mêmes couleurs physiques et virtuelles.
Si le système d'exploitation garantit que chaque page physique correspond à une seule couleur virtuelle, il n'y a pas d'alias virtuels et le processeur peut utiliser des caches indexés virtuellement sans avoir besoin de sondes d'alias virtuels supplémentaires lors de la gestion des défauts. Le système d'exploitation peut également vider le cache d'une page à chaque changement de couleur virtuelle. Comme indiqué précédemment, cette approche a été utilisée dans certaines architectures SPARC et RS/6000 de première génération.
La technique de coloration logicielle des pages a été utilisée pour partitionner efficacement le cache de dernier niveau (LLC) partagé dans les processeurs multicœurs. Cette gestion du LLC basée sur le système d'exploitation dans les processeurs multicœurs a été adoptée par Intel.
Hiérarchie de mémoire d'un serveur AMD Bulldozer Les processeurs modernes possèdent plusieurs caches sur puce interagissant entre eux. Le fonctionnement d'un cache particulier peut être entièrement spécifié par sa taille, la taille des blocs de cache, le nombre de blocs dans un ensemble, la politique de remplacement des ensembles de cache et la politique d'écriture du cache (écriture immédiate ou écriture différée).
Bien que tous les blocs d'un cache donné aient la même taille et la même associativité, les caches de « niveau supérieur » (appelés caches de niveau 1) possèdent généralement un nombre de blocs plus faible, une taille de bloc plus petite et un ensemble de blocs plus restreint, mais offrent des temps d'accès très courts. Les caches de « niveau inférieur » (c'est-à-dire de niveau 2 et inférieurs) possèdent un nombre de blocs progressivement plus important, une taille de bloc plus grande, un ensemble de blocs plus dense et des temps d'accès relativement plus longs, mais restent beaucoup plus rapides que la mémoire principale.
La politique de remplacement des entrées du cache est déterminée par un algorithme de cache choisi par les concepteurs du processeur. Dans certains cas, plusieurs algorithmes sont proposés pour différents types de charges de travail.
Caches spécialisées
Les processeurs pipelinés accèdent à la mémoire à partir de plusieurs points du pipeline : extraction des instructions, traduction d'adresses virtuelles en adresses physiques et extraction des données (voir le pipeline RISC classique ). Naturellement, on utilise des caches physiques différents pour chacun de ces points, afin qu'une même ressource physique ne soit pas affectée à deux points du pipeline. Le pipeline comporte ainsi naturellement au moins trois caches distincts (instructions, TLB et données), chacun spécialisé dans son rôle spécifique.
Cache de victimes
Norman Jouppi de DEC en 1990. La variante Crystalwell des processeurs Haswell d'Intel intégrait un cache eDRAM de niveau 4 de 128 Mio , servant de cache victime au cache de niveau 3 du processeur. Dans la microarchitecture Skylake, le cache de niveau 4 ne fonctionne plus comme cache victime.
Intel Pentium 4. Un cache de traces est un mécanisme permettant d'augmenter la bande passante de récupération des instructions et de diminuer la consommation d'énergie (dans le cas du Pentium 4) en stockant les traces des instructions qui ont déjà été récupérées et décodées. Un cache de traces stocke les instructions soit après leur décodage, soit au fur et à mesure de leur suppression. Généralement, les instructions sont ajoutées aux caches de traces par groupes représentant soit des blocs de base individuels , soit des traces d'instructions dynamiques. Le cache de traces du Pentium 4 stocke les micro-opérations résultant du décodage des instructions x86, offrant ainsi la fonctionnalité d'un cache de micro-opérations. Grâce à cela, la prochaine fois qu'une instruction sera nécessaire, il ne sera pas nécessaire de la décoder à nouveau en micro-opérations.
Cache de fusion d'écriture (WCC)
Le cache de coalescence d'écriture (WCC ) est un cache spécial faisant partie du cache L2 de la microarchitecture Bulldozer d' AMD . Les données écrites provenant des deux caches L1D du module transitent par le WCC, où elles sont mises en mémoire tampon et fusionnées. Le WCC a pour fonction de réduire le nombre d'écritures dans le cache L2.
les micro-opérations des instructions décodées, telles que reçues directement des décodeurs d'instructions ou du cache d'instructions. Lorsqu'une instruction doit être décodée, le cache μop vérifie si sa forme décodée s'y trouve ; si elle n'est pas disponible, l'instruction est décodée puis mise en cache.L'un des premiers travaux décrivant le cache μop comme une interface alternative pour la famille de processeurs Intel P6 est l'article de 2001 intitulé « Micro-Operation Cache: A Power Aware Frontend for Variable Instruction Length ISA » . Par la suite, Intel a intégré des caches μop dans ses processeurs Sandy Bridge et dans les microarchitectures successives telles qu'Ivy Bridge et Haswell : a implémenté un cache μop dans sa microarchitecture Zen .
L'accès à des instructions complètes pré-décodées élimine la nécessité de décoder à répétition des instructions complexes de longueur variable en micro-opérations plus simples de longueur fixe, et simplifie le processus de prédiction, d'accès, de rotation et d'alignement des instructions récupérées. Un cache de micro-opérations décharge efficacement le matériel d'accès et de décodage, réduisant ainsi la consommation d'énergie et améliorant la fourniture de micro-opérations décodées au processeur. Le cache de micro-opérations améliore également les performances en fournissant de manière plus constante les micro-opérations décodées au processeur et en éliminant divers goulots d'étranglement dans la logique d'accès et de décodage du processeur.
Un cache μop présente de nombreuses similitudes avec un cache de traces, mais il est beaucoup plus simple, ce qui lui confère une meilleure efficacité énergétique ; il est donc mieux adapté aux implémentations sur des appareils alimentés par batterie. Le principal inconvénient du cache de traces, à l’origine de son inefficacité énergétique, réside dans la complexité matérielle requise pour son heuristique de décision concernant la mise en cache et la réutilisation des traces d’instructions créées dynamiquement.
cache d'instructions de la cible de branchement
Un cache de cible de branchement , ou cache d'instructions de cible de branchement (nom utilisé sur les microprocesseurs ARM ) est un cache spécialisé qui stocke les premières instructions à l'adresse de destination d'un branchement. Il est utilisé par les processeurs basse consommation qui n'ont pas besoin d'un cache d'instructions classique, car leur système mémoire est capable de fournir les instructions suffisamment rapidement pour satisfaire le processeur. Cependant, cela ne s'applique qu'aux instructions consécutives ; le redémarrage de la récupération d'une instruction à une nouvelle adresse nécessite toujours plusieurs cycles de latence, ce qui provoque une brève oscillation du pipeline après un transfert de contrôle. Un cache de cible de branchement fournit les instructions pour ces quelques cycles, évitant ainsi un délai après la plupart des branchements.
Cela permet un fonctionnement à pleine vitesse avec un cache beaucoup plus petit qu'un cache d'instructions traditionnel à temps plein.
Cache intelligent
Le cache intelligent est une méthode de mise en cache de niveau 2 ou 3 pour plusieurs cœurs d'exécution, développée par Intel .
Le cache intelligent partage la mémoire cache entre les cœurs d'un processeur multicœur . Comparé à un cache dédié par cœur, le taux global d'échecs de cache diminue lorsque les cœurs n'ont pas besoin de parts égales de l'espace cache. Par conséquent, un seul cœur peut utiliser la totalité du cache de niveau 2 ou 3 tandis que les autres cœurs sont inactifs. De plus, le cache partagé accélère le partage de mémoire entre les différents cœurs d'exécution.
eDRAM et montés sur un module multi-puces , constituant ainsi un quatrième niveau de cache. Dans de rares cas, comme pour le processeur du mainframe IBM z15 (2019), tous les niveaux jusqu'au cache L1 sont implémentés en eDRAM, remplaçant entièrement la SRAM (pour le cache, la SRAM étant toujours utilisée pour les registres ). La gamme de processeurs Apple Silicon , basée sur l'architecture ARM et comprenant les A14 et M1 , dispose d'un cache L1i de 192 Kio pour chacun des cœurs hautes performances, une capacité exceptionnellement élevée ; en revanche, les cœurs basse consommation ne disposent que de 128 Kio. Depuis, d'autres processeurs tels que Lunar Lake d' Intel et Oryon de Qualcomm ont également implémenté des tailles de cache L1i similaires.Les avantages des caches L3 et L4 dépendent des modèles d'accès de l'application. Voici quelques exemples de produits intégrant des caches L3 et L4 :
- Alpha 21164 (1995) disposait d'un cache L3 hors puce de 1 à 64 Mio.
- L'AMD K6-III (1999) disposait d'un cache L3 basé sur la carte mère.
- IBM POWER4 (2001) disposait de caches L3 hors puce de 32 Mio par processeur, partagés entre plusieurs processeurs.
- L'Itanium 2 (2003) disposait d'un cache Itanium 2 (2003) MX 2 incorporait deux processeurs Itanium 2 ainsi qu'un cache L4 partagé de 64 Mio sur un module multi-puces compatible broche à broche avec un processeur Madison.
- Le produit Intel Xeon MP, nom de code « Tulsa » (2006), dispose de 16 Mio de cache L3 intégré partagé entre deux cœurs de processeur.
- AMD Phenom (2007) avec 2 Mio de cache L3.
- L'AMD Phenom II (2008) dispose d'un cache L3 unifié sur puce allant jusqu'à 6 Mio.
- Intel Core i7 (2008) possède un cache L3 unifié sur puce de 8 Mio, inclusif et partagé par tous les cœurs.
- Les processeurs Intel Haswell avec carte graphique intégrée Intel Iris Pro disposent de 128 Mio d'eDRAM faisant essentiellement office de cache L4.
Enfin, à l'autre extrémité de la hiérarchie mémoire, le fichier de registres du processeur peut être considéré comme le cache le plus petit et le plus rapide du système. Sa particularité réside dans le fait qu'il est géré par logiciel, généralement par le compilateur, qui alloue des registres pour stocker les valeurs extraites de la mémoire principale, par exemple pour l'optimisation des boucles imbriquées . Cependant, grâce au renommage des registres , la plupart des affectations de registres du compilateur sont réallouées dynamiquement par le matériel à l'exécution dans un banc de registres, permettant ainsi au processeur de rompre les dépendances de données erronées et d'atténuer les risques liés au pipeline.
Les fichiers de registres présentent parfois une hiérarchie : le Cray-1 (vers 1976) disposait de huit registres d’adresse « A » et de huit registres de données scalaires « S » généralement utilisables. Il comportait également 64 registres d’adresse « B » et 64 registres de données scalaires « T », dont l’accès était plus lent, mais plus rapide que la mémoire principale. Les registres « B » et « T » étaient nécessaires car le Cray-1 ne possédait pas de cache de données. (Le Cray-1 disposait toutefois d’un cache d’instructions.)
multicœur , la question se pose de savoir si les caches doivent être partagés ou locaux à chaque cœur. La mise en œuvre d'un cache partagé engendre inévitablement un câblage plus complexe. En revanche, disposer d'un cache par puce , plutôt que par cœur , réduit considérablement l'espace nécessaire et permet ainsi d'intégrer un cache de plus grande capacité.En règle générale, le partage du cache L1 est déconseillé car l'augmentation de latence qui en résulte ralentirait considérablement chaque cœur par rapport à une puce monocœur. Cependant, pour le cache de plus haut niveau (généralement L3, le dernier appelé avant l'accès à la mémoire), un cache global est souhaitable pour plusieurs raisons : il permet à un seul cœur d'utiliser l'intégralité du cache, réduit la redondance des données en autorisant différents processus ou threads à partager les données mises en cache, et simplifie les protocoles de cohérence de cache utilisés. Par exemple, une puce à huit cœurs avec trois niveaux de cache peut inclure un cache L1 par cœur, un cache L2 intermédiaire pour chaque paire de cœurs et un cache L3 partagé par tous les cœurs.
Un cache de niveau le plus élevé partagé (généralement L3, appelé avant l'accès à la mémoire) est généralement désigné sous le nom de cache de dernier niveau (LLC). Des techniques supplémentaires sont utilisées pour augmenter le niveau de parallélisme lorsque le LLC est partagé entre plusieurs cœurs, notamment en le divisant en plusieurs morceaux qui adressent des plages d'adresses mémoire spécifiques et peuvent être utilisés indépendamment.
Séparés versus unifiés
Dans une structure de cache séparée, les instructions et les données sont mises en cache séparément ; une ligne de cache sert donc soit aux instructions, soit aux données, mais pas aux deux. L’utilisation de tampons de traduction d’instructions et de données distincts présente divers avantages . Dans une structure unifiée, cette contrainte disparaît et les lignes de cache peuvent servir à la fois aux instructions et aux données.
AMD Athlon ) utilisent des caches exclusifs : les données sont garanties de se trouver dans au plus l'un des caches L1 ou L2, jamais dans les deux. D'autres processeurs encore (comme les Intel Pentium II , III et 4 ) n'exigent pas que les données du cache L1 résident également dans le cache L2, bien que cela soit souvent le cas. Il n'existe pas de nom universellement accepté pour cette politique intermédiaire ; deux appellations courantes sont « non exclusif » et « partiellement inclusif ».L’avantage des caches exclusifs réside dans leur capacité de stockage supérieure. Cet avantage est plus marqué lorsque le cache L1 exclusif est comparable au cache L2, et diminue si le cache L2 est beaucoup plus grand que le cache L1. En cas d’échec d’accès dans le cache L1 et de succès dans le cache L2, la ligne correspondante dans le cache L2 est échangée avec une ligne du cache L1. Cet échange est beaucoup plus complexe que la simple copie d’une ligne du cache L2 vers le cache L1, opération effectuée par un cache inclusif.
L'un des avantages des caches strictement inclusifs est que, lorsqu'un périphérique externe ou un autre processeur d'un système multiprocesseur souhaite supprimer une ligne de cache du processeur, il suffit que ce dernier consulte le cache L2. Dans les hiérarchies de caches n'imposant pas l'inclusion, le cache L1 doit également être consulté. En revanche, il existe une corrélation entre les associativités des caches L1 et L2 : si le cache L2 ne possède pas au moins autant de voies que l'ensemble des caches L1, l'associativité effective de ces derniers est limitée. Un autre inconvénient des caches inclusifs est que, lors de toute éviction dans le cache L2, les lignes (potentiellement) correspondantes dans le cache L1 doivent également être évincées afin de maintenir l'inclusivité. Cette opération est conséquente et entraîne un taux d'échecs de cache L1 plus élevé.
Un autre avantage des caches inclusifs est que le cache principal peut utiliser des lignes de cache plus larges, ce qui réduit la taille des étiquettes du cache secondaire. (Les caches exclusifs exigent que les deux caches aient des lignes de cache de même taille, afin que les lignes puissent être permutées en cas d'échec de cache L1 et de succès de cache L2.) Si le cache secondaire est dix fois plus grand que le cache principal, et que les données du cache sont dix fois plus grandes que les étiquettes de cache, la surface d'étiquettes ainsi économisée peut être comparable à la surface incrémentale nécessaire pour stocker les données du cache L1 dans le cache L2.
Mémoire du bloc-notes
La mémoire scratchpad (SPM), également connue sous le nom de mémoire scratchpad, mémoire RAM scratchpad ou mémoire locale dans la terminologie informatique, est une mémoire interne à haute vitesse utilisée pour le stockage temporaire de calculs, de données et d'autres travaux en cours.Exemple : le K8
Pour illustrer à la fois la spécialisation et la mise en cache multiniveau, voici la hiérarchie de cache du cœur K8 du processeur AMD Athlon 64.
Hiérarchie du cache du cœur K8 du processeur AMD Athlon 64 Le K8 possède quatre caches spécialisés : un cache d’instructions, un TLB d’instructions , un TLB de données et un cache de données. Chacun de ces caches est spécialisé :
- Le cache d'instructions conserve des copies de lignes de mémoire de 64 octets et en extrait 16 à chaque cycle. Chaque octet de ce cache est stocké sur dix bits au lieu de huit, les bits supplémentaires marquant les limites des instructions (il s'agit d'un exemple de prédécodage). Le cache utilise uniquement la parité plutôt que la correction d'erreurs (ECC ), car la parité est plus petite et toute donnée corrompue peut être remplacée par des données fraîches extraites de la mémoire (qui contient toujours une copie à jour des instructions).
- Le TLB d'instructions conserve des copies des entrées de table des pages (PTE). À chaque cycle, l'adresse virtuelle de chaque instruction est traduite par ce TLB en une adresse physique. Chaque entrée occupe quatre ou huit octets en mémoire. Le K8 ayant une taille de page variable, chaque TLB est divisé en deux sections : l'une pour les PTE correspondant à des pages de 4 Kio, l'autre pour celles correspondant à des pages de 4 Mio ou 2 Mio. Cette division simplifie le circuit d'association dans chaque section. Le système d'exploitation associe des PTE de tailles différentes aux différentes sections de l'espace d'adressage virtuel.
- Le TLB de données possède deux copies contenant des entrées identiques. Ces deux copies permettent deux accès aux données par cycle pour traduire les adresses virtuelles en adresses physiques. À l'instar du TLB d'instructions, ce TLB est divisé en deux types d'entrées.
- Le cache de données conserve des copies de lignes de mémoire de 64 octets. Il est divisé en 8 banques (chacune stockant 8 Kio de données) et peut accéder à deux ensembles de données de 8 octets par cycle, à condition qu'ils se trouvent dans des banques différentes. Il existe deux copies des étiquettes, car chaque ligne de 64 octets est répartie entre les huit banques. Chaque copie d'étiquette gère l'un des deux accès par cycle.
Le K8 dispose également de caches à plusieurs niveaux. Il existe des TLB d'instructions et de données de second niveau, qui stockent uniquement des entrées de table de pages (PTE) mappant 4 KiB. Les caches d'instructions et de données, ainsi que les différents TLB, peuvent être alimentés par le vaste cache L2 unifié . Ce cache est exclusif aux caches d'instructions et de données L1, ce qui signifie que toute ligne de 8 octets ne peut se trouver que dans l'un des caches suivants : le cache d'instructions L1, le cache de données L1 ou le cache L2. Il est toutefois possible qu'une ligne du cache de données contienne une PTE présente également dans l'un des TLB ; le système d'exploitation assure la cohérence des TLB en vidant certaines portions de ces derniers lors de la mise à jour des tables de pages en mémoire.
Le K8 met également en cache des informations qui ne sont jamais stockées en mémoire : les informations de prédiction. Ces caches ne sont pas représentés sur le schéma ci-dessus. Comme c'est souvent le cas pour ce type de processeur, le K8 dispose d'une prédiction de branchement assez complexe , avec des tables permettant de prédire si des branchements seront effectués et d'autres tables prédisant les cibles des branchements et des sauts. Certaines de ces informations sont associées aux instructions, à la fois dans le cache d'instructions de niveau 1 et dans le cache secondaire unifié.
Le K8 utilise une astuce ingénieuse pour stocker les informations de prédiction avec les instructions dans le cache secondaire. Les lignes de ce cache sont protégées contre toute corruption accidentelle de données (par exemple, suite à l'impact d'une particule alpha ) par un système de correction d'erreurs (ECC) ou par parité , selon qu'elles proviennent du cache principal de données ou d'instructions. Le code de parité occupant moins de bits que le code ECC, les lignes du cache d'instructions disposent de quelques bits supplémentaires. Ces bits servent à stocker les informations de prédiction de branchement associées à ces instructions. Il en résulte un historique de branchement plus étendu pour le prédicteur de branchement, et donc une meilleure précision.
Plus de hiérarchies
D'autres processeurs disposent d'autres types de prédicteurs (par exemple, le prédicteur de contournement de stockage à chargement dans le DEC Alpha 21264 ).
Ces prédicteurs sont des caches, car ils stockent des informations dont le calcul est coûteux. Certains termes employés pour parler des prédicteurs sont les mêmes que ceux utilisés pour les caches (on parle par exemple de « succès » dans un prédicteur de branchement), mais les prédicteurs ne sont généralement pas considérés comme faisant partie de la hiérarchie des caches.
Le K8 assure la cohérence matérielle des caches d'instructions et de données, ce qui signifie qu'une instruction de stockage effectuée juste après une autre modifiera l'instruction suivante. D'autres processeurs, comme ceux des familles Alpha et MIPS, s'appuient sur le logiciel pour maintenir la cohérence du cache d'instructions. L'affichage des instructions de stockage dans le flux d'instructions n'est garanti que lorsqu'un programme appelle une fonction du système d'exploitation pour assurer cette cohérence.
Étiquette RAM
Tag RAM sur la carte d'un Intel Pentium III En génie informatique, une mémoire RAM étiquetée permet de spécifier quelle adresse mémoire est actuellement stockée dans le cache du processeur. Pour une conception simple à correspondance directe, une SRAM rapide peut être utilisée. Les caches associatifs de niveau supérieur utilisent généralement une mémoire adressable par contenu .
Mise en œuvre
Chemin de lecture pour un cache associatif à deux voies Le schéma ci-contre vise à clarifier l'utilisation des différents champs de l'adresse. Le bit 31 est le plus significatif, le bit 0 le moins significatif. Ce schéma représente les SRAM, l'indexation et le multiplexage d'un cache de 4 Kio, associatif par ensembles à deux voies, indexé et étiqueté virtuellement, avec des lignes de 64 octets (B), une largeur de lecture de 32 bits et une adresse virtuelle de 32 bits.
Le cache ayant une capacité de 4 KiB et comportant 64 lignes d'octets, il ne contient que 64 lignes. La lecture s'effectue par paires à partir d'une SRAM d'étiquettes de 32 lignes, chacune associée à une paire d'étiquettes de 21 bits. Bien que toute fonction des bits d'adresse virtuelle 31 à 6 puisse être utilisée pour indexer les SRAM d'étiquettes et de données, l'utilisation des bits de poids faible est plus simple.
De même, étant donné que le cache fait 4 KiB et possède un chemin de lecture de 4 B, et qu'il lit de deux manières pour chaque accès, la SRAM de données comporte 512 lignes de 8 octets de large.
Un cache plus moderne pourrait avoir une capacité de 16 Kio, être associatif par ensembles à 4 voies, indexé virtuellement, avec des indications virtuelles et un marquage physique, avec des lignes de 32 octets, une largeur de lecture de 32 bits et des adresses physiques de 36 bits. Le chemin de lecture pour un tel cache est très similaire à celui décrit précédemment. Au lieu d'étiquettes, ce sont des indications virtuelles qui sont lues et comparées à un sous-ensemble de l'adresse virtuelle. Plus tard dans le pipeline, l'adresse virtuelle est traduite en adresse physique par le TLB, et l'étiquette physique correspondante est lue (une seule, car l'indication virtuelle indique le sens de lecture dans le cache). Enfin, l'adresse physique est comparée à l'étiquette physique pour déterminer si une correspondance a été trouvée.
Certaines conceptions SPARC ont amélioré la vitesse de leurs caches L1 de quelques délais de porte en intégrant l'additionneur d'adresses virtuelles dans les décodeurs SRAM.aux registres . Mais depuis les années 1980 l'écart de performance entre le processeur et la mémoire n'a cessé de se creuser. Les microprocesseurs ont progressé beaucoup plus vite que la mémoire, notamment en termes de fréquence de fonctionnement , faisant de cette dernière un goulot d'étranglement. S'il était techniquement possible d'avoir une mémoire principale aussi rapide que le processeur, une solution plus économique a été privilégiée : utiliser une grande quantité de mémoire basse vitesse, tout en intégrant une petite mémoire cache haute vitesse pour compenser l'écart de performance. Cette approche a permis d'obtenir une capacité dix fois supérieure – pour un coût identique – avec une légère diminution des performances globales.
Premières implémentations TLB
Les premières utilisations documentées d'un TLB ont eu lieu sur le GE 645 et l' IBM 360/67 , qui utilisaient tous deux une mémoire associative comme TLB.
Cache de première instruction
La première utilisation documentée d'un cache d'instructions a eu lieu sur le CDC 6600.
Premier cache de données
La première utilisation documentée d'un cache de données a eu lieu sur le système IBM System/360 modèle 85.
Dans les microprocesseurs 68k
Le 68010 , sorti en 1982, dispose d'un « mode boucle » pouvant être considéré comme un cache d'instructions réduit et spécifique, accélérant les boucles composées de seulement deux instructions. Le 68020 , sorti en 1984, a remplacé ce mode par un cache d'instructions classique de 256 octets, devenant ainsi le premier processeur de la série 68k à intégrer une véritable mémoire cache sur puce.
Le 68030 , sorti en 1987, est essentiellement un cœur 68020 avec un cache de données supplémentaire de 256 octets, une unité de gestion de la mémoire sur puce (MMU), une réduction de processus et un mode rafale ajouté pour les caches.
Le 68040 , sorti en 1990, possède des caches d'instructions et de données séparés de quatre kilo-octets chacun.
