| Carboniser | Fréquence | Code |
|---|---|---|
| espace | 7 | 111 |
| un | 4 | 010 |
| e | 4 | 000 |
| f | 3 | 1101 |
| h | 2 | 1010 |
| je | 2 | 1000 |
| m | 2 | 0111 |
| n | 2 | 0010 |
| s | 2 | 1011 |
| t | 2 | 0110 |
| l | 1 | 11001 |
| o | 1 | 00110 |
| p | 1 | 10011 |
| r | 1 | 11000 |
| vous | 1 | 00111 |
| x | 1 | 10010 |
En informatique et en théorie de l'information , un code de Huffman est un type particulier de code préfixe optimal couramment utilisé pour la compression de données sans perte . Le processus de recherche ou d'utilisation d'un tel code est le codage de Huffman , un algorithme développé par David A. Huffman lorsqu'il était doctorant au MIT , et publié en 1952 dans l'article « A Method for the Construction of Minimum-Redundancy Codes »
Le résultat de l'algorithme de Huffman peut être vu comme une table de codage à longueur variable permettant d'encoder un symbole source (tel qu'un caractère dans un fichier). L'algorithme construit cette table à partir de la probabilité ou de la fréquence d'occurrence estimée ( poids ) de chaque valeur possible du symbole source. Comme dans les autres méthodes de codage entropique , les symboles les plus fréquents sont généralement représentés par moins de bits que les symboles les moins fréquents. La méthode de Huffman peut être implémentée efficacement, trouvant un code en un temps linéaire par rapport au nombre de poids d'entrée si ces poids sont triés. Cependant, bien qu'optimale parmi les méthodes codant les symboles séparément, la méthode de Huffman n'est pas toujours optimale parmi toutes les méthodes de compression ; elle est remplacée par le codage arithmétique si un meilleur taux de compression est requis.
David A. Huffman et ses camarades du cours de théorie de l'information du MIT durent choisir entre un devoir et un examen final . Le professeur Robert M. Fano leur confia un devoir portant sur la recherche du code binaire le plus efficace. Huffman, incapable de démontrer qu'un code était le plus efficace, était sur le point d'abandonner et de commencer à réviser pour l'examen final lorsqu'il eut l'idée d'utiliser un arbre binaire trié par fréquence et démontra rapidement que cette méthode était la plus efficace.Ce faisant, Huffman a surpassé Fano, qui avait collaboré avec Claude Shannon à l'élaboration d'un code similaire. La construction de l'arbre de bas en haut garantissait l'optimalité, contrairement à l'approche descendante du codage de Shannon-Fano .
Terminologie
Le codage de Huffman utilise une méthode spécifique pour choisir la représentation de chaque symbole, ce qui donne un code préfixe (parfois appelé « code sans préfixe », c'est-à-dire que la chaîne binaire représentant un symbole particulier n'est jamais un préfixe de la chaîne binaire représentant un autre symbole). Le codage de Huffman est une méthode si répandue pour créer des codes préfixes que le terme « code de Huffman » est souvent utilisé comme synonyme de « code préfixe », même lorsqu'un tel code n'est pas produit par l'algorithme de Huffman.
Définition du problème
description informelle
- Donné
- Un ensemble de symboles et pour chaque symbole , la fréquence représentant la fraction de symboles dans le texte qui sont égaux à .
- Trouver
- Un code binaire sans préfixe (un ensemble de mots de code) avec une longueur de mot de code minimale attendue (de manière équivalente, un arbre avec une longueur de chemin pondérée minimale à partir de la racine ).
Description formalisée
Entrée . Alphabet , qui est l'alphabet des symboles de taille . Tuple , qui est le tuple des poids (positifs) des symboles (généralement proportionnels aux probabilités), c'est-à-dire . Sortie . Code , qui est le tuple de mots de code (binaires), où est le mot de code pour . Objectif . Soit la longueur du chemin pondéré du code . Condition : pour tout code .
