
L'accès non uniforme à la mémoire ( NUMA ) est une architecture de mémoire utilisée en multiprocesseur , où le temps d'accès à la mémoire dépend de son emplacement par rapport au processeur. En NUMA, un processeur accède plus rapidement à sa propre mémoire locale qu'à la mémoire non locale (mémoire locale à un autre processeur ou mémoire partagée entre processeurs). NUMA est avantageux pour les charges de travail présentant une forte localité de référence mémoire et une faible contention de verrouillage , car un processeur peut opérer sur un sous-ensemble de mémoire situé principalement ou entièrement dans son propre nœud de cache, réduisant ainsi le trafic sur le bus mémoire.
Les architectures NUMA succèdent logiquement, en termes de mise à l'échelle, aux architectures multiprocesseurs symétriques (SMP). Elles ont été développées commercialement dans les années 1990 par Unisys , Convex Computer (devenue Hewlett-Packard ), Honeywell Information Systems Italy (HISI) (devenue Groupe Bull ), Silicon Graphics (devenue Silicon Graphics International ), Sequent Computer Systems (devenue IBM ), Data General (devenue EMC , puis Dell Technologies ), Digital (devenue Compaq , puis HP , puis HPE ) et ICL . Les techniques développées par ces entreprises ont ensuite été intégrées à divers systèmes d'exploitation de type Unix , et dans une certaine mesure à Windows NT .
La première implémentation commerciale d'un système Unix basé sur NUMA fut la famille de serveurs Symmetrical Multi Processing XPS-100, conçue par Dan Gielan de VAST Corporation pour Honeywell Information Systems Italy.
Les processeurs modernes fonctionnent beaucoup plus rapidement que la mémoire vive qu'ils utilisent. Aux débuts de l'informatique et du traitement des données, le processeur était généralement plus lent que sa propre mémoire. Les performances respectives des processeurs et de la mémoire se sont croisées dans les années 1960 avec l'avènement des premiers supercalculateurs . Depuis, les processeurs se retrouvent de plus en plus souvent confrontés à une pénurie de données et sont contraints de patienter en attendant l'arrivée des données depuis la mémoire (par exemple, pour les ordinateurs basés sur l'architecture de Von Neumann , voir le goulot d'étranglement de Von Neumann ). De nombreuses conceptions de supercalculateurs des années 1980 et 1990 privilégiaient un accès mémoire rapide plutôt que des processeurs plus performants, permettant ainsi à ces ordinateurs de traiter d'importants volumes de données à des vitesses inaccessibles aux autres systèmes.
Limiter le nombre d'accès à la mémoire a été essentiel pour obtenir des performances élevées des ordinateurs modernes. Pour les processeurs grand public, cela impliquait d'installer une quantité toujours croissante de mémoire cache à haute vitesse et d'utiliser des algorithmes de plus en plus sophistiqués pour éviter les défauts de cache . Cependant, l'augmentation considérable de la taille des systèmes d'exploitation et des applications qui y sont exécutées a généralement rendu obsolètes ces améliorations du traitement du cache. Les systèmes multiprocesseurs sans NUMA aggravent considérablement le problème. Un système peut alors saturer la mémoire de plusieurs processeurs simultanément, notamment parce qu'un seul processeur peut accéder à la mémoire de l'ordinateur à la fois.
L'architecture NUMA tente de résoudre ce problème en fournissant une mémoire distincte à chaque processeur, évitant ainsi la perte de performance liée à l'accès simultané à la même zone mémoire par plusieurs processeurs. Pour les problèmes impliquant des données réparties (fréquents pour les serveurs et les applications similaires), NUMA peut améliorer les performances par rapport à une mémoire partagée unique, d'un facteur approximativement égal au nombre de processeurs (ou de banques de mémoire distinctes). Une autre approche consiste à utiliser l' architecture de mémoire multicanaux , dans laquelle une augmentation linéaire du nombre de canaux mémoire accroît linéairement la concurrence d'accès à la mémoire.
Bien entendu, les données ne sont pas toutes confinées à une seule tâche, ce qui signifie que plusieurs processeurs peuvent avoir besoin des mêmes données. Pour gérer ces cas, les systèmes NUMA intègrent du matériel ou des logiciels supplémentaires permettant de déplacer les données entre les banques de mémoire. Cette opération ralentit les processeurs associés à ces banques ; par conséquent, le gain de vitesse global apporté par NUMA dépend fortement de la nature des tâches exécutées.
Mises en œuvre
AMD a implémenté l'architecture NUMA avec son processeur Opteron (2003), en utilisant HyperTransport . Intel a annoncé la compatibilité NUMA pour ses serveurs x86 et Itanium fin 2007 avec ses processeurs Nehalem et Tukwila . Les deux familles de processeurs Intel partagent un chipset commun ; l'interconnexion, appelée Intel QuickPath Interconnect (QPI), offre une bande passante extrêmement élevée permettant une grande évolutivité embarquée et a été remplacée par une nouvelle version appelée Intel UltraPath Interconnect avec la sortie de Skylake (2017).