Le 68060 , sorti en 1994, possède les éléments suivants : cache de données de 8 KiB (associatif à quatre voies), cache d'instructions de 8 KiB (associatif à quatre voies), tampon d'instructions FIFO de 96 octets, cache de branchement de 256 entrées et tampon MMU de cache de traduction d'adresses de 64 entrées (associatif à quatre voies).
Dans les microprocesseurs x86
Exemple de carte mère avec un microprocesseur i386 (33 MHz), 64 KiB de cache (25 ns ; 8 puces dans le coin inférieur gauche), 2 Mio de DRAM (70 ns ; 8 SIMM à droite du cache) et un contrôleur de cache ( Austek A38202 ; à droite du processeur). Avec l'arrivée des microprocesseurs x86 à des fréquences d'horloge de 20 MHz et plus (notamment l' A386) , de petites quantités de mémoire cache rapide ont commencé à être intégrées aux systèmes pour améliorer leurs performances. En effet, la DRAM utilisée comme mémoire principale présentait une latence importante, pouvant atteindre 120 ns, ainsi que des cycles de rafraîchissement. Le cache était constitué de cellules de mémoire SRAM , plus coûteuses mais nettement plus rapides, dont la latence était alors de l'ordre de 10 à 25 ns. Les premiers caches étaient externes au processeur et généralement situés sur la carte mère sous la forme de huit ou neuf composants DIP insérés dans des supports, permettant ainsi d'ajouter le cache en option ou de l'étendre.
Certaines versions du processeur Intel 386 pouvaient prendre en charge de 16 à 256 KiB de cache externe.
Avec le processeur 486 , un cache de 8 Kio était intégré directement à la puce. Ce cache était appelé cache de niveau 1 (L1) pour le différencier du cache de niveau 2 (L2), plus lent et situé sur la carte mère. Ces derniers étaient beaucoup plus volumineux, la taille la plus courante étant de 256 Kio. Certaines cartes mères disposaient d'emplacements pour la carte fille Intel 485Turbocache , dotée de 64 ou 128 Ko de mémoire cache. La popularité du cache sur carte mère s'est maintenue durant l' ère Pentium MMX , mais a été rendue obsolète par l'introduction de la SDRAM et l'écart croissant entre les fréquences d'horloge du bus et du processeur, ce qui a fait que le cache sur carte mère n'était plus que légèrement plus rapide que la mémoire principale.
L'évolution suivante en matière d'implémentation de cache dans les microprocesseurs x86 a commencé avec le Pentium Pro , qui a intégré le cache secondaire dans le même boîtier que le microprocesseur, cadencé à la même fréquence que ce dernier.
Les caches intégrés à la carte mère ont longtemps bénéficié d'une grande popularité grâce aux processeurs AMD K6-2 et AMD K6-III , qui utilisaient encore le socket 7 , précédemment employé par Intel avec des caches intégrés. Le K6-III intégrait 256 Kio de cache L2 et exploitait le cache intégré comme cache de troisième niveau, appelé L3 (des cartes mères avec jusqu'à 2 Mio de cache intégré ont été produites). Après l'obsolescence du socket 7, le cache intégré à la carte mère a disparu des systèmes x86.
Les caches à trois niveaux ont été réutilisés pour la première fois avec l'introduction du processeur Intel Xeon MP « Foster Core » , où le cache L3 a été ajouté à la puce du processeur. Il est devenu courant que la taille totale du cache augmente avec les nouvelles générations de processeurs, et récemment (en 2011), il n'est pas rare de trouver des caches de niveau 3 de plusieurs dizaines de mégaoctets
Intel a introduit un cache de niveau 4 intégré avec la microarchitecture Haswell . Les processeurs Crystalwell Haswell, équipés de la variante GT3e du processeur graphique intégré Intel Iris Pro, disposent de 128 Mio de mémoire DRAM embarquée ( eDRAM ) sur le même boîtier. Ce cache L4 est partagé dynamiquement entre le GPU et le CPU intégrés, et sert de cache victime au cache L3 du CPU.
Dans les microprocesseurs ARM
Le processeur Apple M1 dispose de 128 ou 192 Kio de cache d'instructions L1 par cœur (important pour la latence et les performances monocœur), selon le type de cœur. Il s'agit d'un cache L1 exceptionnellement important pour un processeur (et pas seulement pour un ordinateur portable). La taille totale de la mémoire cache n'est pas particulièrement élevée pour un ordinateur portable (c'est le total qui importe le plus pour le débit), et des tailles totales bien supérieures (par exemple, L3 ou L4) sont disponibles sur les ordinateurs centraux IBM.
Recherches actuelles
Les premières conceptions de cache se concentraient exclusivement sur le coût direct du cache et de la RAM , ainsi que sur la vitesse d'exécution moyenne. Les conceptions de cache plus récentes prennent également en compte l'efficacité énergétique , la tolérance aux pannes et d'autres objectifs.
Plusieurs outils sont à la disposition des architectes informatiques pour les aider à explorer les compromis entre le temps de cycle du cache, l'énergie et la surface ; le simulateur de cache CACTI et le simulateur de jeu d'instructions SimpleScalar sont deux options open-source.
Cache multiport
Un cache multiport est un cache capable de traiter plusieurs requêtes simultanément. Alors qu'un cache traditionnel utilise généralement une seule adresse mémoire, un cache multiport peut permettre de demander N adresses à la fois, N étant le nombre de ports connectés entre le processeur et le cache. L'avantage est qu'un processeur pipeliné peut accéder à la mémoire depuis différentes phases de son pipeline. Autre avantage : il rend possible le concept de processeurs superscalaires grâce à différents niveaux de cache.
Plus d articles de Worldlex Wiki
Revenez a l index pour explorer davantage de pages sur l histoire, la science, la culture, la geographie et la societe en francais.
Explorer l index
Problèmes d'homonymie et de synonymie
Un cache reposant sur l'indexation et l'étiquetage virtuels devient incohérent lorsqu'une même adresse virtuelle est associée à différentes adresses physiques ( homonymie ). Ce problème peut être résolu en utilisant l'adresse physique pour l'étiquetage, ou en stockant l'identifiant de l'espace d'adressage dans la ligne de cache. Cependant, cette dernière approche ne résout pas le problème des synonymes , où plusieurs lignes de cache finissent par stocker des données pour la même adresse physique. L'écriture à ces emplacements peut ne mettre à jour qu'un seul emplacement dans le cache, laissant les autres avec des données incohérentes. Ce problème peut être résolu en utilisant des dispositions mémoire non chevauchantes pour différents espaces d'adressage, ou bien en vidant le cache (ou une partie de celui-ci) lors de tout changement d'association.
Étiquettes et indices virtuels
Le principal avantage des étiquettes virtuelles est que, pour les caches associatifs, elles permettent d'effectuer la correspondance des étiquettes avant la traduction virtuelle-physique. Cependant, les sondages de cohérence et les évictions fournissent une adresse physique pour l'action. Le matériel doit disposer d'un moyen de convertir les adresses physiques en un index de cache, généralement en stockant à la fois les étiquettes physiques et virtuelles. Par comparaison, un cache à étiquettes physiques n'a pas besoin de conserver d'étiquettes virtuelles, ce qui est plus simple. Lorsqu'une correspondance virtuelle-physique est supprimée du TLB, les entrées de cache associées à ces adresses virtuelles doivent être vidées. De même, si des entrées de cache sont autorisées sur des pages non mappées par le TLB, ces entrées doivent être vidées lorsque les droits d'accès à ces pages sont modifiés dans la table des pages.
Le système d'exploitation peut également garantir qu'aucun alias virtuel ne réside simultanément dans le cache. Il assure cette garantie en appliquant la coloration des pages, décrite ci-dessous. Certains processeurs RISC anciens (SPARC, RS/6000) utilisaient cette approche. Elle n'est plus employée aujourd'hui, car le coût matériel de la détection et de la suppression des alias virtuels a diminué, tandis que la complexité logicielle et la perte de performance liées à une coloration parfaite des pages ont augmenté.
Il peut être utile de distinguer les deux fonctions des étiquettes dans un cache associatif : elles servent à déterminer le sens de sélection de l’ensemble d’entrées, et elles servent à déterminer si la recherche a réussi ou échoué. La seconde fonction doit toujours être correcte, mais la première peut occasionnellement faire des suppositions et donner une réponse erronée.
Certains processeurs (par exemple, les premiers SPARC) possèdent des caches à la fois virtuels et physiques. Les étiquettes virtuelles servent à la sélection du chemin d'accès, tandis que les étiquettes physiques déterminent si l'accès a réussi ou échoué. Ce type de cache bénéficie de la faible latence d'un cache à étiquettes virtuelles et de la simplicité d'interface logicielle d'un cache à étiquettes physiques. Il présente toutefois l'inconvénient supplémentaire des étiquettes dupliquées. De plus, lors du traitement d'un échec d'accès, les chemins d'accès alternatifs de la ligne de cache indexée doivent être analysés afin de détecter les alias virtuels et d'éliminer toute correspondance.
L'espace supplémentaire (et la latence accrue) peut être atténué en conservant des indications virtuelles pour chaque entrée de cache, au lieu d'étiquettes virtuelles. Ces indications sont un sous-ensemble ou un hachage de l'étiquette virtuelle et servent à sélectionner la zone de cache à partir de laquelle récupérer les données et une étiquette physique. Comme pour un cache à étiquettes virtuelles, il peut y avoir une correspondance entre une indication virtuelle et une différence d'étiquette physique. Dans ce cas, l'entrée de cache avec l'indication correspondante doit être supprimée afin que les accès au cache après son remplissage à cette adresse ne comportent qu'une seule correspondance d'indication. Étant donné que les indications virtuelles possèdent moins de bits de distinction que les étiquettes virtuelles, un cache utilisant des indications virtuelles subit davantage de défauts de cache liés à des conflits qu'un cache à étiquettes virtuelles.
La réduction ultime des indications virtuelles se trouve peut-être dans le Pentium 4 (cœurs Willamette et Northwood). Sur ces processeurs, l'indication virtuelle est réduite à deux bits et le cache est associatif par ensembles à quatre voies. Concrètement, le matériel maintient une simple permutation entre l'adresse virtuelle et l'index du cache, ce qui rend inutile l'utilisation de la mémoire associative (CAM) pour sélectionner la bonne adresse parmi les quatre voies d'accès.
Coloriage
Le problème, c'est que si toutes les pages utilisées à un instant donné peuvent avoir des couleurs virtuelles différentes, certaines peuvent avoir la même couleur physique. En fait, si le système d'exploitation attribue des pages physiques aux pages virtuelles de manière aléatoire et uniforme, il est fort probable que certaines pages aient la même couleur physique, et que les adresses de ces pages entrent alors en conflit dans le cache (c'est le paradoxe des anniversaires ).
La solution consiste à ce que le système d'exploitation tente d'attribuer des couleurs physiques différentes à des couleurs virtuelles différentes, une technique appelée coloration des pages . Bien que la correspondance exacte entre les couleurs virtuelles et physiques soit sans incidence sur les performances du système, les correspondances complexes sont difficiles à gérer et présentent peu d'avantages. C'est pourquoi la plupart des méthodes de coloration des pages visent simplement à conserver les mêmes couleurs physiques et virtuelles.
Si le système d'exploitation garantit que chaque page physique correspond à une seule couleur virtuelle, il n'y a pas d'alias virtuels et le processeur peut utiliser des caches indexés virtuellement sans avoir besoin de sondes d'alias virtuels supplémentaires lors de la gestion des défauts. Le système d'exploitation peut également vider le cache d'une page à chaque changement de couleur virtuelle. Comme indiqué précédemment, cette approche a été utilisée dans certaines architectures SPARC et RS/6000 de première génération.
La technique de coloration logicielle des pages a été utilisée pour partitionner efficacement le cache de dernier niveau (LLC) partagé dans les processeurs multicœurs. Cette gestion du LLC basée sur le système d'exploitation dans les processeurs multicœurs a été adoptée par Intel.
Hiérarchie de mémoire d'un serveur AMD Bulldozer Les processeurs modernes possèdent plusieurs caches sur puce interagissant entre eux. Le fonctionnement d'un cache particulier peut être entièrement spécifié par sa taille, la taille des blocs de cache, le nombre de blocs dans un ensemble, la politique de remplacement des ensembles de cache et la politique d'écriture du cache (écriture immédiate ou écriture différée).
Bien que tous les blocs d'un cache donné aient la même taille et la même associativité, les caches de « niveau supérieur » (appelés caches de niveau 1) possèdent généralement un nombre de blocs plus faible, une taille de bloc plus petite et un ensemble de blocs plus restreint, mais offrent des temps d'accès très courts. Les caches de « niveau inférieur » (c'est-à-dire de niveau 2 et inférieurs) possèdent un nombre de blocs progressivement plus important, une taille de bloc plus grande, un ensemble de blocs plus dense et des temps d'accès relativement plus longs, mais restent beaucoup plus rapides que la mémoire principale.
La politique de remplacement des entrées du cache est déterminée par un algorithme de cache choisi par les concepteurs du processeur. Dans certains cas, plusieurs algorithmes sont proposés pour différents types de charges de travail.
Caches spécialisées
Les processeurs pipelinés accèdent à la mémoire à partir de plusieurs points du pipeline : extraction des instructions, traduction d'adresses virtuelles en adresses physiques et extraction des données (voir le pipeline RISC classique ). Naturellement, on utilise des caches physiques différents pour chacun de ces points, afin qu'une même ressource physique ne soit pas affectée à deux points du pipeline. Le pipeline comporte ainsi naturellement au moins trois caches distincts (instructions, TLB et données), chacun spécialisé dans son rôle spécifique.
Cache de victimes
Norman Jouppi de DEC en 1990. La variante Crystalwell des processeurs Haswell d'Intel intégrait un cache eDRAM de niveau 4 de 128 Mio , servant de cache victime au cache de niveau 3 du processeur. Dans la microarchitecture Skylake, le cache de niveau 4 ne fonctionne plus comme cache victime.
Intel Pentium 4. Un cache de traces est un mécanisme permettant d'augmenter la bande passante de récupération des instructions et de diminuer la consommation d'énergie (dans le cas du Pentium 4) en stockant les traces des instructions qui ont déjà été récupérées et décodées. Un cache de traces stocke les instructions soit après leur décodage, soit au fur et à mesure de leur suppression. Généralement, les instructions sont ajoutées aux caches de traces par groupes représentant soit des blocs de base individuels , soit des traces d'instructions dynamiques. Le cache de traces du Pentium 4 stocke les micro-opérations résultant du décodage des instructions x86, offrant ainsi la fonctionnalité d'un cache de micro-opérations. Grâce à cela, la prochaine fois qu'une instruction sera nécessaire, il ne sera pas nécessaire de la décoder à nouveau en micro-opérations.
Cache de fusion d'écriture (WCC)
Le cache de coalescence d'écriture (WCC ) est un cache spécial faisant partie du cache L2 de la microarchitecture Bulldozer d' AMD . Les données écrites provenant des deux caches L1D du module transitent par le WCC, où elles sont mises en mémoire tampon et fusionnées. Le WCC a pour fonction de réduire le nombre d'écritures dans le cache L2.
les micro-opérations des instructions décodées, telles que reçues directement des décodeurs d'instructions ou du cache d'instructions. Lorsqu'une instruction doit être décodée, le cache μop vérifie si sa forme décodée s'y trouve ; si elle n'est pas disponible, l'instruction est décodée puis mise en cache.L'un des premiers travaux décrivant le cache μop comme une interface alternative pour la famille de processeurs Intel P6 est l'article de 2001 intitulé « Micro-Operation Cache: A Power Aware Frontend for Variable Instruction Length ISA » . Par la suite, Intel a intégré des caches μop dans ses processeurs Sandy Bridge et dans les microarchitectures successives telles qu'Ivy Bridge et Haswell : a implémenté un cache μop dans sa microarchitecture Zen .
L'accès à des instructions complètes pré-décodées élimine la nécessité de décoder à répétition des instructions complexes de longueur variable en micro-opérations plus simples de longueur fixe, et simplifie le processus de prédiction, d'accès, de rotation et d'alignement des instructions récupérées. Un cache de micro-opérations décharge efficacement le matériel d'accès et de décodage, réduisant ainsi la consommation d'énergie et améliorant la fourniture de micro-opérations décodées au processeur. Le cache de micro-opérations améliore également les performances en fournissant de manière plus constante les micro-opérations décodées au processeur et en éliminant divers goulots d'étranglement dans la logique d'accès et de décodage du processeur.
Un cache μop présente de nombreuses similitudes avec un cache de traces, mais il est beaucoup plus simple, ce qui lui confère une meilleure efficacité énergétique ; il est donc mieux adapté aux implémentations sur des appareils alimentés par batterie. Le principal inconvénient du cache de traces, à l’origine de son inefficacité énergétique, réside dans la complexité matérielle requise pour son heuristique de décision concernant la mise en cache et la réutilisation des traces d’instructions créées dynamiquement.
cache d'instructions de la cible de branchement
Un cache de cible de branchement , ou cache d'instructions de cible de branchement (nom utilisé sur les microprocesseurs ARM ) est un cache spécialisé qui stocke les premières instructions à l'adresse de destination d'un branchement. Il est utilisé par les processeurs basse consommation qui n'ont pas besoin d'un cache d'instructions classique, car leur système mémoire est capable de fournir les instructions suffisamment rapidement pour satisfaire le processeur. Cependant, cela ne s'applique qu'aux instructions consécutives ; le redémarrage de la récupération d'une instruction à une nouvelle adresse nécessite toujours plusieurs cycles de latence, ce qui provoque une brève oscillation du pipeline après un transfert de contrôle. Un cache de cible de branchement fournit les instructions pour ces quelques cycles, évitant ainsi un délai après la plupart des branchements.
Cela permet un fonctionnement à pleine vitesse avec un cache beaucoup plus petit qu'un cache d'instructions traditionnel à temps plein.
Cache intelligent
Le cache intelligent est une méthode de mise en cache de niveau 2 ou 3 pour plusieurs cœurs d'exécution, développée par Intel .
Le cache intelligent partage la mémoire cache entre les cœurs d'un processeur multicœur . Comparé à un cache dédié par cœur, le taux global d'échecs de cache diminue lorsque les cœurs n'ont pas besoin de parts égales de l'espace cache. Par conséquent, un seul cœur peut utiliser la totalité du cache de niveau 2 ou 3 tandis que les autres cœurs sont inactifs. De plus, le cache partagé accélère le partage de mémoire entre les différents cœurs d'exécution.
eDRAM et montés sur un module multi-puces , constituant ainsi un quatrième niveau de cache. Dans de rares cas, comme pour le processeur du mainframe IBM z15 (2019), tous les niveaux jusqu'au cache L1 sont implémentés en eDRAM, remplaçant entièrement la SRAM (pour le cache, la SRAM étant toujours utilisée pour les registres ). La gamme de processeurs Apple Silicon , basée sur l'architecture ARM et comprenant les A14 et M1 , dispose d'un cache L1i de 192 Kio pour chacun des cœurs hautes performances, une capacité exceptionnellement élevée ; en revanche, les cœurs basse consommation ne disposent que de 128 Kio. Depuis, d'autres processeurs tels que Lunar Lake d' Intel et Oryon de Qualcomm ont également implémenté des tailles de cache L1i similaires.Les avantages des caches L3 et L4 dépendent des modèles d'accès de l'application. Voici quelques exemples de produits intégrant des caches L3 et L4 :
- Alpha 21164 (1995) disposait d'un cache L3 hors puce de 1 à 64 Mio.
- L'AMD K6-III (1999) disposait d'un cache L3 basé sur la carte mère.
- IBM POWER4 (2001) disposait de caches L3 hors puce de 32 Mio par processeur, partagés entre plusieurs processeurs.
- L'Itanium 2 (2003) disposait d'un cache Itanium 2 (2003) MX 2 incorporait deux processeurs Itanium 2 ainsi qu'un cache L4 partagé de 64 Mio sur un module multi-puces compatible broche à broche avec un processeur Madison.
- Le produit Intel Xeon MP, nom de code « Tulsa » (2006), dispose de 16 Mio de cache L3 intégré partagé entre deux cœurs de processeur.
- AMD Phenom (2007) avec 2 Mio de cache L3.
- L'AMD Phenom II (2008) dispose d'un cache L3 unifié sur puce allant jusqu'à 6 Mio.
- Intel Core i7 (2008) possède un cache L3 unifié sur puce de 8 Mio, inclusif et partagé par tous les cœurs.
- Les processeurs Intel Haswell avec carte graphique intégrée Intel Iris Pro disposent de 128 Mio d'eDRAM faisant essentiellement office de cache L4.
Enfin, à l'autre extrémité de la hiérarchie mémoire, le fichier de registres du processeur peut être considéré comme le cache le plus petit et le plus rapide du système. Sa particularité réside dans le fait qu'il est géré par logiciel, généralement par le compilateur, qui alloue des registres pour stocker les valeurs extraites de la mémoire principale, par exemple pour l'optimisation des boucles imbriquées . Cependant, grâce au renommage des registres , la plupart des affectations de registres du compilateur sont réallouées dynamiquement par le matériel à l'exécution dans un banc de registres, permettant ainsi au processeur de rompre les dépendances de données erronées et d'atténuer les risques liés au pipeline.
Les fichiers de registres présentent parfois une hiérarchie : le Cray-1 (vers 1976) disposait de huit registres d’adresse « A » et de huit registres de données scalaires « S » généralement utilisables. Il comportait également 64 registres d’adresse « B » et 64 registres de données scalaires « T », dont l’accès était plus lent, mais plus rapide que la mémoire principale. Les registres « B » et « T » étaient nécessaires car le Cray-1 ne possédait pas de cache de données. (Le Cray-1 disposait toutefois d’un cache d’instructions.)
multicœur , la question se pose de savoir si les caches doivent être partagés ou locaux à chaque cœur. La mise en œuvre d'un cache partagé engendre inévitablement un câblage plus complexe. En revanche, disposer d'un cache par puce , plutôt que par cœur , réduit considérablement l'espace nécessaire et permet ainsi d'intégrer un cache de plus grande capacité.En règle générale, le partage du cache L1 est déconseillé car l'augmentation de latence qui en résulte ralentirait considérablement chaque cœur par rapport à une puce monocœur. Cependant, pour le cache de plus haut niveau (généralement L3, le dernier appelé avant l'accès à la mémoire), un cache global est souhaitable pour plusieurs raisons : il permet à un seul cœur d'utiliser l'intégralité du cache, réduit la redondance des données en autorisant différents processus ou threads à partager les données mises en cache, et simplifie les protocoles de cohérence de cache utilisés. Par exemple, une puce à huit cœurs avec trois niveaux de cache peut inclure un cache L1 par cœur, un cache L2 intermédiaire pour chaque paire de cœurs et un cache L3 partagé par tous les cœurs.
Un cache de niveau le plus élevé partagé (généralement L3, appelé avant l'accès à la mémoire) est généralement désigné sous le nom de cache de dernier niveau (LLC). Des techniques supplémentaires sont utilisées pour augmenter le niveau de parallélisme lorsque le LLC est partagé entre plusieurs cœurs, notamment en le divisant en plusieurs morceaux qui adressent des plages d'adresses mémoire spécifiques et peuvent être utilisés indépendamment.
Séparés versus unifiés
Dans une structure de cache séparée, les instructions et les données sont mises en cache séparément ; une ligne de cache sert donc soit aux instructions, soit aux données, mais pas aux deux. L’utilisation de tampons de traduction d’instructions et de données distincts présente divers avantages . Dans une structure unifiée, cette contrainte disparaît et les lignes de cache peuvent servir à la fois aux instructions et aux données.
AMD Athlon ) utilisent des caches exclusifs : les données sont garanties de se trouver dans au plus l'un des caches L1 ou L2, jamais dans les deux. D'autres processeurs encore (comme les Intel Pentium II , III et 4 ) n'exigent pas que les données du cache L1 résident également dans le cache L2, bien que cela soit souvent le cas. Il n'existe pas de nom universellement accepté pour cette politique intermédiaire ; deux appellations courantes sont « non exclusif » et « partiellement inclusif ».L’avantage des caches exclusifs réside dans leur capacité de stockage supérieure. Cet avantage est plus marqué lorsque le cache L1 exclusif est comparable au cache L2, et diminue si le cache L2 est beaucoup plus grand que le cache L1. En cas d’échec d’accès dans le cache L1 et de succès dans le cache L2, la ligne correspondante dans le cache L2 est échangée avec une ligne du cache L1. Cet échange est beaucoup plus complexe que la simple copie d’une ligne du cache L2 vers le cache L1, opération effectuée par un cache inclusif.
L'un des avantages des caches strictement inclusifs est que, lorsqu'un périphérique externe ou un autre processeur d'un système multiprocesseur souhaite supprimer une ligne de cache du processeur, il suffit que ce dernier consulte le cache L2. Dans les hiérarchies de caches n'imposant pas l'inclusion, le cache L1 doit également être consulté. En revanche, il existe une corrélation entre les associativités des caches L1 et L2 : si le cache L2 ne possède pas au moins autant de voies que l'ensemble des caches L1, l'associativité effective de ces derniers est limitée. Un autre inconvénient des caches inclusifs est que, lors de toute éviction dans le cache L2, les lignes (potentiellement) correspondantes dans le cache L1 doivent également être évincées afin de maintenir l'inclusivité. Cette opération est conséquente et entraîne un taux d'échecs de cache L1 plus élevé.
Un autre avantage des caches inclusifs est que le cache principal peut utiliser des lignes de cache plus larges, ce qui réduit la taille des étiquettes du cache secondaire. (Les caches exclusifs exigent que les deux caches aient des lignes de cache de même taille, afin que les lignes puissent être permutées en cas d'échec de cache L1 et de succès de cache L2.) Si le cache secondaire est dix fois plus grand que le cache principal, et que les données du cache sont dix fois plus grandes que les étiquettes de cache, la surface d'étiquettes ainsi économisée peut être comparable à la surface incrémentale nécessaire pour stocker les données du cache L1 dans le cache L2.
Mémoire du bloc-notes
La mémoire scratchpad (SPM), également connue sous le nom de mémoire scratchpad, mémoire RAM scratchpad ou mémoire locale dans la terminologie informatique, est une mémoire interne à haute vitesse utilisée pour le stockage temporaire de calculs, de données et d'autres travaux en cours.Exemple : le K8
Pour illustrer à la fois la spécialisation et la mise en cache multiniveau, voici la hiérarchie de cache du cœur K8 du processeur AMD Athlon 64.
Hiérarchie du cache du cœur K8 du processeur AMD Athlon 64 Le K8 possède quatre caches spécialisés : un cache d’instructions, un TLB d’instructions , un TLB de données et un cache de données. Chacun de ces caches est spécialisé :
- Le cache d'instructions conserve des copies de lignes de mémoire de 64 octets et en extrait 16 à chaque cycle. Chaque octet de ce cache est stocké sur dix bits au lieu de huit, les bits supplémentaires marquant les limites des instructions (il s'agit d'un exemple de prédécodage). Le cache utilise uniquement la parité plutôt que la correction d'erreurs (ECC ), car la parité est plus petite et toute donnée corrompue peut être remplacée par des données fraîches extraites de la mémoire (qui contient toujours une copie à jour des instructions).
- Le TLB d'instructions conserve des copies des entrées de table des pages (PTE). À chaque cycle, l'adresse virtuelle de chaque instruction est traduite par ce TLB en une adresse physique. Chaque entrée occupe quatre ou huit octets en mémoire. Le K8 ayant une taille de page variable, chaque TLB est divisé en deux sections : l'une pour les PTE correspondant à des pages de 4 Kio, l'autre pour celles correspondant à des pages de 4 Mio ou 2 Mio. Cette division simplifie le circuit d'association dans chaque section. Le système d'exploitation associe des PTE de tailles différentes aux différentes sections de l'espace d'adressage virtuel.
- Le TLB de données possède deux copies contenant des entrées identiques. Ces deux copies permettent deux accès aux données par cycle pour traduire les adresses virtuelles en adresses physiques. À l'instar du TLB d'instructions, ce TLB est divisé en deux types d'entrées.
- Le cache de données conserve des copies de lignes de mémoire de 64 octets. Il est divisé en 8 banques (chacune stockant 8 Kio de données) et peut accéder à deux ensembles de données de 8 octets par cycle, à condition qu'ils se trouvent dans des banques différentes. Il existe deux copies des étiquettes, car chaque ligne de 64 octets est répartie entre les huit banques. Chaque copie d'étiquette gère l'un des deux accès par cycle.
Le K8 dispose également de caches à plusieurs niveaux. Il existe des TLB d'instructions et de données de second niveau, qui stockent uniquement des entrées de table de pages (PTE) mappant 4 KiB. Les caches d'instructions et de données, ainsi que les différents TLB, peuvent être alimentés par le vaste cache L2 unifié . Ce cache est exclusif aux caches d'instructions et de données L1, ce qui signifie que toute ligne de 8 octets ne peut se trouver que dans l'un des caches suivants : le cache d'instructions L1, le cache de données L1 ou le cache L2. Il est toutefois possible qu'une ligne du cache de données contienne une PTE présente également dans l'un des TLB ; le système d'exploitation assure la cohérence des TLB en vidant certaines portions de ces derniers lors de la mise à jour des tables de pages en mémoire.
Le K8 met également en cache des informations qui ne sont jamais stockées en mémoire : les informations de prédiction. Ces caches ne sont pas représentés sur le schéma ci-dessus. Comme c'est souvent le cas pour ce type de processeur, le K8 dispose d'une prédiction de branchement assez complexe , avec des tables permettant de prédire si des branchements seront effectués et d'autres tables prédisant les cibles des branchements et des sauts. Certaines de ces informations sont associées aux instructions, à la fois dans le cache d'instructions de niveau 1 et dans le cache secondaire unifié.
Le K8 utilise une astuce ingénieuse pour stocker les informations de prédiction avec les instructions dans le cache secondaire. Les lignes de ce cache sont protégées contre toute corruption accidentelle de données (par exemple, suite à l'impact d'une particule alpha ) par un système de correction d'erreurs (ECC) ou par parité , selon qu'elles proviennent du cache principal de données ou d'instructions. Le code de parité occupant moins de bits que le code ECC, les lignes du cache d'instructions disposent de quelques bits supplémentaires. Ces bits servent à stocker les informations de prédiction de branchement associées à ces instructions. Il en résulte un historique de branchement plus étendu pour le prédicteur de branchement, et donc une meilleure précision.
Plus de hiérarchies
D'autres processeurs disposent d'autres types de prédicteurs (par exemple, le prédicteur de contournement de stockage à chargement dans le DEC Alpha 21264 ).
Ces prédicteurs sont des caches, car ils stockent des informations dont le calcul est coûteux. Certains termes employés pour parler des prédicteurs sont les mêmes que ceux utilisés pour les caches (on parle par exemple de « succès » dans un prédicteur de branchement), mais les prédicteurs ne sont généralement pas considérés comme faisant partie de la hiérarchie des caches.
Le K8 assure la cohérence matérielle des caches d'instructions et de données, ce qui signifie qu'une instruction de stockage effectuée juste après une autre modifiera l'instruction suivante. D'autres processeurs, comme ceux des familles Alpha et MIPS, s'appuient sur le logiciel pour maintenir la cohérence du cache d'instructions. L'affichage des instructions de stockage dans le flux d'instructions n'est garanti que lorsqu'un programme appelle une fonction du système d'exploitation pour assurer cette cohérence.
Étiquette RAM
Tag RAM sur la carte d'un Intel Pentium III En génie informatique, une mémoire RAM étiquetée permet de spécifier quelle adresse mémoire est actuellement stockée dans le cache du processeur. Pour une conception simple à correspondance directe, une SRAM rapide peut être utilisée. Les caches associatifs de niveau supérieur utilisent généralement une mémoire adressable par contenu .
Mise en œuvre
Chemin de lecture pour un cache associatif à deux voies Le schéma ci-contre vise à clarifier l'utilisation des différents champs de l'adresse. Le bit 31 est le plus significatif, le bit 0 le moins significatif. Ce schéma représente les SRAM, l'indexation et le multiplexage d'un cache de 4 Kio, associatif par ensembles à deux voies, indexé et étiqueté virtuellement, avec des lignes de 64 octets (B), une largeur de lecture de 32 bits et une adresse virtuelle de 32 bits.
Le cache ayant une capacité de 4 KiB et comportant 64 lignes d'octets, il ne contient que 64 lignes. La lecture s'effectue par paires à partir d'une SRAM d'étiquettes de 32 lignes, chacune associée à une paire d'étiquettes de 21 bits. Bien que toute fonction des bits d'adresse virtuelle 31 à 6 puisse être utilisée pour indexer les SRAM d'étiquettes et de données, l'utilisation des bits de poids faible est plus simple.
De même, étant donné que le cache fait 4 KiB et possède un chemin de lecture de 4 B, et qu'il lit de deux manières pour chaque accès, la SRAM de données comporte 512 lignes de 8 octets de large.
Un cache plus moderne pourrait avoir une capacité de 16 Kio, être associatif par ensembles à 4 voies, indexé virtuellement, avec des indications virtuelles et un marquage physique, avec des lignes de 32 octets, une largeur de lecture de 32 bits et des adresses physiques de 36 bits. Le chemin de lecture pour un tel cache est très similaire à celui décrit précédemment. Au lieu d'étiquettes, ce sont des indications virtuelles qui sont lues et comparées à un sous-ensemble de l'adresse virtuelle. Plus tard dans le pipeline, l'adresse virtuelle est traduite en adresse physique par le TLB, et l'étiquette physique correspondante est lue (une seule, car l'indication virtuelle indique le sens de lecture dans le cache). Enfin, l'adresse physique est comparée à l'étiquette physique pour déterminer si une correspondance a été trouvée.
Certaines conceptions SPARC ont amélioré la vitesse de leurs caches L1 de quelques délais de porte en intégrant l'additionneur d'adresses virtuelles dans les décodeurs SRAM.aux registres . Mais depuis les années 1980 l'écart de performance entre le processeur et la mémoire n'a cessé de se creuser. Les microprocesseurs ont progressé beaucoup plus vite que la mémoire, notamment en termes de fréquence de fonctionnement , faisant de cette dernière un goulot d'étranglement. S'il était techniquement possible d'avoir une mémoire principale aussi rapide que le processeur, une solution plus économique a été privilégiée : utiliser une grande quantité de mémoire basse vitesse, tout en intégrant une petite mémoire cache haute vitesse pour compenser l'écart de performance. Cette approche a permis d'obtenir une capacité dix fois supérieure – pour un coût identique – avec une légère diminution des performances globales.
Premières implémentations TLB
Les premières utilisations documentées d'un TLB ont eu lieu sur le GE 645 et l' IBM 360/67 , qui utilisaient tous deux une mémoire associative comme TLB.
Cache de première instruction
La première utilisation documentée d'un cache d'instructions a eu lieu sur le CDC 6600.
Premier cache de données
La première utilisation documentée d'un cache de données a eu lieu sur le système IBM System/360 modèle 85.
Dans les microprocesseurs 68k
Le 68010 , sorti en 1982, dispose d'un « mode boucle » pouvant être considéré comme un cache d'instructions réduit et spécifique, accélérant les boucles composées de seulement deux instructions. Le 68020 , sorti en 1984, a remplacé ce mode par un cache d'instructions classique de 256 octets, devenant ainsi le premier processeur de la série 68k à intégrer une véritable mémoire cache sur puce.
Le 68030 , sorti en 1987, est essentiellement un cœur 68020 avec un cache de données supplémentaire de 256 octets, une unité de gestion de la mémoire sur puce (MMU), une réduction de processus et un mode rafale ajouté pour les caches.
Le 68040 , sorti en 1990, possède des caches d'instructions et de données séparés de quatre kilo-octets chacun.
Le 68060 , sorti en 1994, possède les éléments suivants : cache de données de 8 KiB (associatif à quatre voies), cache d'instructions de 8 KiB (associatif à quatre voies), tampon d'instructions FIFO de 96 octets, cache de branchement de 256 entrées et tampon MMU de cache de traduction d'adresses de 64 entrées (associatif à quatre voies).
Dans les microprocesseurs x86
Exemple de carte mère avec un microprocesseur i386 (33 MHz), 64 KiB de cache (25 ns ; 8 puces dans le coin inférieur gauche), 2 Mio de DRAM (70 ns ; 8 SIMM à droite du cache) et un contrôleur de cache ( Austek A38202 ; à droite du processeur). Avec l'arrivée des microprocesseurs x86 à des fréquences d'horloge de 20 MHz et plus (notamment l' A386) , de petites quantités de mémoire cache rapide ont commencé à être intégrées aux systèmes pour améliorer leurs performances. En effet, la DRAM utilisée comme mémoire principale présentait une latence importante, pouvant atteindre 120 ns, ainsi que des cycles de rafraîchissement. Le cache était constitué de cellules de mémoire SRAM , plus coûteuses mais nettement plus rapides, dont la latence était alors de l'ordre de 10 à 25 ns. Les premiers caches étaient externes au processeur et généralement situés sur la carte mère sous la forme de huit ou neuf composants DIP insérés dans des supports, permettant ainsi d'ajouter le cache en option ou de l'étendre.
Certaines versions du processeur Intel 386 pouvaient prendre en charge de 16 à 256 KiB de cache externe.
Avec le processeur 486 , un cache de 8 Kio était intégré directement à la puce. Ce cache était appelé cache de niveau 1 (L1) pour le différencier du cache de niveau 2 (L2), plus lent et situé sur la carte mère. Ces derniers étaient beaucoup plus volumineux, la taille la plus courante étant de 256 Kio. Certaines cartes mères disposaient d'emplacements pour la carte fille Intel 485Turbocache , dotée de 64 ou 128 Ko de mémoire cache. La popularité du cache sur carte mère s'est maintenue durant l' ère Pentium MMX , mais a été rendue obsolète par l'introduction de la SDRAM et l'écart croissant entre les fréquences d'horloge du bus et du processeur, ce qui a fait que le cache sur carte mère n'était plus que légèrement plus rapide que la mémoire principale.
L'évolution suivante en matière d'implémentation de cache dans les microprocesseurs x86 a commencé avec le Pentium Pro , qui a intégré le cache secondaire dans le même boîtier que le microprocesseur, cadencé à la même fréquence que ce dernier.
Les caches intégrés à la carte mère ont longtemps bénéficié d'une grande popularité grâce aux processeurs AMD K6-2 et AMD K6-III , qui utilisaient encore le socket 7 , précédemment employé par Intel avec des caches intégrés. Le K6-III intégrait 256 Kio de cache L2 et exploitait le cache intégré comme cache de troisième niveau, appelé L3 (des cartes mères avec jusqu'à 2 Mio de cache intégré ont été produites). Après l'obsolescence du socket 7, le cache intégré à la carte mère a disparu des systèmes x86.
Les caches à trois niveaux ont été réutilisés pour la première fois avec l'introduction du processeur Intel Xeon MP « Foster Core » , où le cache L3 a été ajouté à la puce du processeur. Il est devenu courant que la taille totale du cache augmente avec les nouvelles générations de processeurs, et récemment (en 2011), il n'est pas rare de trouver des caches de niveau 3 de plusieurs dizaines de mégaoctets
Intel a introduit un cache de niveau 4 intégré avec la microarchitecture Haswell . Les processeurs Crystalwell Haswell, équipés de la variante GT3e du processeur graphique intégré Intel Iris Pro, disposent de 128 Mio de mémoire DRAM embarquée ( eDRAM ) sur le même boîtier. Ce cache L4 est partagé dynamiquement entre le GPU et le CPU intégrés, et sert de cache victime au cache L3 du CPU.
Dans les microprocesseurs ARM
Le processeur Apple M1 dispose de 128 ou 192 Kio de cache d'instructions L1 par cœur (important pour la latence et les performances monocœur), selon le type de cœur. Il s'agit d'un cache L1 exceptionnellement important pour un processeur (et pas seulement pour un ordinateur portable). La taille totale de la mémoire cache n'est pas particulièrement élevée pour un ordinateur portable (c'est le total qui importe le plus pour le débit), et des tailles totales bien supérieures (par exemple, L3 ou L4) sont disponibles sur les ordinateurs centraux IBM.
Recherches actuelles
Les premières conceptions de cache se concentraient exclusivement sur le coût direct du cache et de la RAM , ainsi que sur la vitesse d'exécution moyenne. Les conceptions de cache plus récentes prennent également en compte l'efficacité énergétique , la tolérance aux pannes et d'autres objectifs.
Plusieurs outils sont à la disposition des architectes informatiques pour les aider à explorer les compromis entre le temps de cycle du cache, l'énergie et la surface ; le simulateur de cache CACTI et le simulateur de jeu d'instructions SimpleScalar sont deux options open-source.
Cache multiport
Un cache multiport est un cache capable de traiter plusieurs requêtes simultanément. Alors qu'un cache traditionnel utilise généralement une seule adresse mémoire, un cache multiport peut permettre de demander N adresses à la fois, N étant le nombre de ports connectés entre le processeur et le cache. L'avantage est qu'un processeur pipeliné peut accéder à la mémoire depuis différentes phases de son pipeline. Autre avantage : il rend possible le concept de processeurs superscalaires grâce à différents niveaux de cache.
Plus d articles de Worldlex Wiki
Revenez a l index pour explorer davantage de pages sur l histoire, la science, la culture, la geographie et la societe en francais.
Explorer l index
Caches spécialisées
Les processeurs pipelinés accèdent à la mémoire à partir de plusieurs points du pipeline : extraction des instructions, traduction d'adresses virtuelles en adresses physiques et extraction des données (voir le pipeline RISC classique ). Naturellement, on utilise des caches physiques différents pour chacun de ces points, afin qu'une même ressource physique ne soit pas affectée à deux points du pipeline. Le pipeline comporte ainsi naturellement au moins trois caches distincts (instructions, TLB et données), chacun spécialisé dans son rôle spécifique.
Cache de victimes
La variante Crystalwell des processeurs Haswell d'Intel intégrait un cache eDRAM de niveau 4 de 128 Mio , servant de cache victime au cache de niveau 3 du processeur. Dans la microarchitecture Skylake, le cache de niveau 4 ne fonctionne plus comme cache victime.
Intel Pentium 4. Un cache de traces est un mécanisme permettant d'augmenter la bande passante de récupération des instructions et de diminuer la consommation d'énergie (dans le cas du Pentium 4) en stockant les traces des instructions qui ont déjà été récupérées et décodées. Un cache de traces stocke les instructions soit après leur décodage, soit au fur et à mesure de leur suppression. Généralement, les instructions sont ajoutées aux caches de traces par groupes représentant soit des blocs de base individuels , soit des traces d'instructions dynamiques. Le cache de traces du Pentium 4 stocke les micro-opérations résultant du décodage des instructions x86, offrant ainsi la fonctionnalité d'un cache de micro-opérations. Grâce à cela, la prochaine fois qu'une instruction sera nécessaire, il ne sera pas nécessaire de la décoder à nouveau en micro-opérations.
Cache de fusion d'écriture (WCC)
Le cache de coalescence d'écriture (WCC ) est un cache spécial faisant partie du cache L2 de la microarchitecture Bulldozer d' AMD . Les données écrites provenant des deux caches L1D du module transitent par le WCC, où elles sont mises en mémoire tampon et fusionnées. Le WCC a pour fonction de réduire le nombre d'écritures dans le cache L2.
les micro-opérations des instructions décodées, telles que reçues directement des décodeurs d'instructions ou du cache d'instructions. Lorsqu'une instruction doit être décodée, le cache μop vérifie si sa forme décodée s'y trouve ; si elle n'est pas disponible, l'instruction est décodée puis mise en cache.L'un des premiers travaux décrivant le cache μop comme une interface alternative pour la famille de processeurs Intel P6 est l'article de 2001 intitulé « Micro-Operation Cache: A Power Aware Frontend for Variable Instruction Length ISA » . Par la suite, Intel a intégré des caches μop dans ses processeurs Sandy Bridge et dans les microarchitectures successives telles qu'Ivy Bridge et Haswell : a implémenté un cache μop dans sa microarchitecture Zen .
L'accès à des instructions complètes pré-décodées élimine la nécessité de décoder à répétition des instructions complexes de longueur variable en micro-opérations plus simples de longueur fixe, et simplifie le processus de prédiction, d'accès, de rotation et d'alignement des instructions récupérées. Un cache de micro-opérations décharge efficacement le matériel d'accès et de décodage, réduisant ainsi la consommation d'énergie et améliorant la fourniture de micro-opérations décodées au processeur. Le cache de micro-opérations améliore également les performances en fournissant de manière plus constante les micro-opérations décodées au processeur et en éliminant divers goulots d'étranglement dans la logique d'accès et de décodage du processeur.
Un cache μop présente de nombreuses similitudes avec un cache de traces, mais il est beaucoup plus simple, ce qui lui confère une meilleure efficacité énergétique ; il est donc mieux adapté aux implémentations sur des appareils alimentés par batterie. Le principal inconvénient du cache de traces, à l’origine de son inefficacité énergétique, réside dans la complexité matérielle requise pour son heuristique de décision concernant la mise en cache et la réutilisation des traces d’instructions créées dynamiquement.
cache d'instructions de la cible de branchement
Un cache de cible de branchement , ou cache d'instructions de cible de branchement (nom utilisé sur les microprocesseurs ARM ) est un cache spécialisé qui stocke les premières instructions à l'adresse de destination d'un branchement. Il est utilisé par les processeurs basse consommation qui n'ont pas besoin d'un cache d'instructions classique, car leur système mémoire est capable de fournir les instructions suffisamment rapidement pour satisfaire le processeur. Cependant, cela ne s'applique qu'aux instructions consécutives ; le redémarrage de la récupération d'une instruction à une nouvelle adresse nécessite toujours plusieurs cycles de latence, ce qui provoque une brève oscillation du pipeline après un transfert de contrôle. Un cache de cible de branchement fournit les instructions pour ces quelques cycles, évitant ainsi un délai après la plupart des branchements.
Cela permet un fonctionnement à pleine vitesse avec un cache beaucoup plus petit qu'un cache d'instructions traditionnel à temps plein.
Cache intelligent
Le cache intelligent est une méthode de mise en cache de niveau 2 ou 3 pour plusieurs cœurs d'exécution, développée par Intel .
Le cache intelligent partage la mémoire cache entre les cœurs d'un processeur multicœur . Comparé à un cache dédié par cœur, le taux global d'échecs de cache diminue lorsque les cœurs n'ont pas besoin de parts égales de l'espace cache. Par conséquent, un seul cœur peut utiliser la totalité du cache de niveau 2 ou 3 tandis que les autres cœurs sont inactifs. De plus, le cache partagé accélère le partage de mémoire entre les différents cœurs d'exécution.
eDRAM et montés sur un module multi-puces , constituant ainsi un quatrième niveau de cache. Dans de rares cas, comme pour le processeur du mainframe IBM z15 (2019), tous les niveaux jusqu'au cache L1 sont implémentés en eDRAM, remplaçant entièrement la SRAM (pour le cache, la SRAM étant toujours utilisée pour les registres ). La gamme de processeurs Apple Silicon , basée sur l'architecture ARM et comprenant les A14 et M1 , dispose d'un cache L1i de 192 Kio pour chacun des cœurs hautes performances, une capacité exceptionnellement élevée ; en revanche, les cœurs basse consommation ne disposent que de 128 Kio. Depuis, d'autres processeurs tels que Lunar Lake d' Intel et Oryon de Qualcomm ont également implémenté des tailles de cache L1i similaires.Les avantages des caches L3 et L4 dépendent des modèles d'accès de l'application. Voici quelques exemples de produits intégrant des caches L3 et L4 :
- Alpha 21164 (1995) disposait d'un cache L3 hors puce de 1 à 64 Mio.
- L'AMD K6-III (1999) disposait d'un cache L3 basé sur la carte mère.
- IBM POWER4 (2001) disposait de caches L3 hors puce de 32 Mio par processeur, partagés entre plusieurs processeurs.
- L'Itanium 2 (2003) disposait d'un cache Itanium 2 (2003) MX 2 incorporait deux processeurs Itanium 2 ainsi qu'un cache L4 partagé de 64 Mio sur un module multi-puces compatible broche à broche avec un processeur Madison.
- Le produit Intel Xeon MP, nom de code « Tulsa » (2006), dispose de 16 Mio de cache L3 intégré partagé entre deux cœurs de processeur.
- AMD Phenom (2007) avec 2 Mio de cache L3.
- L'AMD Phenom II (2008) dispose d'un cache L3 unifié sur puce allant jusqu'à 6 Mio.
- Intel Core i7 (2008) possède un cache L3 unifié sur puce de 8 Mio, inclusif et partagé par tous les cœurs.
- Les processeurs Intel Haswell avec carte graphique intégrée Intel Iris Pro disposent de 128 Mio d'eDRAM faisant essentiellement office de cache L4.
Enfin, à l'autre extrémité de la hiérarchie mémoire, le fichier de registres du processeur peut être considéré comme le cache le plus petit et le plus rapide du système. Sa particularité réside dans le fait qu'il est géré par logiciel, généralement par le compilateur, qui alloue des registres pour stocker les valeurs extraites de la mémoire principale, par exemple pour l'optimisation des boucles imbriquées . Cependant, grâce au renommage des registres , la plupart des affectations de registres du compilateur sont réallouées dynamiquement par le matériel à l'exécution dans un banc de registres, permettant ainsi au processeur de rompre les dépendances de données erronées et d'atténuer les risques liés au pipeline.