Cache NUMA cohérent (ccNUMA)
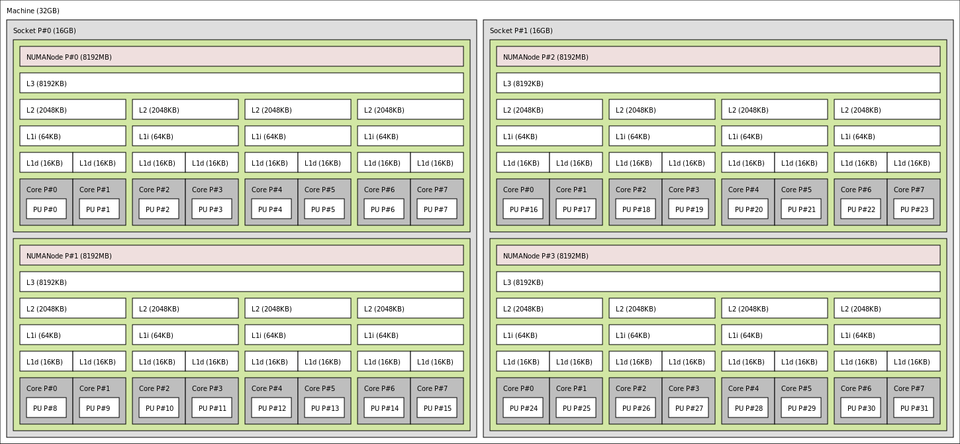
En règle générale, l'architecture ccNUMA utilise la communication interprocesseur entre les contrôleurs de cache pour maintenir une image mémoire cohérente lorsque plusieurs caches stockent la même adresse mémoire. De ce fait, les performances de ccNUMA peuvent être médiocres lorsque plusieurs processeurs tentent d'accéder à la même zone mémoire successivement. La prise en charge de NUMA par les systèmes d'exploitation vise à réduire la fréquence de ce type d'accès en allouant les processeurs et la mémoire de manière compatible avec NUMA et en évitant les algorithmes d'ordonnancement et de verrouillage qui rendent nécessaires des accès incompatibles avec NUMA.
Par ailleurs, des protocoles de cohérence de cache tels que le protocole MESIF tentent de réduire les communications nécessaires au maintien de la cohérence du cache. L'interface de cohérence évolutive (SCI) est une norme IEEE définissant un protocole de cohérence de cache basé sur un répertoire afin d'éviter les limitations d'évolutivité rencontrées dans les anciens systèmes multiprocesseurs. Par exemple, SCI sert de base à la technologie NumaConnect.
NUMA vs. calcul en cluster
On peut considérer NUMA comme une forme de calcul en cluster étroitement couplée . L'ajout de la pagination de la mémoire virtuelle à une architecture de cluster permet d'implémenter NUMA entièrement par logiciel. Cependant, la latence inter-nœuds de NUMA logiciel reste plusieurs ordres de grandeur supérieure (plus lente) à celle de NUMA matériel.
Assistance logicielle
Étant donné que NUMA influence fortement les performances d'accès à la mémoire, certaines optimisations logicielles sont nécessaires pour permettre la planification des threads et des processus au plus près de leurs données en mémoire.
- Microsoft Windows 7 et Windows Server 2008 R2 ont ajouté la prise en charge de l'architecture NUMA sur plus de 64 cœurs logiques.
- Java 7 a ajouté la prise en charge de l'allocateur de mémoire et du ramasse-miettes compatibles NUMA .
- Noyau Linux :
- La version 2.5 offrait une prise en charge NUMA de base, qui a été améliorée dans les versions ultérieures du noyau.
- La version 3.8 du noyau Linux a introduit une nouvelle architecture NUMA qui a permis le développement de politiques NUMA plus efficaces dans les versions ultérieures du noyau.
- La version 3.13 du noyau Linux a introduit de nombreuses politiques visant à rapprocher un processus de sa mémoire, ainsi que la gestion de cas tels que le partage de pages mémoire entre processus ou l'utilisation de pages énormes transparentes ; de nouveaux paramètres sysctl permettent d'activer ou de désactiver l'équilibrage NUMA, ainsi que de configurer divers paramètres d'équilibrage de la mémoire NUMA.
- OpenSolaris modélise l'architecture NUMA avec des lgroups.
- FreeBSD a ajouté la prise en charge de l'architecture NUMA dans la version 9.0.
- La prise en charge de l'architecture ccNUMA sur les processeurs 1240 avec la série de serveurs Origin par Silicon Graphics IRIX (abandonnée en 2013) est terminée.
Support matériel
AMD Opteron , qui peut être implémenté sans logique externe, et sur le processeur Intel Itanium , qui nécessite un chipset compatible NUMA. Parmi les chipsets compatibles ccNUMA, on peut citer le SGI Shub (Super Hub), l'Intel E8870, le HP sx2000 (utilisé dans les serveurs Integrity et Superdome) et ceux présents dans les systèmes NEC basés sur Itanium. Les premiers systèmes ccNUMA, comme ceux de Silicon Graphics, étaient basés sur des processeurs MIPS et le processeur DEC Alpha 21364 (EV7).