Les fichiers de registres présentent parfois une hiérarchie : le Cray-1 (vers 1976) disposait de huit registres d’adresse « A » et de huit registres de données scalaires « S » généralement utilisables. Il comportait également 64 registres d’adresse « B » et 64 registres de données scalaires « T », dont l’accès était plus lent, mais plus rapide que la mémoire principale. Les registres « B » et « T » étaient nécessaires car le Cray-1 ne possédait pas de cache de données. (Le Cray-1 disposait toutefois d’un cache d’instructions.)
multicœur , la question se pose de savoir si les caches doivent être partagés ou locaux à chaque cœur. La mise en œuvre d'un cache partagé engendre inévitablement un câblage plus complexe. En revanche, disposer d'un cache par puce , plutôt que par cœur , réduit considérablement l'espace nécessaire et permet ainsi d'intégrer un cache de plus grande capacité.En règle générale, le partage du cache L1 est déconseillé car l'augmentation de latence qui en résulte ralentirait considérablement chaque cœur par rapport à une puce monocœur. Cependant, pour le cache de plus haut niveau (généralement L3, le dernier appelé avant l'accès à la mémoire), un cache global est souhaitable pour plusieurs raisons : il permet à un seul cœur d'utiliser l'intégralité du cache, réduit la redondance des données en autorisant différents processus ou threads à partager les données mises en cache, et simplifie les protocoles de cohérence de cache utilisés. Par exemple, une puce à huit cœurs avec trois niveaux de cache peut inclure un cache L1 par cœur, un cache L2 intermédiaire pour chaque paire de cœurs et un cache L3 partagé par tous les cœurs.
Un cache de niveau le plus élevé partagé (généralement L3, appelé avant l'accès à la mémoire) est généralement désigné sous le nom de cache de dernier niveau (LLC). Des techniques supplémentaires sont utilisées pour augmenter le niveau de parallélisme lorsque le LLC est partagé entre plusieurs cœurs, notamment en le divisant en plusieurs morceaux qui adressent des plages d'adresses mémoire spécifiques et peuvent être utilisés indépendamment.
Séparés versus unifiés
Dans une structure de cache séparée, les instructions et les données sont mises en cache séparément ; une ligne de cache sert donc soit aux instructions, soit aux données, mais pas aux deux. L’utilisation de tampons de traduction d’instructions et de données distincts présente divers avantages . Dans une structure unifiée, cette contrainte disparaît et les lignes de cache peuvent servir à la fois aux instructions et aux données.
AMD Athlon ) utilisent des caches exclusifs : les données sont garanties de se trouver dans au plus l'un des caches L1 ou L2, jamais dans les deux. D'autres processeurs encore (comme les Intel Pentium II , III et 4 ) n'exigent pas que les données du cache L1 résident également dans le cache L2, bien que cela soit souvent le cas. Il n'existe pas de nom universellement accepté pour cette politique intermédiaire ; deux appellations courantes sont « non exclusif » et « partiellement inclusif ».L’avantage des caches exclusifs réside dans leur capacité de stockage supérieure. Cet avantage est plus marqué lorsque le cache L1 exclusif est comparable au cache L2, et diminue si le cache L2 est beaucoup plus grand que le cache L1. En cas d’échec d’accès dans le cache L1 et de succès dans le cache L2, la ligne correspondante dans le cache L2 est échangée avec une ligne du cache L1. Cet échange est beaucoup plus complexe que la simple copie d’une ligne du cache L2 vers le cache L1, opération effectuée par un cache inclusif.
L'un des avantages des caches strictement inclusifs est que, lorsqu'un périphérique externe ou un autre processeur d'un système multiprocesseur souhaite supprimer une ligne de cache du processeur, il suffit que ce dernier consulte le cache L2. Dans les hiérarchies de caches n'imposant pas l'inclusion, le cache L1 doit également être consulté. En revanche, il existe une corrélation entre les associativités des caches L1 et L2 : si le cache L2 ne possède pas au moins autant de voies que l'ensemble des caches L1, l'associativité effective de ces derniers est limitée. Un autre inconvénient des caches inclusifs est que, lors de toute éviction dans le cache L2, les lignes (potentiellement) correspondantes dans le cache L1 doivent également être évincées afin de maintenir l'inclusivité. Cette opération est conséquente et entraîne un taux d'échecs de cache L1 plus élevé.
Un autre avantage des caches inclusifs est que le cache principal peut utiliser des lignes de cache plus larges, ce qui réduit la taille des étiquettes du cache secondaire. (Les caches exclusifs exigent que les deux caches aient des lignes de cache de même taille, afin que les lignes puissent être permutées en cas d'échec de cache L1 et de succès de cache L2.) Si le cache secondaire est dix fois plus grand que le cache principal, et que les données du cache sont dix fois plus grandes que les étiquettes de cache, la surface d'étiquettes ainsi économisée peut être comparable à la surface incrémentale nécessaire pour stocker les données du cache L1 dans le cache L2.
Mémoire du bloc-notes
La mémoire scratchpad (SPM), également connue sous le nom de mémoire scratchpad, mémoire RAM scratchpad ou mémoire locale dans la terminologie informatique, est une mémoire interne à haute vitesse utilisée pour le stockage temporaire de calculs, de données et d'autres travaux en cours.Exemple : le K8
Pour illustrer à la fois la spécialisation et la mise en cache multiniveau, voici la hiérarchie de cache du cœur K8 du processeur AMD Athlon 64.
Hiérarchie du cache du cœur K8 du processeur AMD Athlon 64 Le K8 possède quatre caches spécialisés : un cache d’instructions, un TLB d’instructions , un TLB de données et un cache de données. Chacun de ces caches est spécialisé :
- Le cache d'instructions conserve des copies de lignes de mémoire de 64 octets et en extrait 16 à chaque cycle. Chaque octet de ce cache est stocké sur dix bits au lieu de huit, les bits supplémentaires marquant les limites des instructions (il s'agit d'un exemple de prédécodage). Le cache utilise uniquement la parité plutôt que la correction d'erreurs (ECC ), car la parité est plus petite et toute donnée corrompue peut être remplacée par des données fraîches extraites de la mémoire (qui contient toujours une copie à jour des instructions).
- Le TLB d'instructions conserve des copies des entrées de table des pages (PTE). À chaque cycle, l'adresse virtuelle de chaque instruction est traduite par ce TLB en une adresse physique. Chaque entrée occupe quatre ou huit octets en mémoire. Le K8 ayant une taille de page variable, chaque TLB est divisé en deux sections : l'une pour les PTE correspondant à des pages de 4 Kio, l'autre pour celles correspondant à des pages de 4 Mio ou 2 Mio. Cette division simplifie le circuit d'association dans chaque section. Le système d'exploitation associe des PTE de tailles différentes aux différentes sections de l'espace d'adressage virtuel.
- Le TLB de données possède deux copies contenant des entrées identiques. Ces deux copies permettent deux accès aux données par cycle pour traduire les adresses virtuelles en adresses physiques. À l'instar du TLB d'instructions, ce TLB est divisé en deux types d'entrées.
- Le cache de données conserve des copies de lignes de mémoire de 64 octets. Il est divisé en 8 banques (chacune stockant 8 Kio de données) et peut accéder à deux ensembles de données de 8 octets par cycle, à condition qu'ils se trouvent dans des banques différentes. Il existe deux copies des étiquettes, car chaque ligne de 64 octets est répartie entre les huit banques. Chaque copie d'étiquette gère l'un des deux accès par cycle.
Le K8 dispose également de caches à plusieurs niveaux. Il existe des TLB d'instructions et de données de second niveau, qui stockent uniquement des entrées de table de pages (PTE) mappant 4 KiB. Les caches d'instructions et de données, ainsi que les différents TLB, peuvent être alimentés par le vaste cache L2 unifié . Ce cache est exclusif aux caches d'instructions et de données L1, ce qui signifie que toute ligne de 8 octets ne peut se trouver que dans l'un des caches suivants : le cache d'instructions L1, le cache de données L1 ou le cache L2. Il est toutefois possible qu'une ligne du cache de données contienne une PTE présente également dans l'un des TLB ; le système d'exploitation assure la cohérence des TLB en vidant certaines portions de ces derniers lors de la mise à jour des tables de pages en mémoire.
Le K8 met également en cache des informations qui ne sont jamais stockées en mémoire : les informations de prédiction. Ces caches ne sont pas représentés sur le schéma ci-dessus. Comme c'est souvent le cas pour ce type de processeur, le K8 dispose d'une prédiction de branchement assez complexe , avec des tables permettant de prédire si des branchements seront effectués et d'autres tables prédisant les cibles des branchements et des sauts. Certaines de ces informations sont associées aux instructions, à la fois dans le cache d'instructions de niveau 1 et dans le cache secondaire unifié.
Le K8 utilise une astuce ingénieuse pour stocker les informations de prédiction avec les instructions dans le cache secondaire. Les lignes de ce cache sont protégées contre toute corruption accidentelle de données (par exemple, suite à l'impact d'une particule alpha ) par un système de correction d'erreurs (ECC) ou par parité , selon qu'elles proviennent du cache principal de données ou d'instructions. Le code de parité occupant moins de bits que le code ECC, les lignes du cache d'instructions disposent de quelques bits supplémentaires. Ces bits servent à stocker les informations de prédiction de branchement associées à ces instructions. Il en résulte un historique de branchement plus étendu pour le prédicteur de branchement, et donc une meilleure précision.
Plus de hiérarchies
D'autres processeurs disposent d'autres types de prédicteurs (par exemple, le prédicteur de contournement de stockage à chargement dans le DEC Alpha 21264 ).
Ces prédicteurs sont des caches, car ils stockent des informations dont le calcul est coûteux. Certains termes employés pour parler des prédicteurs sont les mêmes que ceux utilisés pour les caches (on parle par exemple de « succès » dans un prédicteur de branchement), mais les prédicteurs ne sont généralement pas considérés comme faisant partie de la hiérarchie des caches.
Le K8 assure la cohérence matérielle des caches d'instructions et de données, ce qui signifie qu'une instruction de stockage effectuée juste après une autre modifiera l'instruction suivante. D'autres processeurs, comme ceux des familles Alpha et MIPS, s'appuient sur le logiciel pour maintenir la cohérence du cache d'instructions. L'affichage des instructions de stockage dans le flux d'instructions n'est garanti que lorsqu'un programme appelle une fonction du système d'exploitation pour assurer cette cohérence.
Étiquette RAM
Tag RAM sur la carte d'un Intel Pentium III En génie informatique, une mémoire RAM étiquetée permet de spécifier quelle adresse mémoire est actuellement stockée dans le cache du processeur. Pour une conception simple à correspondance directe, une SRAM rapide peut être utilisée. Les caches associatifs de niveau supérieur utilisent généralement une mémoire adressable par contenu .
Mise en œuvre
Chemin de lecture pour un cache associatif à deux voies Le schéma ci-contre vise à clarifier l'utilisation des différents champs de l'adresse. Le bit 31 est le plus significatif, le bit 0 le moins significatif. Ce schéma représente les SRAM, l'indexation et le multiplexage d'un cache de 4 Kio, associatif par ensembles à deux voies, indexé et étiqueté virtuellement, avec des lignes de 64 octets (B), une largeur de lecture de 32 bits et une adresse virtuelle de 32 bits.
Le cache ayant une capacité de 4 KiB et comportant 64 lignes d'octets, il ne contient que 64 lignes. La lecture s'effectue par paires à partir d'une SRAM d'étiquettes de 32 lignes, chacune associée à une paire d'étiquettes de 21 bits. Bien que toute fonction des bits d'adresse virtuelle 31 à 6 puisse être utilisée pour indexer les SRAM d'étiquettes et de données, l'utilisation des bits de poids faible est plus simple.
De même, étant donné que le cache fait 4 KiB et possède un chemin de lecture de 4 B, et qu'il lit de deux manières pour chaque accès, la SRAM de données comporte 512 lignes de 8 octets de large.
Un cache plus moderne pourrait avoir une capacité de 16 Kio, être associatif par ensembles à 4 voies, indexé virtuellement, avec des indications virtuelles et un marquage physique, avec des lignes de 32 octets, une largeur de lecture de 32 bits et des adresses physiques de 36 bits. Le chemin de lecture pour un tel cache est très similaire à celui décrit précédemment. Au lieu d'étiquettes, ce sont des indications virtuelles qui sont lues et comparées à un sous-ensemble de l'adresse virtuelle. Plus tard dans le pipeline, l'adresse virtuelle est traduite en adresse physique par le TLB, et l'étiquette physique correspondante est lue (une seule, car l'indication virtuelle indique le sens de lecture dans le cache). Enfin, l'adresse physique est comparée à l'étiquette physique pour déterminer si une correspondance a été trouvée.
Certaines conceptions SPARC ont amélioré la vitesse de leurs caches L1 de quelques délais de porte en intégrant l'additionneur d'adresses virtuelles dans les décodeurs SRAM.aux registres . Mais depuis les années 1980 l'écart de performance entre le processeur et la mémoire n'a cessé de se creuser. Les microprocesseurs ont progressé beaucoup plus vite que la mémoire, notamment en termes de fréquence de fonctionnement , faisant de cette dernière un goulot d'étranglement. S'il était techniquement possible d'avoir une mémoire principale aussi rapide que le processeur, une solution plus économique a été privilégiée : utiliser une grande quantité de mémoire basse vitesse, tout en intégrant une petite mémoire cache haute vitesse pour compenser l'écart de performance. Cette approche a permis d'obtenir une capacité dix fois supérieure – pour un coût identique – avec une légère diminution des performances globales.
Premières implémentations TLB
Les premières utilisations documentées d'un TLB ont eu lieu sur le GE 645 et l' IBM 360/67 , qui utilisaient tous deux une mémoire associative comme TLB.
Cache de première instruction
La première utilisation documentée d'un cache d'instructions a eu lieu sur le CDC 6600.
Premier cache de données
La première utilisation documentée d'un cache de données a eu lieu sur le système IBM System/360 modèle 85.
Dans les microprocesseurs 68k
Le 68010 , sorti en 1982, dispose d'un « mode boucle » pouvant être considéré comme un cache d'instructions réduit et spécifique, accélérant les boucles composées de seulement deux instructions. Le 68020 , sorti en 1984, a remplacé ce mode par un cache d'instructions classique de 256 octets, devenant ainsi le premier processeur de la série 68k à intégrer une véritable mémoire cache sur puce.
Le 68030 , sorti en 1987, est essentiellement un cœur 68020 avec un cache de données supplémentaire de 256 octets, une unité de gestion de la mémoire sur puce (MMU), une réduction de processus et un mode rafale ajouté pour les caches.
Le 68040 , sorti en 1990, possède des caches d'instructions et de données séparés de quatre kilo-octets chacun.
Le 68060 , sorti en 1994, possède les éléments suivants : cache de données de 8 KiB (associatif à quatre voies), cache d'instructions de 8 KiB (associatif à quatre voies), tampon d'instructions FIFO de 96 octets, cache de branchement de 256 entrées et tampon MMU de cache de traduction d'adresses de 64 entrées (associatif à quatre voies).
Dans les microprocesseurs x86
Exemple de carte mère avec un microprocesseur i386 (33 MHz), 64 KiB de cache (25 ns ; 8 puces dans le coin inférieur gauche), 2 Mio de DRAM (70 ns ; 8 SIMM à droite du cache) et un contrôleur de cache ( Austek A38202 ; à droite du processeur). Avec l'arrivée des microprocesseurs x86 à des fréquences d'horloge de 20 MHz et plus (notamment l' A386) , de petites quantités de mémoire cache rapide ont commencé à être intégrées aux systèmes pour améliorer leurs performances. En effet, la DRAM utilisée comme mémoire principale présentait une latence importante, pouvant atteindre 120 ns, ainsi que des cycles de rafraîchissement. Le cache était constitué de cellules de mémoire SRAM , plus coûteuses mais nettement plus rapides, dont la latence était alors de l'ordre de 10 à 25 ns. Les premiers caches étaient externes au processeur et généralement situés sur la carte mère sous la forme de huit ou neuf composants DIP insérés dans des supports, permettant ainsi d'ajouter le cache en option ou de l'étendre.
Certaines versions du processeur Intel 386 pouvaient prendre en charge de 16 à 256 KiB de cache externe.
Avec le processeur 486 , un cache de 8 Kio était intégré directement à la puce. Ce cache était appelé cache de niveau 1 (L1) pour le différencier du cache de niveau 2 (L2), plus lent et situé sur la carte mère. Ces derniers étaient beaucoup plus volumineux, la taille la plus courante étant de 256 Kio. Certaines cartes mères disposaient d'emplacements pour la carte fille Intel 485Turbocache , dotée de 64 ou 128 Ko de mémoire cache. La popularité du cache sur carte mère s'est maintenue durant l' ère Pentium MMX , mais a été rendue obsolète par l'introduction de la SDRAM et l'écart croissant entre les fréquences d'horloge du bus et du processeur, ce qui a fait que le cache sur carte mère n'était plus que légèrement plus rapide que la mémoire principale.
L'évolution suivante en matière d'implémentation de cache dans les microprocesseurs x86 a commencé avec le Pentium Pro , qui a intégré le cache secondaire dans le même boîtier que le microprocesseur, cadencé à la même fréquence que ce dernier.
Les caches intégrés à la carte mère ont longtemps bénéficié d'une grande popularité grâce aux processeurs AMD K6-2 et AMD K6-III , qui utilisaient encore le socket 7 , précédemment employé par Intel avec des caches intégrés. Le K6-III intégrait 256 Kio de cache L2 et exploitait le cache intégré comme cache de troisième niveau, appelé L3 (des cartes mères avec jusqu'à 2 Mio de cache intégré ont été produites). Après l'obsolescence du socket 7, le cache intégré à la carte mère a disparu des systèmes x86.
Les caches à trois niveaux ont été réutilisés pour la première fois avec l'introduction du processeur Intel Xeon MP « Foster Core » , où le cache L3 a été ajouté à la puce du processeur. Il est devenu courant que la taille totale du cache augmente avec les nouvelles générations de processeurs, et récemment (en 2011), il n'est pas rare de trouver des caches de niveau 3 de plusieurs dizaines de mégaoctets
Intel a introduit un cache de niveau 4 intégré avec la microarchitecture Haswell . Les processeurs Crystalwell Haswell, équipés de la variante GT3e du processeur graphique intégré Intel Iris Pro, disposent de 128 Mio de mémoire DRAM embarquée ( eDRAM ) sur le même boîtier. Ce cache L4 est partagé dynamiquement entre le GPU et le CPU intégrés, et sert de cache victime au cache L3 du CPU.
Dans les microprocesseurs ARM
Le processeur Apple M1 dispose de 128 ou 192 Kio de cache d'instructions L1 par cœur (important pour la latence et les performances monocœur), selon le type de cœur. Il s'agit d'un cache L1 exceptionnellement important pour un processeur (et pas seulement pour un ordinateur portable). La taille totale de la mémoire cache n'est pas particulièrement élevée pour un ordinateur portable (c'est le total qui importe le plus pour le débit), et des tailles totales bien supérieures (par exemple, L3 ou L4) sont disponibles sur les ordinateurs centraux IBM.
Recherches actuelles
Les premières conceptions de cache se concentraient exclusivement sur le coût direct du cache et de la RAM , ainsi que sur la vitesse d'exécution moyenne. Les conceptions de cache plus récentes prennent également en compte l'efficacité énergétique , la tolérance aux pannes et d'autres objectifs.
Plusieurs outils sont à la disposition des architectes informatiques pour les aider à explorer les compromis entre le temps de cycle du cache, l'énergie et la surface ; le simulateur de cache CACTI et le simulateur de jeu d'instructions SimpleScalar sont deux options open-source.
Cache multiport
Un cache multiport est un cache capable de traiter plusieurs requêtes simultanément. Alors qu'un cache traditionnel utilise généralement une seule adresse mémoire, un cache multiport peut permettre de demander N adresses à la fois, N étant le nombre de ports connectés entre le processeur et le cache. L'avantage est qu'un processeur pipeliné peut accéder à la mémoire depuis différentes phases de son pipeline. Autre avantage : il rend possible le concept de processeurs superscalaires grâce à différents niveaux de cache.
Plus d articles de Worldlex Wiki
Revenez a l index pour explorer davantage de pages sur l histoire, la science, la culture, la geographie et la societe en francais.
Explorer l index
Cache de fusion d'écriture (WCC)
Le cache de coalescence d'écriture (WCC ) est un cache spécial faisant partie du cache L2 de la microarchitecture Bulldozer d' AMD . Les données écrites provenant des deux caches L1D du module transitent par le WCC, où elles sont mises en mémoire tampon et fusionnées. Le WCC a pour fonction de réduire le nombre d'écritures dans le cache L2.
les micro-opérations des instructions décodées, telles que reçues directement des décodeurs d'instructions ou du cache d'instructions. Lorsqu'une instruction doit être décodée, le cache μop vérifie si sa forme décodée s'y trouve ; si elle n'est pas disponible, l'instruction est décodée puis mise en cache.L'un des premiers travaux décrivant le cache μop comme une interface alternative pour la famille de processeurs Intel P6 est l'article de 2001 intitulé « Micro-Operation Cache: A Power Aware Frontend for Variable Instruction Length ISA » . Par la suite, Intel a intégré des caches μop dans ses processeurs Sandy Bridge et dans les microarchitectures successives telles qu'Ivy Bridge et Haswell : a implémenté un cache μop dans sa microarchitecture Zen .
L'accès à des instructions complètes pré-décodées élimine la nécessité de décoder à répétition des instructions complexes de longueur variable en micro-opérations plus simples de longueur fixe, et simplifie le processus de prédiction, d'accès, de rotation et d'alignement des instructions récupérées. Un cache de micro-opérations décharge efficacement le matériel d'accès et de décodage, réduisant ainsi la consommation d'énergie et améliorant la fourniture de micro-opérations décodées au processeur. Le cache de micro-opérations améliore également les performances en fournissant de manière plus constante les micro-opérations décodées au processeur et en éliminant divers goulots d'étranglement dans la logique d'accès et de décodage du processeur.
Un cache μop présente de nombreuses similitudes avec un cache de traces, mais il est beaucoup plus simple, ce qui lui confère une meilleure efficacité énergétique ; il est donc mieux adapté aux implémentations sur des appareils alimentés par batterie. Le principal inconvénient du cache de traces, à l’origine de son inefficacité énergétique, réside dans la complexité matérielle requise pour son heuristique de décision concernant la mise en cache et la réutilisation des traces d’instructions créées dynamiquement.
cache d'instructions de la cible de branchement
Un cache de cible de branchement , ou cache d'instructions de cible de branchement (nom utilisé sur les microprocesseurs ARM ) est un cache spécialisé qui stocke les premières instructions à l'adresse de destination d'un branchement. Il est utilisé par les processeurs basse consommation qui n'ont pas besoin d'un cache d'instructions classique, car leur système mémoire est capable de fournir les instructions suffisamment rapidement pour satisfaire le processeur. Cependant, cela ne s'applique qu'aux instructions consécutives ; le redémarrage de la récupération d'une instruction à une nouvelle adresse nécessite toujours plusieurs cycles de latence, ce qui provoque une brève oscillation du pipeline après un transfert de contrôle. Un cache de cible de branchement fournit les instructions pour ces quelques cycles, évitant ainsi un délai après la plupart des branchements.
Cela permet un fonctionnement à pleine vitesse avec un cache beaucoup plus petit qu'un cache d'instructions traditionnel à temps plein.
Cache intelligent
Le cache intelligent est une méthode de mise en cache de niveau 2 ou 3 pour plusieurs cœurs d'exécution, développée par Intel .
Le cache intelligent partage la mémoire cache entre les cœurs d'un processeur multicœur . Comparé à un cache dédié par cœur, le taux global d'échecs de cache diminue lorsque les cœurs n'ont pas besoin de parts égales de l'espace cache. Par conséquent, un seul cœur peut utiliser la totalité du cache de niveau 2 ou 3 tandis que les autres cœurs sont inactifs. De plus, le cache partagé accélère le partage de mémoire entre les différents cœurs d'exécution.
eDRAM et montés sur un module multi-puces , constituant ainsi un quatrième niveau de cache. Dans de rares cas, comme pour le processeur du mainframe IBM z15 (2019), tous les niveaux jusqu'au cache L1 sont implémentés en eDRAM, remplaçant entièrement la SRAM (pour le cache, la SRAM étant toujours utilisée pour les registres ). La gamme de processeurs Apple Silicon , basée sur l'architecture ARM et comprenant les A14 et M1 , dispose d'un cache L1i de 192 Kio pour chacun des cœurs hautes performances, une capacité exceptionnellement élevée ; en revanche, les cœurs basse consommation ne disposent que de 128 Kio. Depuis, d'autres processeurs tels que Lunar Lake d' Intel et Oryon de Qualcomm ont également implémenté des tailles de cache L1i similaires.Les avantages des caches L3 et L4 dépendent des modèles d'accès de l'application. Voici quelques exemples de produits intégrant des caches L3 et L4 :
- Alpha 21164 (1995) disposait d'un cache L3 hors puce de 1 à 64 Mio.
- L'AMD K6-III (1999) disposait d'un cache L3 basé sur la carte mère.
- IBM POWER4 (2001) disposait de caches L3 hors puce de 32 Mio par processeur, partagés entre plusieurs processeurs.
- L'Itanium 2 (2003) disposait d'un cache Itanium 2 (2003) MX 2 incorporait deux processeurs Itanium 2 ainsi qu'un cache L4 partagé de 64 Mio sur un module multi-puces compatible broche à broche avec un processeur Madison.
- Le produit Intel Xeon MP, nom de code « Tulsa » (2006), dispose de 16 Mio de cache L3 intégré partagé entre deux cœurs de processeur.
- AMD Phenom (2007) avec 2 Mio de cache L3.
- L'AMD Phenom II (2008) dispose d'un cache L3 unifié sur puce allant jusqu'à 6 Mio.
- Intel Core i7 (2008) possède un cache L3 unifié sur puce de 8 Mio, inclusif et partagé par tous les cœurs.
- Les processeurs Intel Haswell avec carte graphique intégrée Intel Iris Pro disposent de 128 Mio d'eDRAM faisant essentiellement office de cache L4.
Enfin, à l'autre extrémité de la hiérarchie mémoire, le fichier de registres du processeur peut être considéré comme le cache le plus petit et le plus rapide du système. Sa particularité réside dans le fait qu'il est géré par logiciel, généralement par le compilateur, qui alloue des registres pour stocker les valeurs extraites de la mémoire principale, par exemple pour l'optimisation des boucles imbriquées . Cependant, grâce au renommage des registres , la plupart des affectations de registres du compilateur sont réallouées dynamiquement par le matériel à l'exécution dans un banc de registres, permettant ainsi au processeur de rompre les dépendances de données erronées et d'atténuer les risques liés au pipeline.
Les fichiers de registres présentent parfois une hiérarchie : le Cray-1 (vers 1976) disposait de huit registres d’adresse « A » et de huit registres de données scalaires « S » généralement utilisables. Il comportait également 64 registres d’adresse « B » et 64 registres de données scalaires « T », dont l’accès était plus lent, mais plus rapide que la mémoire principale. Les registres « B » et « T » étaient nécessaires car le Cray-1 ne possédait pas de cache de données. (Le Cray-1 disposait toutefois d’un cache d’instructions.)
multicœur , la question se pose de savoir si les caches doivent être partagés ou locaux à chaque cœur. La mise en œuvre d'un cache partagé engendre inévitablement un câblage plus complexe. En revanche, disposer d'un cache par puce , plutôt que par cœur , réduit considérablement l'espace nécessaire et permet ainsi d'intégrer un cache de plus grande capacité.En règle générale, le partage du cache L1 est déconseillé car l'augmentation de latence qui en résulte ralentirait considérablement chaque cœur par rapport à une puce monocœur. Cependant, pour le cache de plus haut niveau (généralement L3, le dernier appelé avant l'accès à la mémoire), un cache global est souhaitable pour plusieurs raisons : il permet à un seul cœur d'utiliser l'intégralité du cache, réduit la redondance des données en autorisant différents processus ou threads à partager les données mises en cache, et simplifie les protocoles de cohérence de cache utilisés. Par exemple, une puce à huit cœurs avec trois niveaux de cache peut inclure un cache L1 par cœur, un cache L2 intermédiaire pour chaque paire de cœurs et un cache L3 partagé par tous les cœurs.
Un cache de niveau le plus élevé partagé (généralement L3, appelé avant l'accès à la mémoire) est généralement désigné sous le nom de cache de dernier niveau (LLC). Des techniques supplémentaires sont utilisées pour augmenter le niveau de parallélisme lorsque le LLC est partagé entre plusieurs cœurs, notamment en le divisant en plusieurs morceaux qui adressent des plages d'adresses mémoire spécifiques et peuvent être utilisés indépendamment.
Séparés versus unifiés
Dans une structure de cache séparée, les instructions et les données sont mises en cache séparément ; une ligne de cache sert donc soit aux instructions, soit aux données, mais pas aux deux. L’utilisation de tampons de traduction d’instructions et de données distincts présente divers avantages . Dans une structure unifiée, cette contrainte disparaît et les lignes de cache peuvent servir à la fois aux instructions et aux données.
AMD Athlon ) utilisent des caches exclusifs : les données sont garanties de se trouver dans au plus l'un des caches L1 ou L2, jamais dans les deux. D'autres processeurs encore (comme les Intel Pentium II , III et 4 ) n'exigent pas que les données du cache L1 résident également dans le cache L2, bien que cela soit souvent le cas. Il n'existe pas de nom universellement accepté pour cette politique intermédiaire ; deux appellations courantes sont « non exclusif » et « partiellement inclusif ».L’avantage des caches exclusifs réside dans leur capacité de stockage supérieure. Cet avantage est plus marqué lorsque le cache L1 exclusif est comparable au cache L2, et diminue si le cache L2 est beaucoup plus grand que le cache L1. En cas d’échec d’accès dans le cache L1 et de succès dans le cache L2, la ligne correspondante dans le cache L2 est échangée avec une ligne du cache L1. Cet échange est beaucoup plus complexe que la simple copie d’une ligne du cache L2 vers le cache L1, opération effectuée par un cache inclusif.
L'un des avantages des caches strictement inclusifs est que, lorsqu'un périphérique externe ou un autre processeur d'un système multiprocesseur souhaite supprimer une ligne de cache du processeur, il suffit que ce dernier consulte le cache L2. Dans les hiérarchies de caches n'imposant pas l'inclusion, le cache L1 doit également être consulté. En revanche, il existe une corrélation entre les associativités des caches L1 et L2 : si le cache L2 ne possède pas au moins autant de voies que l'ensemble des caches L1, l'associativité effective de ces derniers est limitée. Un autre inconvénient des caches inclusifs est que, lors de toute éviction dans le cache L2, les lignes (potentiellement) correspondantes dans le cache L1 doivent également être évincées afin de maintenir l'inclusivité. Cette opération est conséquente et entraîne un taux d'échecs de cache L1 plus élevé.
Un autre avantage des caches inclusifs est que le cache principal peut utiliser des lignes de cache plus larges, ce qui réduit la taille des étiquettes du cache secondaire. (Les caches exclusifs exigent que les deux caches aient des lignes de cache de même taille, afin que les lignes puissent être permutées en cas d'échec de cache L1 et de succès de cache L2.) Si le cache secondaire est dix fois plus grand que le cache principal, et que les données du cache sont dix fois plus grandes que les étiquettes de cache, la surface d'étiquettes ainsi économisée peut être comparable à la surface incrémentale nécessaire pour stocker les données du cache L1 dans le cache L2.
Mémoire du bloc-notes
La mémoire scratchpad (SPM), également connue sous le nom de mémoire scratchpad, mémoire RAM scratchpad ou mémoire locale dans la terminologie informatique, est une mémoire interne à haute vitesse utilisée pour le stockage temporaire de calculs, de données et d'autres travaux en cours.Exemple : le K8
Pour illustrer à la fois la spécialisation et la mise en cache multiniveau, voici la hiérarchie de cache du cœur K8 du processeur AMD Athlon 64.
Hiérarchie du cache du cœur K8 du processeur AMD Athlon 64 Le K8 possède quatre caches spécialisés : un cache d’instructions, un TLB d’instructions , un TLB de données et un cache de données. Chacun de ces caches est spécialisé :
- Le cache d'instructions conserve des copies de lignes de mémoire de 64 octets et en extrait 16 à chaque cycle. Chaque octet de ce cache est stocké sur dix bits au lieu de huit, les bits supplémentaires marquant les limites des instructions (il s'agit d'un exemple de prédécodage). Le cache utilise uniquement la parité plutôt que la correction d'erreurs (ECC ), car la parité est plus petite et toute donnée corrompue peut être remplacée par des données fraîches extraites de la mémoire (qui contient toujours une copie à jour des instructions).
- Le TLB d'instructions conserve des copies des entrées de table des pages (PTE). À chaque cycle, l'adresse virtuelle de chaque instruction est traduite par ce TLB en une adresse physique. Chaque entrée occupe quatre ou huit octets en mémoire. Le K8 ayant une taille de page variable, chaque TLB est divisé en deux sections : l'une pour les PTE correspondant à des pages de 4 Kio, l'autre pour celles correspondant à des pages de 4 Mio ou 2 Mio. Cette division simplifie le circuit d'association dans chaque section. Le système d'exploitation associe des PTE de tailles différentes aux différentes sections de l'espace d'adressage virtuel.
- Le TLB de données possède deux copies contenant des entrées identiques. Ces deux copies permettent deux accès aux données par cycle pour traduire les adresses virtuelles en adresses physiques. À l'instar du TLB d'instructions, ce TLB est divisé en deux types d'entrées.
- Le cache de données conserve des copies de lignes de mémoire de 64 octets. Il est divisé en 8 banques (chacune stockant 8 Kio de données) et peut accéder à deux ensembles de données de 8 octets par cycle, à condition qu'ils se trouvent dans des banques différentes. Il existe deux copies des étiquettes, car chaque ligne de 64 octets est répartie entre les huit banques. Chaque copie d'étiquette gère l'un des deux accès par cycle.
Le K8 dispose également de caches à plusieurs niveaux. Il existe des TLB d'instructions et de données de second niveau, qui stockent uniquement des entrées de table de pages (PTE) mappant 4 KiB. Les caches d'instructions et de données, ainsi que les différents TLB, peuvent être alimentés par le vaste cache L2 unifié . Ce cache est exclusif aux caches d'instructions et de données L1, ce qui signifie que toute ligne de 8 octets ne peut se trouver que dans l'un des caches suivants : le cache d'instructions L1, le cache de données L1 ou le cache L2. Il est toutefois possible qu'une ligne du cache de données contienne une PTE présente également dans l'un des TLB ; le système d'exploitation assure la cohérence des TLB en vidant certaines portions de ces derniers lors de la mise à jour des tables de pages en mémoire.
Le K8 met également en cache des informations qui ne sont jamais stockées en mémoire : les informations de prédiction. Ces caches ne sont pas représentés sur le schéma ci-dessus. Comme c'est souvent le cas pour ce type de processeur, le K8 dispose d'une prédiction de branchement assez complexe , avec des tables permettant de prédire si des branchements seront effectués et d'autres tables prédisant les cibles des branchements et des sauts. Certaines de ces informations sont associées aux instructions, à la fois dans le cache d'instructions de niveau 1 et dans le cache secondaire unifié.
Le K8 utilise une astuce ingénieuse pour stocker les informations de prédiction avec les instructions dans le cache secondaire. Les lignes de ce cache sont protégées contre toute corruption accidentelle de données (par exemple, suite à l'impact d'une particule alpha ) par un système de correction d'erreurs (ECC) ou par parité , selon qu'elles proviennent du cache principal de données ou d'instructions. Le code de parité occupant moins de bits que le code ECC, les lignes du cache d'instructions disposent de quelques bits supplémentaires. Ces bits servent à stocker les informations de prédiction de branchement associées à ces instructions. Il en résulte un historique de branchement plus étendu pour le prédicteur de branchement, et donc une meilleure précision.
Plus de hiérarchies
D'autres processeurs disposent d'autres types de prédicteurs (par exemple, le prédicteur de contournement de stockage à chargement dans le DEC Alpha 21264 ).
Ces prédicteurs sont des caches, car ils stockent des informations dont le calcul est coûteux. Certains termes employés pour parler des prédicteurs sont les mêmes que ceux utilisés pour les caches (on parle par exemple de « succès » dans un prédicteur de branchement), mais les prédicteurs ne sont généralement pas considérés comme faisant partie de la hiérarchie des caches.
Le K8 assure la cohérence matérielle des caches d'instructions et de données, ce qui signifie qu'une instruction de stockage effectuée juste après une autre modifiera l'instruction suivante. D'autres processeurs, comme ceux des familles Alpha et MIPS, s'appuient sur le logiciel pour maintenir la cohérence du cache d'instructions. L'affichage des instructions de stockage dans le flux d'instructions n'est garanti que lorsqu'un programme appelle une fonction du système d'exploitation pour assurer cette cohérence.
Étiquette RAM
Tag RAM sur la carte d'un Intel Pentium III En génie informatique, une mémoire RAM étiquetée permet de spécifier quelle adresse mémoire est actuellement stockée dans le cache du processeur. Pour une conception simple à correspondance directe, une SRAM rapide peut être utilisée. Les caches associatifs de niveau supérieur utilisent généralement une mémoire adressable par contenu .
Mise en œuvre
Chemin de lecture pour un cache associatif à deux voies Le schéma ci-contre vise à clarifier l'utilisation des différents champs de l'adresse. Le bit 31 est le plus significatif, le bit 0 le moins significatif. Ce schéma représente les SRAM, l'indexation et le multiplexage d'un cache de 4 Kio, associatif par ensembles à deux voies, indexé et étiqueté virtuellement, avec des lignes de 64 octets (B), une largeur de lecture de 32 bits et une adresse virtuelle de 32 bits.
Le cache ayant une capacité de 4 KiB et comportant 64 lignes d'octets, il ne contient que 64 lignes. La lecture s'effectue par paires à partir d'une SRAM d'étiquettes de 32 lignes, chacune associée à une paire d'étiquettes de 21 bits. Bien que toute fonction des bits d'adresse virtuelle 31 à 6 puisse être utilisée pour indexer les SRAM d'étiquettes et de données, l'utilisation des bits de poids faible est plus simple.
De même, étant donné que le cache fait 4 KiB et possède un chemin de lecture de 4 B, et qu'il lit de deux manières pour chaque accès, la SRAM de données comporte 512 lignes de 8 octets de large.
Un cache plus moderne pourrait avoir une capacité de 16 Kio, être associatif par ensembles à 4 voies, indexé virtuellement, avec des indications virtuelles et un marquage physique, avec des lignes de 32 octets, une largeur de lecture de 32 bits et des adresses physiques de 36 bits. Le chemin de lecture pour un tel cache est très similaire à celui décrit précédemment. Au lieu d'étiquettes, ce sont des indications virtuelles qui sont lues et comparées à un sous-ensemble de l'adresse virtuelle. Plus tard dans le pipeline, l'adresse virtuelle est traduite en adresse physique par le TLB, et l'étiquette physique correspondante est lue (une seule, car l'indication virtuelle indique le sens de lecture dans le cache). Enfin, l'adresse physique est comparée à l'étiquette physique pour déterminer si une correspondance a été trouvée.
Certaines conceptions SPARC ont amélioré la vitesse de leurs caches L1 de quelques délais de porte en intégrant l'additionneur d'adresses virtuelles dans les décodeurs SRAM.aux registres . Mais depuis les années 1980 l'écart de performance entre le processeur et la mémoire n'a cessé de se creuser. Les microprocesseurs ont progressé beaucoup plus vite que la mémoire, notamment en termes de fréquence de fonctionnement , faisant de cette dernière un goulot d'étranglement. S'il était techniquement possible d'avoir une mémoire principale aussi rapide que le processeur, une solution plus économique a été privilégiée : utiliser une grande quantité de mémoire basse vitesse, tout en intégrant une petite mémoire cache haute vitesse pour compenser l'écart de performance. Cette approche a permis d'obtenir une capacité dix fois supérieure – pour un coût identique – avec une légère diminution des performances globales.
Premières implémentations TLB
Les premières utilisations documentées d'un TLB ont eu lieu sur le GE 645 et l' IBM 360/67 , qui utilisaient tous deux une mémoire associative comme TLB.
Cache de première instruction
La première utilisation documentée d'un cache d'instructions a eu lieu sur le CDC 6600.
Premier cache de données
La première utilisation documentée d'un cache de données a eu lieu sur le système IBM System/360 modèle 85.
Dans les microprocesseurs 68k
Le 68010 , sorti en 1982, dispose d'un « mode boucle » pouvant être considéré comme un cache d'instructions réduit et spécifique, accélérant les boucles composées de seulement deux instructions. Le 68020 , sorti en 1984, a remplacé ce mode par un cache d'instructions classique de 256 octets, devenant ainsi le premier processeur de la série 68k à intégrer une véritable mémoire cache sur puce.
Le 68030 , sorti en 1987, est essentiellement un cœur 68020 avec un cache de données supplémentaire de 256 octets, une unité de gestion de la mémoire sur puce (MMU), une réduction de processus et un mode rafale ajouté pour les caches.
Le 68040 , sorti en 1990, possède des caches d'instructions et de données séparés de quatre kilo-octets chacun.
Le 68060 , sorti en 1994, possède les éléments suivants : cache de données de 8 KiB (associatif à quatre voies), cache d'instructions de 8 KiB (associatif à quatre voies), tampon d'instructions FIFO de 96 octets, cache de branchement de 256 entrées et tampon MMU de cache de traduction d'adresses de 64 entrées (associatif à quatre voies).
Dans les microprocesseurs x86
Exemple de carte mère avec un microprocesseur i386 (33 MHz), 64 KiB de cache (25 ns ; 8 puces dans le coin inférieur gauche), 2 Mio de DRAM (70 ns ; 8 SIMM à droite du cache) et un contrôleur de cache ( Austek A38202 ; à droite du processeur). Avec l'arrivée des microprocesseurs x86 à des fréquences d'horloge de 20 MHz et plus (notamment l' A386) , de petites quantités de mémoire cache rapide ont commencé à être intégrées aux systèmes pour améliorer leurs performances. En effet, la DRAM utilisée comme mémoire principale présentait une latence importante, pouvant atteindre 120 ns, ainsi que des cycles de rafraîchissement. Le cache était constitué de cellules de mémoire SRAM , plus coûteuses mais nettement plus rapides, dont la latence était alors de l'ordre de 10 à 25 ns. Les premiers caches étaient externes au processeur et généralement situés sur la carte mère sous la forme de huit ou neuf composants DIP insérés dans des supports, permettant ainsi d'ajouter le cache en option ou de l'étendre.
Certaines versions du processeur Intel 386 pouvaient prendre en charge de 16 à 256 KiB de cache externe.
Avec le processeur 486 , un cache de 8 Kio était intégré directement à la puce. Ce cache était appelé cache de niveau 1 (L1) pour le différencier du cache de niveau 2 (L2), plus lent et situé sur la carte mère. Ces derniers étaient beaucoup plus volumineux, la taille la plus courante étant de 256 Kio. Certaines cartes mères disposaient d'emplacements pour la carte fille Intel 485Turbocache , dotée de 64 ou 128 Ko de mémoire cache. La popularité du cache sur carte mère s'est maintenue durant l' ère Pentium MMX , mais a été rendue obsolète par l'introduction de la SDRAM et l'écart croissant entre les fréquences d'horloge du bus et du processeur, ce qui a fait que le cache sur carte mère n'était plus que légèrement plus rapide que la mémoire principale.
L'évolution suivante en matière d'implémentation de cache dans les microprocesseurs x86 a commencé avec le Pentium Pro , qui a intégré le cache secondaire dans le même boîtier que le microprocesseur, cadencé à la même fréquence que ce dernier.
Les caches intégrés à la carte mère ont longtemps bénéficié d'une grande popularité grâce aux processeurs AMD K6-2 et AMD K6-III , qui utilisaient encore le socket 7 , précédemment employé par Intel avec des caches intégrés. Le K6-III intégrait 256 Kio de cache L2 et exploitait le cache intégré comme cache de troisième niveau, appelé L3 (des cartes mères avec jusqu'à 2 Mio de cache intégré ont été produites). Après l'obsolescence du socket 7, le cache intégré à la carte mère a disparu des systèmes x86.
Les caches à trois niveaux ont été réutilisés pour la première fois avec l'introduction du processeur Intel Xeon MP « Foster Core » , où le cache L3 a été ajouté à la puce du processeur. Il est devenu courant que la taille totale du cache augmente avec les nouvelles générations de processeurs, et récemment (en 2011), il n'est pas rare de trouver des caches de niveau 3 de plusieurs dizaines de mégaoctets
Intel a introduit un cache de niveau 4 intégré avec la microarchitecture Haswell . Les processeurs Crystalwell Haswell, équipés de la variante GT3e du processeur graphique intégré Intel Iris Pro, disposent de 128 Mio de mémoire DRAM embarquée ( eDRAM ) sur le même boîtier. Ce cache L4 est partagé dynamiquement entre le GPU et le CPU intégrés, et sert de cache victime au cache L3 du CPU.
Dans les microprocesseurs ARM
Le processeur Apple M1 dispose de 128 ou 192 Kio de cache d'instructions L1 par cœur (important pour la latence et les performances monocœur), selon le type de cœur. Il s'agit d'un cache L1 exceptionnellement important pour un processeur (et pas seulement pour un ordinateur portable). La taille totale de la mémoire cache n'est pas particulièrement élevée pour un ordinateur portable (c'est le total qui importe le plus pour le débit), et des tailles totales bien supérieures (par exemple, L3 ou L4) sont disponibles sur les ordinateurs centraux IBM.
Recherches actuelles
Les premières conceptions de cache se concentraient exclusivement sur le coût direct du cache et de la RAM , ainsi que sur la vitesse d'exécution moyenne. Les conceptions de cache plus récentes prennent également en compte l'efficacité énergétique , la tolérance aux pannes et d'autres objectifs.
Plusieurs outils sont à la disposition des architectes informatiques pour les aider à explorer les compromis entre le temps de cycle du cache, l'énergie et la surface ; le simulateur de cache CACTI et le simulateur de jeu d'instructions SimpleScalar sont deux options open-source.
Cache multiport
Un cache multiport est un cache capable de traiter plusieurs requêtes simultanément. Alors qu'un cache traditionnel utilise généralement une seule adresse mémoire, un cache multiport peut permettre de demander N adresses à la fois, N étant le nombre de ports connectés entre le processeur et le cache. L'avantage est qu'un processeur pipeliné peut accéder à la mémoire depuis différentes phases de son pipeline. Autre avantage : il rend possible le concept de processeurs superscalaires grâce à différents niveaux de cache.
Plus d articles de Worldlex Wiki
Revenez a l index pour explorer davantage de pages sur l histoire, la science, la culture, la geographie et la societe en francais.
Explorer l index
cache d'instructions de la cible de branchement
Un cache de cible de branchement , ou cache d'instructions de cible de branchement (nom utilisé sur les microprocesseurs ARM ) est un cache spécialisé qui stocke les premières instructions à l'adresse de destination d'un branchement. Il est utilisé par les processeurs basse consommation qui n'ont pas besoin d'un cache d'instructions classique, car leur système mémoire est capable de fournir les instructions suffisamment rapidement pour satisfaire le processeur. Cependant, cela ne s'applique qu'aux instructions consécutives ; le redémarrage de la récupération d'une instruction à une nouvelle adresse nécessite toujours plusieurs cycles de latence, ce qui provoque une brève oscillation du pipeline après un transfert de contrôle. Un cache de cible de branchement fournit les instructions pour ces quelques cycles, évitant ainsi un délai après la plupart des branchements.
Cela permet un fonctionnement à pleine vitesse avec un cache beaucoup plus petit qu'un cache d'instructions traditionnel à temps plein.
Cache intelligent
Le cache intelligent est une méthode de mise en cache de niveau 2 ou 3 pour plusieurs cœurs d'exécution, développée par Intel .
Le cache intelligent partage la mémoire cache entre les cœurs d'un processeur multicœur . Comparé à un cache dédié par cœur, le taux global d'échecs de cache diminue lorsque les cœurs n'ont pas besoin de parts égales de l'espace cache. Par conséquent, un seul cœur peut utiliser la totalité du cache de niveau 2 ou 3 tandis que les autres cœurs sont inactifs. De plus, le cache partagé accélère le partage de mémoire entre les différents cœurs d'exécution.
eDRAM et montés sur un module multi-puces , constituant ainsi un quatrième niveau de cache. Dans de rares cas, comme pour le processeur du mainframe IBM z15 (2019), tous les niveaux jusqu'au cache L1 sont implémentés en eDRAM, remplaçant entièrement la SRAM (pour le cache, la SRAM étant toujours utilisée pour les registres ). La gamme de processeurs Apple Silicon , basée sur l'architecture ARM et comprenant les A14 et M1 , dispose d'un cache L1i de 192 Kio pour chacun des cœurs hautes performances, une capacité exceptionnellement élevée ; en revanche, les cœurs basse consommation ne disposent que de 128 Kio. Depuis, d'autres processeurs tels que Lunar Lake d' Intel et Oryon de Qualcomm ont également implémenté des tailles de cache L1i similaires.Les avantages des caches L3 et L4 dépendent des modèles d'accès de l'application. Voici quelques exemples de produits intégrant des caches L3 et L4 :
- Alpha 21164 (1995) disposait d'un cache L3 hors puce de 1 à 64 Mio.
- L'AMD K6-III (1999) disposait d'un cache L3 basé sur la carte mère.
- IBM POWER4 (2001) disposait de caches L3 hors puce de 32 Mio par processeur, partagés entre plusieurs processeurs.
- L'Itanium 2 (2003) disposait d'un cache Itanium 2 (2003) MX 2 incorporait deux processeurs Itanium 2 ainsi qu'un cache L4 partagé de 64 Mio sur un module multi-puces compatible broche à broche avec un processeur Madison.
- Le produit Intel Xeon MP, nom de code « Tulsa » (2006), dispose de 16 Mio de cache L3 intégré partagé entre deux cœurs de processeur.
- AMD Phenom (2007) avec 2 Mio de cache L3.
- L'AMD Phenom II (2008) dispose d'un cache L3 unifié sur puce allant jusqu'à 6 Mio.
- Intel Core i7 (2008) possède un cache L3 unifié sur puce de 8 Mio, inclusif et partagé par tous les cœurs.
- Les processeurs Intel Haswell avec carte graphique intégrée Intel Iris Pro disposent de 128 Mio d'eDRAM faisant essentiellement office de cache L4.
Enfin, à l'autre extrémité de la hiérarchie mémoire, le fichier de registres du processeur peut être considéré comme le cache le plus petit et le plus rapide du système. Sa particularité réside dans le fait qu'il est géré par logiciel, généralement par le compilateur, qui alloue des registres pour stocker les valeurs extraites de la mémoire principale, par exemple pour l'optimisation des boucles imbriquées . Cependant, grâce au renommage des registres , la plupart des affectations de registres du compilateur sont réallouées dynamiquement par le matériel à l'exécution dans un banc de registres, permettant ainsi au processeur de rompre les dépendances de données erronées et d'atténuer les risques liés au pipeline.
Les fichiers de registres présentent parfois une hiérarchie : le Cray-1 (vers 1976) disposait de huit registres d’adresse « A » et de huit registres de données scalaires « S » généralement utilisables. Il comportait également 64 registres d’adresse « B » et 64 registres de données scalaires « T », dont l’accès était plus lent, mais plus rapide que la mémoire principale. Les registres « B » et « T » étaient nécessaires car le Cray-1 ne possédait pas de cache de données. (Le Cray-1 disposait toutefois d’un cache d’instructions.)
multicœur , la question se pose de savoir si les caches doivent être partagés ou locaux à chaque cœur. La mise en œuvre d'un cache partagé engendre inévitablement un câblage plus complexe. En revanche, disposer d'un cache par puce , plutôt que par cœur , réduit considérablement l'espace nécessaire et permet ainsi d'intégrer un cache de plus grande capacité.En règle générale, le partage du cache L1 est déconseillé car l'augmentation de latence qui en résulte ralentirait considérablement chaque cœur par rapport à une puce monocœur. Cependant, pour le cache de plus haut niveau (généralement L3, le dernier appelé avant l'accès à la mémoire), un cache global est souhaitable pour plusieurs raisons : il permet à un seul cœur d'utiliser l'intégralité du cache, réduit la redondance des données en autorisant différents processus ou threads à partager les données mises en cache, et simplifie les protocoles de cohérence de cache utilisés. Par exemple, une puce à huit cœurs avec trois niveaux de cache peut inclure un cache L1 par cœur, un cache L2 intermédiaire pour chaque paire de cœurs et un cache L3 partagé par tous les cœurs.
Un cache de niveau le plus élevé partagé (généralement L3, appelé avant l'accès à la mémoire) est généralement désigné sous le nom de cache de dernier niveau (LLC). Des techniques supplémentaires sont utilisées pour augmenter le niveau de parallélisme lorsque le LLC est partagé entre plusieurs cœurs, notamment en le divisant en plusieurs morceaux qui adressent des plages d'adresses mémoire spécifiques et peuvent être utilisés indépendamment.
Séparés versus unifiés
Dans une structure de cache séparée, les instructions et les données sont mises en cache séparément ; une ligne de cache sert donc soit aux instructions, soit aux données, mais pas aux deux. L’utilisation de tampons de traduction d’instructions et de données distincts présente divers avantages . Dans une structure unifiée, cette contrainte disparaît et les lignes de cache peuvent servir à la fois aux instructions et aux données.
AMD Athlon ) utilisent des caches exclusifs : les données sont garanties de se trouver dans au plus l'un des caches L1 ou L2, jamais dans les deux. D'autres processeurs encore (comme les Intel Pentium II , III et 4 ) n'exigent pas que les données du cache L1 résident également dans le cache L2, bien que cela soit souvent le cas. Il n'existe pas de nom universellement accepté pour cette politique intermédiaire ; deux appellations courantes sont « non exclusif » et « partiellement inclusif ».L’avantage des caches exclusifs réside dans leur capacité de stockage supérieure. Cet avantage est plus marqué lorsque le cache L1 exclusif est comparable au cache L2, et diminue si le cache L2 est beaucoup plus grand que le cache L1. En cas d’échec d’accès dans le cache L1 et de succès dans le cache L2, la ligne correspondante dans le cache L2 est échangée avec une ligne du cache L1. Cet échange est beaucoup plus complexe que la simple copie d’une ligne du cache L2 vers le cache L1, opération effectuée par un cache inclusif.
L'un des avantages des caches strictement inclusifs est que, lorsqu'un périphérique externe ou un autre processeur d'un système multiprocesseur souhaite supprimer une ligne de cache du processeur, il suffit que ce dernier consulte le cache L2. Dans les hiérarchies de caches n'imposant pas l'inclusion, le cache L1 doit également être consulté. En revanche, il existe une corrélation entre les associativités des caches L1 et L2 : si le cache L2 ne possède pas au moins autant de voies que l'ensemble des caches L1, l'associativité effective de ces derniers est limitée. Un autre inconvénient des caches inclusifs est que, lors de toute éviction dans le cache L2, les lignes (potentiellement) correspondantes dans le cache L1 doivent également être évincées afin de maintenir l'inclusivité. Cette opération est conséquente et entraîne un taux d'échecs de cache L1 plus élevé.
Un autre avantage des caches inclusifs est que le cache principal peut utiliser des lignes de cache plus larges, ce qui réduit la taille des étiquettes du cache secondaire. (Les caches exclusifs exigent que les deux caches aient des lignes de cache de même taille, afin que les lignes puissent être permutées en cas d'échec de cache L1 et de succès de cache L2.) Si le cache secondaire est dix fois plus grand que le cache principal, et que les données du cache sont dix fois plus grandes que les étiquettes de cache, la surface d'étiquettes ainsi économisée peut être comparable à la surface incrémentale nécessaire pour stocker les données du cache L1 dans le cache L2.
Mémoire du bloc-notes
La mémoire scratchpad (SPM), également connue sous le nom de mémoire scratchpad, mémoire RAM scratchpad ou mémoire locale dans la terminologie informatique, est une mémoire interne à haute vitesse utilisée pour le stockage temporaire de calculs, de données et d'autres travaux en cours.Exemple : le K8
Pour illustrer à la fois la spécialisation et la mise en cache multiniveau, voici la hiérarchie de cache du cœur K8 du processeur AMD Athlon 64.
Hiérarchie du cache du cœur K8 du processeur AMD Athlon 64 Le K8 possède quatre caches spécialisés : un cache d’instructions, un TLB d’instructions , un TLB de données et un cache de données. Chacun de ces caches est spécialisé :
- Le cache d'instructions conserve des copies de lignes de mémoire de 64 octets et en extrait 16 à chaque cycle. Chaque octet de ce cache est stocké sur dix bits au lieu de huit, les bits supplémentaires marquant les limites des instructions (il s'agit d'un exemple de prédécodage). Le cache utilise uniquement la parité plutôt que la correction d'erreurs (ECC ), car la parité est plus petite et toute donnée corrompue peut être remplacée par des données fraîches extraites de la mémoire (qui contient toujours une copie à jour des instructions).
- Le TLB d'instructions conserve des copies des entrées de table des pages (PTE). À chaque cycle, l'adresse virtuelle de chaque instruction est traduite par ce TLB en une adresse physique. Chaque entrée occupe quatre ou huit octets en mémoire. Le K8 ayant une taille de page variable, chaque TLB est divisé en deux sections : l'une pour les PTE correspondant à des pages de 4 Kio, l'autre pour celles correspondant à des pages de 4 Mio ou 2 Mio. Cette division simplifie le circuit d'association dans chaque section. Le système d'exploitation associe des PTE de tailles différentes aux différentes sections de l'espace d'adressage virtuel.
- Le TLB de données possède deux copies contenant des entrées identiques. Ces deux copies permettent deux accès aux données par cycle pour traduire les adresses virtuelles en adresses physiques. À l'instar du TLB d'instructions, ce TLB est divisé en deux types d'entrées.
- Le cache de données conserve des copies de lignes de mémoire de 64 octets. Il est divisé en 8 banques (chacune stockant 8 Kio de données) et peut accéder à deux ensembles de données de 8 octets par cycle, à condition qu'ils se trouvent dans des banques différentes. Il existe deux copies des étiquettes, car chaque ligne de 64 octets est répartie entre les huit banques. Chaque copie d'étiquette gère l'un des deux accès par cycle.
Le K8 dispose également de caches à plusieurs niveaux. Il existe des TLB d'instructions et de données de second niveau, qui stockent uniquement des entrées de table de pages (PTE) mappant 4 KiB. Les caches d'instructions et de données, ainsi que les différents TLB, peuvent être alimentés par le vaste cache L2 unifié . Ce cache est exclusif aux caches d'instructions et de données L1, ce qui signifie que toute ligne de 8 octets ne peut se trouver que dans l'un des caches suivants : le cache d'instructions L1, le cache de données L1 ou le cache L2. Il est toutefois possible qu'une ligne du cache de données contienne une PTE présente également dans l'un des TLB ; le système d'exploitation assure la cohérence des TLB en vidant certaines portions de ces derniers lors de la mise à jour des tables de pages en mémoire.
Le K8 met également en cache des informations qui ne sont jamais stockées en mémoire : les informations de prédiction. Ces caches ne sont pas représentés sur le schéma ci-dessus. Comme c'est souvent le cas pour ce type de processeur, le K8 dispose d'une prédiction de branchement assez complexe , avec des tables permettant de prédire si des branchements seront effectués et d'autres tables prédisant les cibles des branchements et des sauts. Certaines de ces informations sont associées aux instructions, à la fois dans le cache d'instructions de niveau 1 et dans le cache secondaire unifié.
Le K8 utilise une astuce ingénieuse pour stocker les informations de prédiction avec les instructions dans le cache secondaire. Les lignes de ce cache sont protégées contre toute corruption accidentelle de données (par exemple, suite à l'impact d'une particule alpha ) par un système de correction d'erreurs (ECC) ou par parité , selon qu'elles proviennent du cache principal de données ou d'instructions. Le code de parité occupant moins de bits que le code ECC, les lignes du cache d'instructions disposent de quelques bits supplémentaires. Ces bits servent à stocker les informations de prédiction de branchement associées à ces instructions. Il en résulte un historique de branchement plus étendu pour le prédicteur de branchement, et donc une meilleure précision.
Plus de hiérarchies
D'autres processeurs disposent d'autres types de prédicteurs (par exemple, le prédicteur de contournement de stockage à chargement dans le DEC Alpha 21264 ).
Ces prédicteurs sont des caches, car ils stockent des informations dont le calcul est coûteux. Certains termes employés pour parler des prédicteurs sont les mêmes que ceux utilisés pour les caches (on parle par exemple de « succès » dans un prédicteur de branchement), mais les prédicteurs ne sont généralement pas considérés comme faisant partie de la hiérarchie des caches.
Le K8 assure la cohérence matérielle des caches d'instructions et de données, ce qui signifie qu'une instruction de stockage effectuée juste après une autre modifiera l'instruction suivante. D'autres processeurs, comme ceux des familles Alpha et MIPS, s'appuient sur le logiciel pour maintenir la cohérence du cache d'instructions. L'affichage des instructions de stockage dans le flux d'instructions n'est garanti que lorsqu'un programme appelle une fonction du système d'exploitation pour assurer cette cohérence.
Étiquette RAM
Tag RAM sur la carte d'un Intel Pentium III En génie informatique, une mémoire RAM étiquetée permet de spécifier quelle adresse mémoire est actuellement stockée dans le cache du processeur. Pour une conception simple à correspondance directe, une SRAM rapide peut être utilisée. Les caches associatifs de niveau supérieur utilisent généralement une mémoire adressable par contenu .
Mise en œuvre
Chemin de lecture pour un cache associatif à deux voies Le schéma ci-contre vise à clarifier l'utilisation des différents champs de l'adresse. Le bit 31 est le plus significatif, le bit 0 le moins significatif. Ce schéma représente les SRAM, l'indexation et le multiplexage d'un cache de 4 Kio, associatif par ensembles à deux voies, indexé et étiqueté virtuellement, avec des lignes de 64 octets (B), une largeur de lecture de 32 bits et une adresse virtuelle de 32 bits.
Le cache ayant une capacité de 4 KiB et comportant 64 lignes d'octets, il ne contient que 64 lignes. La lecture s'effectue par paires à partir d'une SRAM d'étiquettes de 32 lignes, chacune associée à une paire d'étiquettes de 21 bits. Bien que toute fonction des bits d'adresse virtuelle 31 à 6 puisse être utilisée pour indexer les SRAM d'étiquettes et de données, l'utilisation des bits de poids faible est plus simple.
De même, étant donné que le cache fait 4 KiB et possède un chemin de lecture de 4 B, et qu'il lit de deux manières pour chaque accès, la SRAM de données comporte 512 lignes de 8 octets de large.
Un cache plus moderne pourrait avoir une capacité de 16 Kio, être associatif par ensembles à 4 voies, indexé virtuellement, avec des indications virtuelles et un marquage physique, avec des lignes de 32 octets, une largeur de lecture de 32 bits et des adresses physiques de 36 bits. Le chemin de lecture pour un tel cache est très similaire à celui décrit précédemment. Au lieu d'étiquettes, ce sont des indications virtuelles qui sont lues et comparées à un sous-ensemble de l'adresse virtuelle. Plus tard dans le pipeline, l'adresse virtuelle est traduite en adresse physique par le TLB, et l'étiquette physique correspondante est lue (une seule, car l'indication virtuelle indique le sens de lecture dans le cache). Enfin, l'adresse physique est comparée à l'étiquette physique pour déterminer si une correspondance a été trouvée.
Certaines conceptions SPARC ont amélioré la vitesse de leurs caches L1 de quelques délais de porte en intégrant l'additionneur d'adresses virtuelles dans les décodeurs SRAM.aux registres . Mais depuis les années 1980 l'écart de performance entre le processeur et la mémoire n'a cessé de se creuser. Les microprocesseurs ont progressé beaucoup plus vite que la mémoire, notamment en termes de fréquence de fonctionnement , faisant de cette dernière un goulot d'étranglement. S'il était techniquement possible d'avoir une mémoire principale aussi rapide que le processeur, une solution plus économique a été privilégiée : utiliser une grande quantité de mémoire basse vitesse, tout en intégrant une petite mémoire cache haute vitesse pour compenser l'écart de performance. Cette approche a permis d'obtenir une capacité dix fois supérieure – pour un coût identique – avec une légère diminution des performances globales.
Premières implémentations TLB
Les premières utilisations documentées d'un TLB ont eu lieu sur le GE 645 et l' IBM 360/67 , qui utilisaient tous deux une mémoire associative comme TLB.
Cache de première instruction
La première utilisation documentée d'un cache d'instructions a eu lieu sur le CDC 6600.
Premier cache de données
La première utilisation documentée d'un cache de données a eu lieu sur le système IBM System/360 modèle 85.
Dans les microprocesseurs 68k
Le 68010 , sorti en 1982, dispose d'un « mode boucle » pouvant être considéré comme un cache d'instructions réduit et spécifique, accélérant les boucles composées de seulement deux instructions. Le 68020 , sorti en 1984, a remplacé ce mode par un cache d'instructions classique de 256 octets, devenant ainsi le premier processeur de la série 68k à intégrer une véritable mémoire cache sur puce.
Le 68030 , sorti en 1987, est essentiellement un cœur 68020 avec un cache de données supplémentaire de 256 octets, une unité de gestion de la mémoire sur puce (MMU), une réduction de processus et un mode rafale ajouté pour les caches.
Le 68040 , sorti en 1990, possède des caches d'instructions et de données séparés de quatre kilo-octets chacun.
Le 68060 , sorti en 1994, possède les éléments suivants : cache de données de 8 KiB (associatif à quatre voies), cache d'instructions de 8 KiB (associatif à quatre voies), tampon d'instructions FIFO de 96 octets, cache de branchement de 256 entrées et tampon MMU de cache de traduction d'adresses de 64 entrées (associatif à quatre voies).
Dans les microprocesseurs x86
Exemple de carte mère avec un microprocesseur i386 (33 MHz), 64 KiB de cache (25 ns ; 8 puces dans le coin inférieur gauche), 2 Mio de DRAM (70 ns ; 8 SIMM à droite du cache) et un contrôleur de cache ( Austek A38202 ; à droite du processeur). Avec l'arrivée des microprocesseurs x86 à des fréquences d'horloge de 20 MHz et plus (notamment l' A386) , de petites quantités de mémoire cache rapide ont commencé à être intégrées aux systèmes pour améliorer leurs performances. En effet, la DRAM utilisée comme mémoire principale présentait une latence importante, pouvant atteindre 120 ns, ainsi que des cycles de rafraîchissement. Le cache était constitué de cellules de mémoire SRAM , plus coûteuses mais nettement plus rapides, dont la latence était alors de l'ordre de 10 à 25 ns. Les premiers caches étaient externes au processeur et généralement situés sur la carte mère sous la forme de huit ou neuf composants DIP insérés dans des supports, permettant ainsi d'ajouter le cache en option ou de l'étendre.
Certaines versions du processeur Intel 386 pouvaient prendre en charge de 16 à 256 KiB de cache externe.
Avec le processeur 486 , un cache de 8 Kio était intégré directement à la puce. Ce cache était appelé cache de niveau 1 (L1) pour le différencier du cache de niveau 2 (L2), plus lent et situé sur la carte mère. Ces derniers étaient beaucoup plus volumineux, la taille la plus courante étant de 256 Kio. Certaines cartes mères disposaient d'emplacements pour la carte fille Intel 485Turbocache , dotée de 64 ou 128 Ko de mémoire cache. La popularité du cache sur carte mère s'est maintenue durant l' ère Pentium MMX , mais a été rendue obsolète par l'introduction de la SDRAM et l'écart croissant entre les fréquences d'horloge du bus et du processeur, ce qui a fait que le cache sur carte mère n'était plus que légèrement plus rapide que la mémoire principale.
L'évolution suivante en matière d'implémentation de cache dans les microprocesseurs x86 a commencé avec le Pentium Pro , qui a intégré le cache secondaire dans le même boîtier que le microprocesseur, cadencé à la même fréquence que ce dernier.
Les caches intégrés à la carte mère ont longtemps bénéficié d'une grande popularité grâce aux processeurs AMD K6-2 et AMD K6-III , qui utilisaient encore le socket 7 , précédemment employé par Intel avec des caches intégrés. Le K6-III intégrait 256 Kio de cache L2 et exploitait le cache intégré comme cache de troisième niveau, appelé L3 (des cartes mères avec jusqu'à 2 Mio de cache intégré ont été produites). Après l'obsolescence du socket 7, le cache intégré à la carte mère a disparu des systèmes x86.
Les caches à trois niveaux ont été réutilisés pour la première fois avec l'introduction du processeur Intel Xeon MP « Foster Core » , où le cache L3 a été ajouté à la puce du processeur. Il est devenu courant que la taille totale du cache augmente avec les nouvelles générations de processeurs, et récemment (en 2011), il n'est pas rare de trouver des caches de niveau 3 de plusieurs dizaines de mégaoctets
Intel a introduit un cache de niveau 4 intégré avec la microarchitecture Haswell . Les processeurs Crystalwell Haswell, équipés de la variante GT3e du processeur graphique intégré Intel Iris Pro, disposent de 128 Mio de mémoire DRAM embarquée ( eDRAM ) sur le même boîtier. Ce cache L4 est partagé dynamiquement entre le GPU et le CPU intégrés, et sert de cache victime au cache L3 du CPU.
Dans les microprocesseurs ARM
Le processeur Apple M1 dispose de 128 ou 192 Kio de cache d'instructions L1 par cœur (important pour la latence et les performances monocœur), selon le type de cœur. Il s'agit d'un cache L1 exceptionnellement important pour un processeur (et pas seulement pour un ordinateur portable). La taille totale de la mémoire cache n'est pas particulièrement élevée pour un ordinateur portable (c'est le total qui importe le plus pour le débit), et des tailles totales bien supérieures (par exemple, L3 ou L4) sont disponibles sur les ordinateurs centraux IBM.
Recherches actuelles
Les premières conceptions de cache se concentraient exclusivement sur le coût direct du cache et de la RAM , ainsi que sur la vitesse d'exécution moyenne. Les conceptions de cache plus récentes prennent également en compte l'efficacité énergétique , la tolérance aux pannes et d'autres objectifs.
Plusieurs outils sont à la disposition des architectes informatiques pour les aider à explorer les compromis entre le temps de cycle du cache, l'énergie et la surface ; le simulateur de cache CACTI et le simulateur de jeu d'instructions SimpleScalar sont deux options open-source.
Cache multiport
Un cache multiport est un cache capable de traiter plusieurs requêtes simultanément. Alors qu'un cache traditionnel utilise généralement une seule adresse mémoire, un cache multiport peut permettre de demander N adresses à la fois, N étant le nombre de ports connectés entre le processeur et le cache. L'avantage est qu'un processeur pipeliné peut accéder à la mémoire depuis différentes phases de son pipeline. Autre avantage : il rend possible le concept de processeurs superscalaires grâce à différents niveaux de cache.
Plus d articles de Worldlex Wiki
Revenez a l index pour explorer davantage de pages sur l histoire, la science, la culture, la geographie et la societe en francais.
Explorer l index
multicœur , la question se pose de savoir si les caches doivent être partagés ou locaux à chaque cœur. La mise en œuvre d'un cache partagé engendre inévitablement un câblage plus complexe. En revanche, disposer d'un cache par puce , plutôt que par cœur , réduit considérablement l'espace nécessaire et permet ainsi d'intégrer un cache de plus grande capacité.En règle générale, le partage du cache L1 est déconseillé car l'augmentation de latence qui en résulte ralentirait considérablement chaque cœur par rapport à une puce monocœur. Cependant, pour le cache de plus haut niveau (généralement L3, le dernier appelé avant l'accès à la mémoire), un cache global est souhaitable pour plusieurs raisons : il permet à un seul cœur d'utiliser l'intégralité du cache, réduit la redondance des données en autorisant différents processus ou threads à partager les données mises en cache, et simplifie les protocoles de cohérence de cache utilisés. Par exemple, une puce à huit cœurs avec trois niveaux de cache peut inclure un cache L1 par cœur, un cache L2 intermédiaire pour chaque paire de cœurs et un cache L3 partagé par tous les cœurs.
Un cache de niveau le plus élevé partagé (généralement L3, appelé avant l'accès à la mémoire) est généralement désigné sous le nom de cache de dernier niveau (LLC). Des techniques supplémentaires sont utilisées pour augmenter le niveau de parallélisme lorsque le LLC est partagé entre plusieurs cœurs, notamment en le divisant en plusieurs morceaux qui adressent des plages d'adresses mémoire spécifiques et peuvent être utilisés indépendamment.
Séparés versus unifiés
Dans une structure de cache séparée, les instructions et les données sont mises en cache séparément ; une ligne de cache sert donc soit aux instructions, soit aux données, mais pas aux deux. L’utilisation de tampons de traduction d’instructions et de données distincts présente divers avantages . Dans une structure unifiée, cette contrainte disparaît et les lignes de cache peuvent servir à la fois aux instructions et aux données.
AMD Athlon ) utilisent des caches exclusifs : les données sont garanties de se trouver dans au plus l'un des caches L1 ou L2, jamais dans les deux. D'autres processeurs encore (comme les Intel Pentium II , III et 4 ) n'exigent pas que les données du cache L1 résident également dans le cache L2, bien que cela soit souvent le cas. Il n'existe pas de nom universellement accepté pour cette politique intermédiaire ; deux appellations courantes sont « non exclusif » et « partiellement inclusif ».L’avantage des caches exclusifs réside dans leur capacité de stockage supérieure. Cet avantage est plus marqué lorsque le cache L1 exclusif est comparable au cache L2, et diminue si le cache L2 est beaucoup plus grand que le cache L1. En cas d’échec d’accès dans le cache L1 et de succès dans le cache L2, la ligne correspondante dans le cache L2 est échangée avec une ligne du cache L1. Cet échange est beaucoup plus complexe que la simple copie d’une ligne du cache L2 vers le cache L1, opération effectuée par un cache inclusif.
L'un des avantages des caches strictement inclusifs est que, lorsqu'un périphérique externe ou un autre processeur d'un système multiprocesseur souhaite supprimer une ligne de cache du processeur, il suffit que ce dernier consulte le cache L2. Dans les hiérarchies de caches n'imposant pas l'inclusion, le cache L1 doit également être consulté. En revanche, il existe une corrélation entre les associativités des caches L1 et L2 : si le cache L2 ne possède pas au moins autant de voies que l'ensemble des caches L1, l'associativité effective de ces derniers est limitée. Un autre inconvénient des caches inclusifs est que, lors de toute éviction dans le cache L2, les lignes (potentiellement) correspondantes dans le cache L1 doivent également être évincées afin de maintenir l'inclusivité. Cette opération est conséquente et entraîne un taux d'échecs de cache L1 plus élevé.
Un autre avantage des caches inclusifs est que le cache principal peut utiliser des lignes de cache plus larges, ce qui réduit la taille des étiquettes du cache secondaire. (Les caches exclusifs exigent que les deux caches aient des lignes de cache de même taille, afin que les lignes puissent être permutées en cas d'échec de cache L1 et de succès de cache L2.) Si le cache secondaire est dix fois plus grand que le cache principal, et que les données du cache sont dix fois plus grandes que les étiquettes de cache, la surface d'étiquettes ainsi économisée peut être comparable à la surface incrémentale nécessaire pour stocker les données du cache L1 dans le cache L2.
Mémoire du bloc-notes
La mémoire scratchpad (SPM), également connue sous le nom de mémoire scratchpad, mémoire RAM scratchpad ou mémoire locale dans la terminologie informatique, est une mémoire interne à haute vitesse utilisée pour le stockage temporaire de calculs, de données et d'autres travaux en cours.Exemple : le K8
Pour illustrer à la fois la spécialisation et la mise en cache multiniveau, voici la hiérarchie de cache du cœur K8 du processeur AMD Athlon 64.
Hiérarchie du cache du cœur K8 du processeur AMD Athlon 64 Le K8 possède quatre caches spécialisés : un cache d’instructions, un TLB d’instructions , un TLB de données et un cache de données. Chacun de ces caches est spécialisé :
- Le cache d'instructions conserve des copies de lignes de mémoire de 64 octets et en extrait 16 à chaque cycle. Chaque octet de ce cache est stocké sur dix bits au lieu de huit, les bits supplémentaires marquant les limites des instructions (il s'agit d'un exemple de prédécodage). Le cache utilise uniquement la parité plutôt que la correction d'erreurs (ECC ), car la parité est plus petite et toute donnée corrompue peut être remplacée par des données fraîches extraites de la mémoire (qui contient toujours une copie à jour des instructions).
- Le TLB d'instructions conserve des copies des entrées de table des pages (PTE). À chaque cycle, l'adresse virtuelle de chaque instruction est traduite par ce TLB en une adresse physique. Chaque entrée occupe quatre ou huit octets en mémoire. Le K8 ayant une taille de page variable, chaque TLB est divisé en deux sections : l'une pour les PTE correspondant à des pages de 4 Kio, l'autre pour celles correspondant à des pages de 4 Mio ou 2 Mio. Cette division simplifie le circuit d'association dans chaque section. Le système d'exploitation associe des PTE de tailles différentes aux différentes sections de l'espace d'adressage virtuel.
- Le TLB de données possède deux copies contenant des entrées identiques. Ces deux copies permettent deux accès aux données par cycle pour traduire les adresses virtuelles en adresses physiques. À l'instar du TLB d'instructions, ce TLB est divisé en deux types d'entrées.
- Le cache de données conserve des copies de lignes de mémoire de 64 octets. Il est divisé en 8 banques (chacune stockant 8 Kio de données) et peut accéder à deux ensembles de données de 8 octets par cycle, à condition qu'ils se trouvent dans des banques différentes. Il existe deux copies des étiquettes, car chaque ligne de 64 octets est répartie entre les huit banques. Chaque copie d'étiquette gère l'un des deux accès par cycle.
Le K8 dispose également de caches à plusieurs niveaux. Il existe des TLB d'instructions et de données de second niveau, qui stockent uniquement des entrées de table de pages (PTE) mappant 4 KiB. Les caches d'instructions et de données, ainsi que les différents TLB, peuvent être alimentés par le vaste cache L2 unifié . Ce cache est exclusif aux caches d'instructions et de données L1, ce qui signifie que toute ligne de 8 octets ne peut se trouver que dans l'un des caches suivants : le cache d'instructions L1, le cache de données L1 ou le cache L2. Il est toutefois possible qu'une ligne du cache de données contienne une PTE présente également dans l'un des TLB ; le système d'exploitation assure la cohérence des TLB en vidant certaines portions de ces derniers lors de la mise à jour des tables de pages en mémoire.
Le K8 met également en cache des informations qui ne sont jamais stockées en mémoire : les informations de prédiction. Ces caches ne sont pas représentés sur le schéma ci-dessus. Comme c'est souvent le cas pour ce type de processeur, le K8 dispose d'une prédiction de branchement assez complexe , avec des tables permettant de prédire si des branchements seront effectués et d'autres tables prédisant les cibles des branchements et des sauts. Certaines de ces informations sont associées aux instructions, à la fois dans le cache d'instructions de niveau 1 et dans le cache secondaire unifié.
Le K8 utilise une astuce ingénieuse pour stocker les informations de prédiction avec les instructions dans le cache secondaire. Les lignes de ce cache sont protégées contre toute corruption accidentelle de données (par exemple, suite à l'impact d'une particule alpha ) par un système de correction d'erreurs (ECC) ou par parité , selon qu'elles proviennent du cache principal de données ou d'instructions. Le code de parité occupant moins de bits que le code ECC, les lignes du cache d'instructions disposent de quelques bits supplémentaires. Ces bits servent à stocker les informations de prédiction de branchement associées à ces instructions. Il en résulte un historique de branchement plus étendu pour le prédicteur de branchement, et donc une meilleure précision.
Plus de hiérarchies
D'autres processeurs disposent d'autres types de prédicteurs (par exemple, le prédicteur de contournement de stockage à chargement dans le DEC Alpha 21264 ).
Ces prédicteurs sont des caches, car ils stockent des informations dont le calcul est coûteux. Certains termes employés pour parler des prédicteurs sont les mêmes que ceux utilisés pour les caches (on parle par exemple de « succès » dans un prédicteur de branchement), mais les prédicteurs ne sont généralement pas considérés comme faisant partie de la hiérarchie des caches.
Le K8 assure la cohérence matérielle des caches d'instructions et de données, ce qui signifie qu'une instruction de stockage effectuée juste après une autre modifiera l'instruction suivante. D'autres processeurs, comme ceux des familles Alpha et MIPS, s'appuient sur le logiciel pour maintenir la cohérence du cache d'instructions. L'affichage des instructions de stockage dans le flux d'instructions n'est garanti que lorsqu'un programme appelle une fonction du système d'exploitation pour assurer cette cohérence.
Étiquette RAM
Tag RAM sur la carte d'un Intel Pentium III En génie informatique, une mémoire RAM étiquetée permet de spécifier quelle adresse mémoire est actuellement stockée dans le cache du processeur. Pour une conception simple à correspondance directe, une SRAM rapide peut être utilisée. Les caches associatifs de niveau supérieur utilisent généralement une mémoire adressable par contenu .
Mise en œuvre
Chemin de lecture pour un cache associatif à deux voies Le schéma ci-contre vise à clarifier l'utilisation des différents champs de l'adresse. Le bit 31 est le plus significatif, le bit 0 le moins significatif. Ce schéma représente les SRAM, l'indexation et le multiplexage d'un cache de 4 Kio, associatif par ensembles à deux voies, indexé et étiqueté virtuellement, avec des lignes de 64 octets (B), une largeur de lecture de 32 bits et une adresse virtuelle de 32 bits.
Le cache ayant une capacité de 4 KiB et comportant 64 lignes d'octets, il ne contient que 64 lignes. La lecture s'effectue par paires à partir d'une SRAM d'étiquettes de 32 lignes, chacune associée à une paire d'étiquettes de 21 bits. Bien que toute fonction des bits d'adresse virtuelle 31 à 6 puisse être utilisée pour indexer les SRAM d'étiquettes et de données, l'utilisation des bits de poids faible est plus simple.
De même, étant donné que le cache fait 4 KiB et possède un chemin de lecture de 4 B, et qu'il lit de deux manières pour chaque accès, la SRAM de données comporte 512 lignes de 8 octets de large.
Un cache plus moderne pourrait avoir une capacité de 16 Kio, être associatif par ensembles à 4 voies, indexé virtuellement, avec des indications virtuelles et un marquage physique, avec des lignes de 32 octets, une largeur de lecture de 32 bits et des adresses physiques de 36 bits. Le chemin de lecture pour un tel cache est très similaire à celui décrit précédemment. Au lieu d'étiquettes, ce sont des indications virtuelles qui sont lues et comparées à un sous-ensemble de l'adresse virtuelle. Plus tard dans le pipeline, l'adresse virtuelle est traduite en adresse physique par le TLB, et l'étiquette physique correspondante est lue (une seule, car l'indication virtuelle indique le sens de lecture dans le cache). Enfin, l'adresse physique est comparée à l'étiquette physique pour déterminer si une correspondance a été trouvée.
Certaines conceptions SPARC ont amélioré la vitesse de leurs caches L1 de quelques délais de porte en intégrant l'additionneur d'adresses virtuelles dans les décodeurs SRAM.aux registres . Mais depuis les années 1980 l'écart de performance entre le processeur et la mémoire n'a cessé de se creuser. Les microprocesseurs ont progressé beaucoup plus vite que la mémoire, notamment en termes de fréquence de fonctionnement , faisant de cette dernière un goulot d'étranglement. S'il était techniquement possible d'avoir une mémoire principale aussi rapide que le processeur, une solution plus économique a été privilégiée : utiliser une grande quantité de mémoire basse vitesse, tout en intégrant une petite mémoire cache haute vitesse pour compenser l'écart de performance. Cette approche a permis d'obtenir une capacité dix fois supérieure – pour un coût identique – avec une légère diminution des performances globales.
Premières implémentations TLB
Les premières utilisations documentées d'un TLB ont eu lieu sur le GE 645 et l' IBM 360/67 , qui utilisaient tous deux une mémoire associative comme TLB.
Cache de première instruction
La première utilisation documentée d'un cache d'instructions a eu lieu sur le CDC 6600.
Premier cache de données
La première utilisation documentée d'un cache de données a eu lieu sur le système IBM System/360 modèle 85.
Dans les microprocesseurs 68k
Le 68010 , sorti en 1982, dispose d'un « mode boucle » pouvant être considéré comme un cache d'instructions réduit et spécifique, accélérant les boucles composées de seulement deux instructions. Le 68020 , sorti en 1984, a remplacé ce mode par un cache d'instructions classique de 256 octets, devenant ainsi le premier processeur de la série 68k à intégrer une véritable mémoire cache sur puce.
Le 68030 , sorti en 1987, est essentiellement un cœur 68020 avec un cache de données supplémentaire de 256 octets, une unité de gestion de la mémoire sur puce (MMU), une réduction de processus et un mode rafale ajouté pour les caches.
Le 68040 , sorti en 1990, possède des caches d'instructions et de données séparés de quatre kilo-octets chacun.
Le 68060 , sorti en 1994, possède les éléments suivants : cache de données de 8 KiB (associatif à quatre voies), cache d'instructions de 8 KiB (associatif à quatre voies), tampon d'instructions FIFO de 96 octets, cache de branchement de 256 entrées et tampon MMU de cache de traduction d'adresses de 64 entrées (associatif à quatre voies).
Dans les microprocesseurs x86
Exemple de carte mère avec un microprocesseur i386 (33 MHz), 64 KiB de cache (25 ns ; 8 puces dans le coin inférieur gauche), 2 Mio de DRAM (70 ns ; 8 SIMM à droite du cache) et un contrôleur de cache ( Austek A38202 ; à droite du processeur). Avec l'arrivée des microprocesseurs x86 à des fréquences d'horloge de 20 MHz et plus (notamment l' A386) , de petites quantités de mémoire cache rapide ont commencé à être intégrées aux systèmes pour améliorer leurs performances. En effet, la DRAM utilisée comme mémoire principale présentait une latence importante, pouvant atteindre 120 ns, ainsi que des cycles de rafraîchissement. Le cache était constitué de cellules de mémoire SRAM , plus coûteuses mais nettement plus rapides, dont la latence était alors de l'ordre de 10 à 25 ns. Les premiers caches étaient externes au processeur et généralement situés sur la carte mère sous la forme de huit ou neuf composants DIP insérés dans des supports, permettant ainsi d'ajouter le cache en option ou de l'étendre.
Certaines versions du processeur Intel 386 pouvaient prendre en charge de 16 à 256 KiB de cache externe.
Avec le processeur 486 , un cache de 8 Kio était intégré directement à la puce. Ce cache était appelé cache de niveau 1 (L1) pour le différencier du cache de niveau 2 (L2), plus lent et situé sur la carte mère. Ces derniers étaient beaucoup plus volumineux, la taille la plus courante étant de 256 Kio. Certaines cartes mères disposaient d'emplacements pour la carte fille Intel 485Turbocache , dotée de 64 ou 128 Ko de mémoire cache. La popularité du cache sur carte mère s'est maintenue durant l' ère Pentium MMX , mais a été rendue obsolète par l'introduction de la SDRAM et l'écart croissant entre les fréquences d'horloge du bus et du processeur, ce qui a fait que le cache sur carte mère n'était plus que légèrement plus rapide que la mémoire principale.
L'évolution suivante en matière d'implémentation de cache dans les microprocesseurs x86 a commencé avec le Pentium Pro , qui a intégré le cache secondaire dans le même boîtier que le microprocesseur, cadencé à la même fréquence que ce dernier.
Les caches intégrés à la carte mère ont longtemps bénéficié d'une grande popularité grâce aux processeurs AMD K6-2 et AMD K6-III , qui utilisaient encore le socket 7 , précédemment employé par Intel avec des caches intégrés. Le K6-III intégrait 256 Kio de cache L2 et exploitait le cache intégré comme cache de troisième niveau, appelé L3 (des cartes mères avec jusqu'à 2 Mio de cache intégré ont été produites). Après l'obsolescence du socket 7, le cache intégré à la carte mère a disparu des systèmes x86.
Les caches à trois niveaux ont été réutilisés pour la première fois avec l'introduction du processeur Intel Xeon MP « Foster Core » , où le cache L3 a été ajouté à la puce du processeur. Il est devenu courant que la taille totale du cache augmente avec les nouvelles générations de processeurs, et récemment (en 2011), il n'est pas rare de trouver des caches de niveau 3 de plusieurs dizaines de mégaoctets
Intel a introduit un cache de niveau 4 intégré avec la microarchitecture Haswell . Les processeurs Crystalwell Haswell, équipés de la variante GT3e du processeur graphique intégré Intel Iris Pro, disposent de 128 Mio de mémoire DRAM embarquée ( eDRAM ) sur le même boîtier. Ce cache L4 est partagé dynamiquement entre le GPU et le CPU intégrés, et sert de cache victime au cache L3 du CPU.
Dans les microprocesseurs ARM
Le processeur Apple M1 dispose de 128 ou 192 Kio de cache d'instructions L1 par cœur (important pour la latence et les performances monocœur), selon le type de cœur. Il s'agit d'un cache L1 exceptionnellement important pour un processeur (et pas seulement pour un ordinateur portable). La taille totale de la mémoire cache n'est pas particulièrement élevée pour un ordinateur portable (c'est le total qui importe le plus pour le débit), et des tailles totales bien supérieures (par exemple, L3 ou L4) sont disponibles sur les ordinateurs centraux IBM.
Recherches actuelles
Les premières conceptions de cache se concentraient exclusivement sur le coût direct du cache et de la RAM , ainsi que sur la vitesse d'exécution moyenne. Les conceptions de cache plus récentes prennent également en compte l'efficacité énergétique , la tolérance aux pannes et d'autres objectifs.
Plusieurs outils sont à la disposition des architectes informatiques pour les aider à explorer les compromis entre le temps de cycle du cache, l'énergie et la surface ; le simulateur de cache CACTI et le simulateur de jeu d'instructions SimpleScalar sont deux options open-source.
Cache multiport
Un cache multiport est un cache capable de traiter plusieurs requêtes simultanément. Alors qu'un cache traditionnel utilise généralement une seule adresse mémoire, un cache multiport peut permettre de demander N adresses à la fois, N étant le nombre de ports connectés entre le processeur et le cache. L'avantage est qu'un processeur pipeliné peut accéder à la mémoire depuis différentes phases de son pipeline. Autre avantage : il rend possible le concept de processeurs superscalaires grâce à différents niveaux de cache.
Plus d articles de Worldlex Wiki
Revenez a l index pour explorer davantage de pages sur l histoire, la science, la culture, la geographie et la societe en francais.
Explorer l index
Séparés versus unifiés
Dans une structure de cache séparée, les instructions et les données sont mises en cache séparément ; une ligne de cache sert donc soit aux instructions, soit aux données, mais pas aux deux. L’utilisation de tampons de traduction d’instructions et de données distincts présente divers avantages . Dans une structure unifiée, cette contrainte disparaît et les lignes de cache peuvent servir à la fois aux instructions et aux données.
AMD Athlon ) utilisent des caches exclusifs : les données sont garanties de se trouver dans au plus l'un des caches L1 ou L2, jamais dans les deux. D'autres processeurs encore (comme les Intel Pentium II , III et 4 ) n'exigent pas que les données du cache L1 résident également dans le cache L2, bien que cela soit souvent le cas. Il n'existe pas de nom universellement accepté pour cette politique intermédiaire ; deux appellations courantes sont « non exclusif » et « partiellement inclusif ».L’avantage des caches exclusifs réside dans leur capacité de stockage supérieure. Cet avantage est plus marqué lorsque le cache L1 exclusif est comparable au cache L2, et diminue si le cache L2 est beaucoup plus grand que le cache L1. En cas d’échec d’accès dans le cache L1 et de succès dans le cache L2, la ligne correspondante dans le cache L2 est échangée avec une ligne du cache L1. Cet échange est beaucoup plus complexe que la simple copie d’une ligne du cache L2 vers le cache L1, opération effectuée par un cache inclusif.
L'un des avantages des caches strictement inclusifs est que, lorsqu'un périphérique externe ou un autre processeur d'un système multiprocesseur souhaite supprimer une ligne de cache du processeur, il suffit que ce dernier consulte le cache L2. Dans les hiérarchies de caches n'imposant pas l'inclusion, le cache L1 doit également être consulté. En revanche, il existe une corrélation entre les associativités des caches L1 et L2 : si le cache L2 ne possède pas au moins autant de voies que l'ensemble des caches L1, l'associativité effective de ces derniers est limitée. Un autre inconvénient des caches inclusifs est que, lors de toute éviction dans le cache L2, les lignes (potentiellement) correspondantes dans le cache L1 doivent également être évincées afin de maintenir l'inclusivité. Cette opération est conséquente et entraîne un taux d'échecs de cache L1 plus élevé.
Un autre avantage des caches inclusifs est que le cache principal peut utiliser des lignes de cache plus larges, ce qui réduit la taille des étiquettes du cache secondaire. (Les caches exclusifs exigent que les deux caches aient des lignes de cache de même taille, afin que les lignes puissent être permutées en cas d'échec de cache L1 et de succès de cache L2.) Si le cache secondaire est dix fois plus grand que le cache principal, et que les données du cache sont dix fois plus grandes que les étiquettes de cache, la surface d'étiquettes ainsi économisée peut être comparable à la surface incrémentale nécessaire pour stocker les données du cache L1 dans le cache L2.
Mémoire du bloc-notes
La mémoire scratchpad (SPM), également connue sous le nom de mémoire scratchpad, mémoire RAM scratchpad ou mémoire locale dans la terminologie informatique, est une mémoire interne à haute vitesse utilisée pour le stockage temporaire de calculs, de données et d'autres travaux en cours.Exemple : le K8
Pour illustrer à la fois la spécialisation et la mise en cache multiniveau, voici la hiérarchie de cache du cœur K8 du processeur AMD Athlon 64.
Hiérarchie du cache du cœur K8 du processeur AMD Athlon 64 Le K8 possède quatre caches spécialisés : un cache d’instructions, un TLB d’instructions , un TLB de données et un cache de données. Chacun de ces caches est spécialisé :
- Le cache d'instructions conserve des copies de lignes de mémoire de 64 octets et en extrait 16 à chaque cycle. Chaque octet de ce cache est stocké sur dix bits au lieu de huit, les bits supplémentaires marquant les limites des instructions (il s'agit d'un exemple de prédécodage). Le cache utilise uniquement la parité plutôt que la correction d'erreurs (ECC ), car la parité est plus petite et toute donnée corrompue peut être remplacée par des données fraîches extraites de la mémoire (qui contient toujours une copie à jour des instructions).
- Le TLB d'instructions conserve des copies des entrées de table des pages (PTE). À chaque cycle, l'adresse virtuelle de chaque instruction est traduite par ce TLB en une adresse physique. Chaque entrée occupe quatre ou huit octets en mémoire. Le K8 ayant une taille de page variable, chaque TLB est divisé en deux sections : l'une pour les PTE correspondant à des pages de 4 Kio, l'autre pour celles correspondant à des pages de 4 Mio ou 2 Mio. Cette division simplifie le circuit d'association dans chaque section. Le système d'exploitation associe des PTE de tailles différentes aux différentes sections de l'espace d'adressage virtuel.
- Le TLB de données possède deux copies contenant des entrées identiques. Ces deux copies permettent deux accès aux données par cycle pour traduire les adresses virtuelles en adresses physiques. À l'instar du TLB d'instructions, ce TLB est divisé en deux types d'entrées.
- Le cache de données conserve des copies de lignes de mémoire de 64 octets. Il est divisé en 8 banques (chacune stockant 8 Kio de données) et peut accéder à deux ensembles de données de 8 octets par cycle, à condition qu'ils se trouvent dans des banques différentes. Il existe deux copies des étiquettes, car chaque ligne de 64 octets est répartie entre les huit banques. Chaque copie d'étiquette gère l'un des deux accès par cycle.
Le K8 dispose également de caches à plusieurs niveaux. Il existe des TLB d'instructions et de données de second niveau, qui stockent uniquement des entrées de table de pages (PTE) mappant 4 KiB. Les caches d'instructions et de données, ainsi que les différents TLB, peuvent être alimentés par le vaste cache L2 unifié . Ce cache est exclusif aux caches d'instructions et de données L1, ce qui signifie que toute ligne de 8 octets ne peut se trouver que dans l'un des caches suivants : le cache d'instructions L1, le cache de données L1 ou le cache L2. Il est toutefois possible qu'une ligne du cache de données contienne une PTE présente également dans l'un des TLB ; le système d'exploitation assure la cohérence des TLB en vidant certaines portions de ces derniers lors de la mise à jour des tables de pages en mémoire.
Le K8 met également en cache des informations qui ne sont jamais stockées en mémoire : les informations de prédiction. Ces caches ne sont pas représentés sur le schéma ci-dessus. Comme c'est souvent le cas pour ce type de processeur, le K8 dispose d'une prédiction de branchement assez complexe , avec des tables permettant de prédire si des branchements seront effectués et d'autres tables prédisant les cibles des branchements et des sauts. Certaines de ces informations sont associées aux instructions, à la fois dans le cache d'instructions de niveau 1 et dans le cache secondaire unifié.
Le K8 utilise une astuce ingénieuse pour stocker les informations de prédiction avec les instructions dans le cache secondaire. Les lignes de ce cache sont protégées contre toute corruption accidentelle de données (par exemple, suite à l'impact d'une particule alpha ) par un système de correction d'erreurs (ECC) ou par parité , selon qu'elles proviennent du cache principal de données ou d'instructions. Le code de parité occupant moins de bits que le code ECC, les lignes du cache d'instructions disposent de quelques bits supplémentaires. Ces bits servent à stocker les informations de prédiction de branchement associées à ces instructions. Il en résulte un historique de branchement plus étendu pour le prédicteur de branchement, et donc une meilleure précision.
Plus de hiérarchies
D'autres processeurs disposent d'autres types de prédicteurs (par exemple, le prédicteur de contournement de stockage à chargement dans le DEC Alpha 21264 ).
Ces prédicteurs sont des caches, car ils stockent des informations dont le calcul est coûteux. Certains termes employés pour parler des prédicteurs sont les mêmes que ceux utilisés pour les caches (on parle par exemple de « succès » dans un prédicteur de branchement), mais les prédicteurs ne sont généralement pas considérés comme faisant partie de la hiérarchie des caches.
Le K8 assure la cohérence matérielle des caches d'instructions et de données, ce qui signifie qu'une instruction de stockage effectuée juste après une autre modifiera l'instruction suivante. D'autres processeurs, comme ceux des familles Alpha et MIPS, s'appuient sur le logiciel pour maintenir la cohérence du cache d'instructions. L'affichage des instructions de stockage dans le flux d'instructions n'est garanti que lorsqu'un programme appelle une fonction du système d'exploitation pour assurer cette cohérence.
Étiquette RAM
Tag RAM sur la carte d'un Intel Pentium III En génie informatique, une mémoire RAM étiquetée permet de spécifier quelle adresse mémoire est actuellement stockée dans le cache du processeur. Pour une conception simple à correspondance directe, une SRAM rapide peut être utilisée. Les caches associatifs de niveau supérieur utilisent généralement une mémoire adressable par contenu .
Mise en œuvre
Chemin de lecture pour un cache associatif à deux voies Le schéma ci-contre vise à clarifier l'utilisation des différents champs de l'adresse. Le bit 31 est le plus significatif, le bit 0 le moins significatif. Ce schéma représente les SRAM, l'indexation et le multiplexage d'un cache de 4 Kio, associatif par ensembles à deux voies, indexé et étiqueté virtuellement, avec des lignes de 64 octets (B), une largeur de lecture de 32 bits et une adresse virtuelle de 32 bits.
Le cache ayant une capacité de 4 KiB et comportant 64 lignes d'octets, il ne contient que 64 lignes. La lecture s'effectue par paires à partir d'une SRAM d'étiquettes de 32 lignes, chacune associée à une paire d'étiquettes de 21 bits. Bien que toute fonction des bits d'adresse virtuelle 31 à 6 puisse être utilisée pour indexer les SRAM d'étiquettes et de données, l'utilisation des bits de poids faible est plus simple.
De même, étant donné que le cache fait 4 KiB et possède un chemin de lecture de 4 B, et qu'il lit de deux manières pour chaque accès, la SRAM de données comporte 512 lignes de 8 octets de large.
Un cache plus moderne pourrait avoir une capacité de 16 Kio, être associatif par ensembles à 4 voies, indexé virtuellement, avec des indications virtuelles et un marquage physique, avec des lignes de 32 octets, une largeur de lecture de 32 bits et des adresses physiques de 36 bits. Le chemin de lecture pour un tel cache est très similaire à celui décrit précédemment. Au lieu d'étiquettes, ce sont des indications virtuelles qui sont lues et comparées à un sous-ensemble de l'adresse virtuelle. Plus tard dans le pipeline, l'adresse virtuelle est traduite en adresse physique par le TLB, et l'étiquette physique correspondante est lue (une seule, car l'indication virtuelle indique le sens de lecture dans le cache). Enfin, l'adresse physique est comparée à l'étiquette physique pour déterminer si une correspondance a été trouvée.
Certaines conceptions SPARC ont amélioré la vitesse de leurs caches L1 de quelques délais de porte en intégrant l'additionneur d'adresses virtuelles dans les décodeurs SRAM.aux registres . Mais depuis les années 1980 l'écart de performance entre le processeur et la mémoire n'a cessé de se creuser. Les microprocesseurs ont progressé beaucoup plus vite que la mémoire, notamment en termes de fréquence de fonctionnement , faisant de cette dernière un goulot d'étranglement. S'il était techniquement possible d'avoir une mémoire principale aussi rapide que le processeur, une solution plus économique a été privilégiée : utiliser une grande quantité de mémoire basse vitesse, tout en intégrant une petite mémoire cache haute vitesse pour compenser l'écart de performance. Cette approche a permis d'obtenir une capacité dix fois supérieure – pour un coût identique – avec une légère diminution des performances globales.
Premières implémentations TLB
Les premières utilisations documentées d'un TLB ont eu lieu sur le GE 645 et l' IBM 360/67 , qui utilisaient tous deux une mémoire associative comme TLB.
Cache de première instruction
La première utilisation documentée d'un cache d'instructions a eu lieu sur le CDC 6600.
Premier cache de données
La première utilisation documentée d'un cache de données a eu lieu sur le système IBM System/360 modèle 85.
Dans les microprocesseurs 68k
Le 68010 , sorti en 1982, dispose d'un « mode boucle » pouvant être considéré comme un cache d'instructions réduit et spécifique, accélérant les boucles composées de seulement deux instructions. Le 68020 , sorti en 1984, a remplacé ce mode par un cache d'instructions classique de 256 octets, devenant ainsi le premier processeur de la série 68k à intégrer une véritable mémoire cache sur puce.
Le 68030 , sorti en 1987, est essentiellement un cœur 68020 avec un cache de données supplémentaire de 256 octets, une unité de gestion de la mémoire sur puce (MMU), une réduction de processus et un mode rafale ajouté pour les caches.
Le 68040 , sorti en 1990, possède des caches d'instructions et de données séparés de quatre kilo-octets chacun.
Le 68060 , sorti en 1994, possède les éléments suivants : cache de données de 8 KiB (associatif à quatre voies), cache d'instructions de 8 KiB (associatif à quatre voies), tampon d'instructions FIFO de 96 octets, cache de branchement de 256 entrées et tampon MMU de cache de traduction d'adresses de 64 entrées (associatif à quatre voies).
Dans les microprocesseurs x86
Exemple de carte mère avec un microprocesseur i386 (33 MHz), 64 KiB de cache (25 ns ; 8 puces dans le coin inférieur gauche), 2 Mio de DRAM (70 ns ; 8 SIMM à droite du cache) et un contrôleur de cache ( Austek A38202 ; à droite du processeur). Avec l'arrivée des microprocesseurs x86 à des fréquences d'horloge de 20 MHz et plus (notamment l' A386) , de petites quantités de mémoire cache rapide ont commencé à être intégrées aux systèmes pour améliorer leurs performances. En effet, la DRAM utilisée comme mémoire principale présentait une latence importante, pouvant atteindre 120 ns, ainsi que des cycles de rafraîchissement. Le cache était constitué de cellules de mémoire SRAM , plus coûteuses mais nettement plus rapides, dont la latence était alors de l'ordre de 10 à 25 ns. Les premiers caches étaient externes au processeur et généralement situés sur la carte mère sous la forme de huit ou neuf composants DIP insérés dans des supports, permettant ainsi d'ajouter le cache en option ou de l'étendre.
Certaines versions du processeur Intel 386 pouvaient prendre en charge de 16 à 256 KiB de cache externe.
Avec le processeur 486 , un cache de 8 Kio était intégré directement à la puce. Ce cache était appelé cache de niveau 1 (L1) pour le différencier du cache de niveau 2 (L2), plus lent et situé sur la carte mère. Ces derniers étaient beaucoup plus volumineux, la taille la plus courante étant de 256 Kio. Certaines cartes mères disposaient d'emplacements pour la carte fille Intel 485Turbocache , dotée de 64 ou 128 Ko de mémoire cache. La popularité du cache sur carte mère s'est maintenue durant l' ère Pentium MMX , mais a été rendue obsolète par l'introduction de la SDRAM et l'écart croissant entre les fréquences d'horloge du bus et du processeur, ce qui a fait que le cache sur carte mère n'était plus que légèrement plus rapide que la mémoire principale.
L'évolution suivante en matière d'implémentation de cache dans les microprocesseurs x86 a commencé avec le Pentium Pro , qui a intégré le cache secondaire dans le même boîtier que le microprocesseur, cadencé à la même fréquence que ce dernier.
Les caches intégrés à la carte mère ont longtemps bénéficié d'une grande popularité grâce aux processeurs AMD K6-2 et AMD K6-III , qui utilisaient encore le socket 7 , précédemment employé par Intel avec des caches intégrés. Le K6-III intégrait 256 Kio de cache L2 et exploitait le cache intégré comme cache de troisième niveau, appelé L3 (des cartes mères avec jusqu'à 2 Mio de cache intégré ont été produites). Après l'obsolescence du socket 7, le cache intégré à la carte mère a disparu des systèmes x86.
Les caches à trois niveaux ont été réutilisés pour la première fois avec l'introduction du processeur Intel Xeon MP « Foster Core » , où le cache L3 a été ajouté à la puce du processeur. Il est devenu courant que la taille totale du cache augmente avec les nouvelles générations de processeurs, et récemment (en 2011), il n'est pas rare de trouver des caches de niveau 3 de plusieurs dizaines de mégaoctets
Intel a introduit un cache de niveau 4 intégré avec la microarchitecture Haswell . Les processeurs Crystalwell Haswell, équipés de la variante GT3e du processeur graphique intégré Intel Iris Pro, disposent de 128 Mio de mémoire DRAM embarquée ( eDRAM ) sur le même boîtier. Ce cache L4 est partagé dynamiquement entre le GPU et le CPU intégrés, et sert de cache victime au cache L3 du CPU.
Dans les microprocesseurs ARM
Le processeur Apple M1 dispose de 128 ou 192 Kio de cache d'instructions L1 par cœur (important pour la latence et les performances monocœur), selon le type de cœur. Il s'agit d'un cache L1 exceptionnellement important pour un processeur (et pas seulement pour un ordinateur portable). La taille totale de la mémoire cache n'est pas particulièrement élevée pour un ordinateur portable (c'est le total qui importe le plus pour le débit), et des tailles totales bien supérieures (par exemple, L3 ou L4) sont disponibles sur les ordinateurs centraux IBM.
Recherches actuelles
Les premières conceptions de cache se concentraient exclusivement sur le coût direct du cache et de la RAM , ainsi que sur la vitesse d'exécution moyenne. Les conceptions de cache plus récentes prennent également en compte l'efficacité énergétique , la tolérance aux pannes et d'autres objectifs.
Plusieurs outils sont à la disposition des architectes informatiques pour les aider à explorer les compromis entre le temps de cycle du cache, l'énergie et la surface ; le simulateur de cache CACTI et le simulateur de jeu d'instructions SimpleScalar sont deux options open-source.
Cache multiport
Un cache multiport est un cache capable de traiter plusieurs requêtes simultanément. Alors qu'un cache traditionnel utilise généralement une seule adresse mémoire, un cache multiport peut permettre de demander N adresses à la fois, N étant le nombre de ports connectés entre le processeur et le cache. L'avantage est qu'un processeur pipeliné peut accéder à la mémoire depuis différentes phases de son pipeline. Autre avantage : il rend possible le concept de processeurs superscalaires grâce à différents niveaux de cache.
Plus d articles de Worldlex Wiki
Revenez a l index pour explorer davantage de pages sur l histoire, la science, la culture, la geographie et la societe en francais.
Explorer l index
Mémoire du bloc-notes
Exemple : le K8
Pour illustrer à la fois la spécialisation et la mise en cache multiniveau, voici la hiérarchie de cache du cœur K8 du processeur AMD Athlon 64.
Le K8 possède quatre caches spécialisés : un cache d’instructions, un TLB d’instructions , un TLB de données et un cache de données. Chacun de ces caches est spécialisé :
- Le cache d'instructions conserve des copies de lignes de mémoire de 64 octets et en extrait 16 à chaque cycle. Chaque octet de ce cache est stocké sur dix bits au lieu de huit, les bits supplémentaires marquant les limites des instructions (il s'agit d'un exemple de prédécodage). Le cache utilise uniquement la parité plutôt que la correction d'erreurs (ECC ), car la parité est plus petite et toute donnée corrompue peut être remplacée par des données fraîches extraites de la mémoire (qui contient toujours une copie à jour des instructions).
- Le TLB d'instructions conserve des copies des entrées de table des pages (PTE). À chaque cycle, l'adresse virtuelle de chaque instruction est traduite par ce TLB en une adresse physique. Chaque entrée occupe quatre ou huit octets en mémoire. Le K8 ayant une taille de page variable, chaque TLB est divisé en deux sections : l'une pour les PTE correspondant à des pages de 4 Kio, l'autre pour celles correspondant à des pages de 4 Mio ou 2 Mio. Cette division simplifie le circuit d'association dans chaque section. Le système d'exploitation associe des PTE de tailles différentes aux différentes sections de l'espace d'adressage virtuel.
- Le TLB de données possède deux copies contenant des entrées identiques. Ces deux copies permettent deux accès aux données par cycle pour traduire les adresses virtuelles en adresses physiques. À l'instar du TLB d'instructions, ce TLB est divisé en deux types d'entrées.
- Le cache de données conserve des copies de lignes de mémoire de 64 octets. Il est divisé en 8 banques (chacune stockant 8 Kio de données) et peut accéder à deux ensembles de données de 8 octets par cycle, à condition qu'ils se trouvent dans des banques différentes. Il existe deux copies des étiquettes, car chaque ligne de 64 octets est répartie entre les huit banques. Chaque copie d'étiquette gère l'un des deux accès par cycle.
Le K8 dispose également de caches à plusieurs niveaux. Il existe des TLB d'instructions et de données de second niveau, qui stockent uniquement des entrées de table de pages (PTE) mappant 4 KiB. Les caches d'instructions et de données, ainsi que les différents TLB, peuvent être alimentés par le vaste cache L2 unifié . Ce cache est exclusif aux caches d'instructions et de données L1, ce qui signifie que toute ligne de 8 octets ne peut se trouver que dans l'un des caches suivants : le cache d'instructions L1, le cache de données L1 ou le cache L2. Il est toutefois possible qu'une ligne du cache de données contienne une PTE présente également dans l'un des TLB ; le système d'exploitation assure la cohérence des TLB en vidant certaines portions de ces derniers lors de la mise à jour des tables de pages en mémoire.
Le K8 met également en cache des informations qui ne sont jamais stockées en mémoire : les informations de prédiction. Ces caches ne sont pas représentés sur le schéma ci-dessus. Comme c'est souvent le cas pour ce type de processeur, le K8 dispose d'une prédiction de branchement assez complexe , avec des tables permettant de prédire si des branchements seront effectués et d'autres tables prédisant les cibles des branchements et des sauts. Certaines de ces informations sont associées aux instructions, à la fois dans le cache d'instructions de niveau 1 et dans le cache secondaire unifié.
Le K8 utilise une astuce ingénieuse pour stocker les informations de prédiction avec les instructions dans le cache secondaire. Les lignes de ce cache sont protégées contre toute corruption accidentelle de données (par exemple, suite à l'impact d'une particule alpha ) par un système de correction d'erreurs (ECC) ou par parité , selon qu'elles proviennent du cache principal de données ou d'instructions. Le code de parité occupant moins de bits que le code ECC, les lignes du cache d'instructions disposent de quelques bits supplémentaires. Ces bits servent à stocker les informations de prédiction de branchement associées à ces instructions. Il en résulte un historique de branchement plus étendu pour le prédicteur de branchement, et donc une meilleure précision.
Plus de hiérarchies
D'autres processeurs disposent d'autres types de prédicteurs (par exemple, le prédicteur de contournement de stockage à chargement dans le DEC Alpha 21264 ).
Ces prédicteurs sont des caches, car ils stockent des informations dont le calcul est coûteux. Certains termes employés pour parler des prédicteurs sont les mêmes que ceux utilisés pour les caches (on parle par exemple de « succès » dans un prédicteur de branchement), mais les prédicteurs ne sont généralement pas considérés comme faisant partie de la hiérarchie des caches.
Le K8 assure la cohérence matérielle des caches d'instructions et de données, ce qui signifie qu'une instruction de stockage effectuée juste après une autre modifiera l'instruction suivante. D'autres processeurs, comme ceux des familles Alpha et MIPS, s'appuient sur le logiciel pour maintenir la cohérence du cache d'instructions. L'affichage des instructions de stockage dans le flux d'instructions n'est garanti que lorsqu'un programme appelle une fonction du système d'exploitation pour assurer cette cohérence.
Étiquette RAM
En génie informatique, une mémoire RAM étiquetée permet de spécifier quelle adresse mémoire est actuellement stockée dans le cache du processeur. Pour une conception simple à correspondance directe, une SRAM rapide peut être utilisée. Les caches associatifs de niveau supérieur utilisent généralement une mémoire adressable par contenu .
Mise en œuvre
Le schéma ci-contre vise à clarifier l'utilisation des différents champs de l'adresse. Le bit 31 est le plus significatif, le bit 0 le moins significatif. Ce schéma représente les SRAM, l'indexation et le multiplexage d'un cache de 4 Kio, associatif par ensembles à deux voies, indexé et étiqueté virtuellement, avec des lignes de 64 octets (B), une largeur de lecture de 32 bits et une adresse virtuelle de 32 bits.
Le cache ayant une capacité de 4 KiB et comportant 64 lignes d'octets, il ne contient que 64 lignes. La lecture s'effectue par paires à partir d'une SRAM d'étiquettes de 32 lignes, chacune associée à une paire d'étiquettes de 21 bits. Bien que toute fonction des bits d'adresse virtuelle 31 à 6 puisse être utilisée pour indexer les SRAM d'étiquettes et de données, l'utilisation des bits de poids faible est plus simple.
De même, étant donné que le cache fait 4 KiB et possède un chemin de lecture de 4 B, et qu'il lit de deux manières pour chaque accès, la SRAM de données comporte 512 lignes de 8 octets de large.
Un cache plus moderne pourrait avoir une capacité de 16 Kio, être associatif par ensembles à 4 voies, indexé virtuellement, avec des indications virtuelles et un marquage physique, avec des lignes de 32 octets, une largeur de lecture de 32 bits et des adresses physiques de 36 bits. Le chemin de lecture pour un tel cache est très similaire à celui décrit précédemment. Au lieu d'étiquettes, ce sont des indications virtuelles qui sont lues et comparées à un sous-ensemble de l'adresse virtuelle. Plus tard dans le pipeline, l'adresse virtuelle est traduite en adresse physique par le TLB, et l'étiquette physique correspondante est lue (une seule, car l'indication virtuelle indique le sens de lecture dans le cache). Enfin, l'adresse physique est comparée à l'étiquette physique pour déterminer si une correspondance a été trouvée.
Certaines conceptions SPARC ont amélioré la vitesse de leurs caches L1 de quelques délais de porte en intégrant l'additionneur d'adresses virtuelles dans les décodeurs SRAM.aux registres . Mais depuis les années 1980 l'écart de performance entre le processeur et la mémoire n'a cessé de se creuser. Les microprocesseurs ont progressé beaucoup plus vite que la mémoire, notamment en termes de fréquence de fonctionnement , faisant de cette dernière un goulot d'étranglement. S'il était techniquement possible d'avoir une mémoire principale aussi rapide que le processeur, une solution plus économique a été privilégiée : utiliser une grande quantité de mémoire basse vitesse, tout en intégrant une petite mémoire cache haute vitesse pour compenser l'écart de performance. Cette approche a permis d'obtenir une capacité dix fois supérieure – pour un coût identique – avec une légère diminution des performances globales.
Premières implémentations TLB
Les premières utilisations documentées d'un TLB ont eu lieu sur le GE 645 et l' IBM 360/67 , qui utilisaient tous deux une mémoire associative comme TLB.
Cache de première instruction
La première utilisation documentée d'un cache d'instructions a eu lieu sur le CDC 6600.
Premier cache de données
La première utilisation documentée d'un cache de données a eu lieu sur le système IBM System/360 modèle 85.
Dans les microprocesseurs 68k
Le 68010 , sorti en 1982, dispose d'un « mode boucle » pouvant être considéré comme un cache d'instructions réduit et spécifique, accélérant les boucles composées de seulement deux instructions. Le 68020 , sorti en 1984, a remplacé ce mode par un cache d'instructions classique de 256 octets, devenant ainsi le premier processeur de la série 68k à intégrer une véritable mémoire cache sur puce.
Le 68030 , sorti en 1987, est essentiellement un cœur 68020 avec un cache de données supplémentaire de 256 octets, une unité de gestion de la mémoire sur puce (MMU), une réduction de processus et un mode rafale ajouté pour les caches.
Le 68040 , sorti en 1990, possède des caches d'instructions et de données séparés de quatre kilo-octets chacun.
Le 68060 , sorti en 1994, possède les éléments suivants : cache de données de 8 KiB (associatif à quatre voies), cache d'instructions de 8 KiB (associatif à quatre voies), tampon d'instructions FIFO de 96 octets, cache de branchement de 256 entrées et tampon MMU de cache de traduction d'adresses de 64 entrées (associatif à quatre voies).
Dans les microprocesseurs x86
Avec l'arrivée des microprocesseurs x86 à des fréquences d'horloge de 20 MHz et plus (notamment l' A386) , de petites quantités de mémoire cache rapide ont commencé à être intégrées aux systèmes pour améliorer leurs performances. En effet, la DRAM utilisée comme mémoire principale présentait une latence importante, pouvant atteindre 120 ns, ainsi que des cycles de rafraîchissement. Le cache était constitué de cellules de mémoire SRAM , plus coûteuses mais nettement plus rapides, dont la latence était alors de l'ordre de 10 à 25 ns. Les premiers caches étaient externes au processeur et généralement situés sur la carte mère sous la forme de huit ou neuf composants DIP insérés dans des supports, permettant ainsi d'ajouter le cache en option ou de l'étendre.
Certaines versions du processeur Intel 386 pouvaient prendre en charge de 16 à 256 KiB de cache externe.
Avec le processeur 486 , un cache de 8 Kio était intégré directement à la puce. Ce cache était appelé cache de niveau 1 (L1) pour le différencier du cache de niveau 2 (L2), plus lent et situé sur la carte mère. Ces derniers étaient beaucoup plus volumineux, la taille la plus courante étant de 256 Kio. Certaines cartes mères disposaient d'emplacements pour la carte fille Intel 485Turbocache , dotée de 64 ou 128 Ko de mémoire cache. La popularité du cache sur carte mère s'est maintenue durant l' ère Pentium MMX , mais a été rendue obsolète par l'introduction de la SDRAM et l'écart croissant entre les fréquences d'horloge du bus et du processeur, ce qui a fait que le cache sur carte mère n'était plus que légèrement plus rapide que la mémoire principale.
L'évolution suivante en matière d'implémentation de cache dans les microprocesseurs x86 a commencé avec le Pentium Pro , qui a intégré le cache secondaire dans le même boîtier que le microprocesseur, cadencé à la même fréquence que ce dernier.
Les caches intégrés à la carte mère ont longtemps bénéficié d'une grande popularité grâce aux processeurs AMD K6-2 et AMD K6-III , qui utilisaient encore le socket 7 , précédemment employé par Intel avec des caches intégrés. Le K6-III intégrait 256 Kio de cache L2 et exploitait le cache intégré comme cache de troisième niveau, appelé L3 (des cartes mères avec jusqu'à 2 Mio de cache intégré ont été produites). Après l'obsolescence du socket 7, le cache intégré à la carte mère a disparu des systèmes x86.
Les caches à trois niveaux ont été réutilisés pour la première fois avec l'introduction du processeur Intel Xeon MP « Foster Core » , où le cache L3 a été ajouté à la puce du processeur. Il est devenu courant que la taille totale du cache augmente avec les nouvelles générations de processeurs, et récemment (en 2011), il n'est pas rare de trouver des caches de niveau 3 de plusieurs dizaines de mégaoctets
Intel a introduit un cache de niveau 4 intégré avec la microarchitecture Haswell . Les processeurs Crystalwell Haswell, équipés de la variante GT3e du processeur graphique intégré Intel Iris Pro, disposent de 128 Mio de mémoire DRAM embarquée ( eDRAM ) sur le même boîtier. Ce cache L4 est partagé dynamiquement entre le GPU et le CPU intégrés, et sert de cache victime au cache L3 du CPU.
Dans les microprocesseurs ARM
Le processeur Apple M1 dispose de 128 ou 192 Kio de cache d'instructions L1 par cœur (important pour la latence et les performances monocœur), selon le type de cœur. Il s'agit d'un cache L1 exceptionnellement important pour un processeur (et pas seulement pour un ordinateur portable). La taille totale de la mémoire cache n'est pas particulièrement élevée pour un ordinateur portable (c'est le total qui importe le plus pour le débit), et des tailles totales bien supérieures (par exemple, L3 ou L4) sont disponibles sur les ordinateurs centraux IBM.
Recherches actuelles
Les premières conceptions de cache se concentraient exclusivement sur le coût direct du cache et de la RAM , ainsi que sur la vitesse d'exécution moyenne. Les conceptions de cache plus récentes prennent également en compte l'efficacité énergétique , la tolérance aux pannes et d'autres objectifs.
Plusieurs outils sont à la disposition des architectes informatiques pour les aider à explorer les compromis entre le temps de cycle du cache, l'énergie et la surface ; le simulateur de cache CACTI et le simulateur de jeu d'instructions SimpleScalar sont deux options open-source.
Cache multiport
Un cache multiport est un cache capable de traiter plusieurs requêtes simultanément. Alors qu'un cache traditionnel utilise généralement une seule adresse mémoire, un cache multiport peut permettre de demander N adresses à la fois, N étant le nombre de ports connectés entre le processeur et le cache. L'avantage est qu'un processeur pipeliné peut accéder à la mémoire depuis différentes phases de son pipeline. Autre avantage : il rend possible le concept de processeurs superscalaires grâce à différents niveaux de cache.
Revenez a l index pour explorer davantage de pages sur l histoire, la science, la culture, la geographie et la societe en francais.Plus d articles de Worldlex Wiki