Exemple
Nous donnons un exemple du résultat du codage de Huffman pour un code à cinq caractères et des poids donnés. Nous ne vérifierons pas s'il minimise L pour tous les codes, mais nous calculerons L et le comparerons à l' entropie de Shannon H de l'ensemble de poids donné ; le résultat est quasi optimal.
| Entrée ( A , W ) | Symbole ( Sortie C | Mots de code ( |
|---|---|---|
| Longueur du mot de code (en bits) ( Optimalité | Budget de probabilité ( décodable de manière unique , la somme des probabilités associées à chaque symbole est toujours inférieure ou égale à un. Dans cet exemple, cette somme est strictement égale à un ; par conséquent, le code est dit complet . Si ce n'est pas le cas, on peut toujours obtenir un code équivalent en ajoutant des symboles supplémentaires (associés à des probabilités nulles), afin de le rendre complet tout en conservant sa biunicité . Selon la définition de Shannon (1948) , le contenu informationnel h (en bits) de chaque symbole a<sub> i</sub> ayant une probabilité non nulle est L' entropie H (en bits) est la somme pondérée, sur tous les symboles 0}w_{i}h(a_{i})=\sum _{w_{i}>0}w_{i}\log _{2}{1 \over w_{i}}=-\sum _{w_{i}>0}w_{i}\log _{2}w_{i}. (Remarque : Un symbole de probabilité nulle contribue à hauteur de zéro à l’entropie, puisque . Par souci de simplicité, les symboles de probabilité nulle peuvent donc être omis de la formule ci-dessus.) En vertu du théorème de codage source de Shannon , l'entropie mesure la longueur minimale d'un mot de code théoriquement possible pour un alphabet donné, pondéré de la longueur du mot. Dans cet exemple, la longueur moyenne pondérée d'un mot de code est de 2,25 bits par symbole, soit légèrement supérieure à l'entropie calculée de 2,205 bits par symbole. Ce code est donc non seulement optimal (aucun autre code réalisable n'est plus performant), mais il est également très proche de la limite théorique établie par Shannon. En général, un code de Huffman n'est pas nécessairement unique. Ainsi, l'ensemble des codes de Huffman pour une distribution de probabilité donnée est un sous-ensemble non vide des codes minimisant cette distribution. (Cependant, pour chaque attribution de longueur de mot de code minimisant cette longueur, il existe au moins un code de Huffman de cette longueur.) technique de baseCompression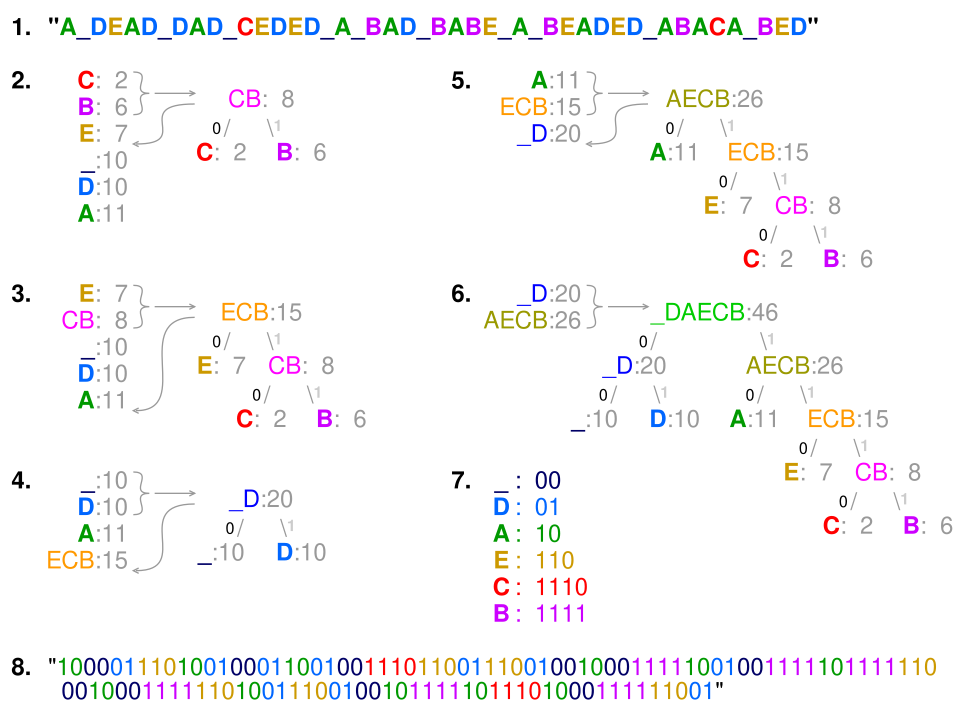 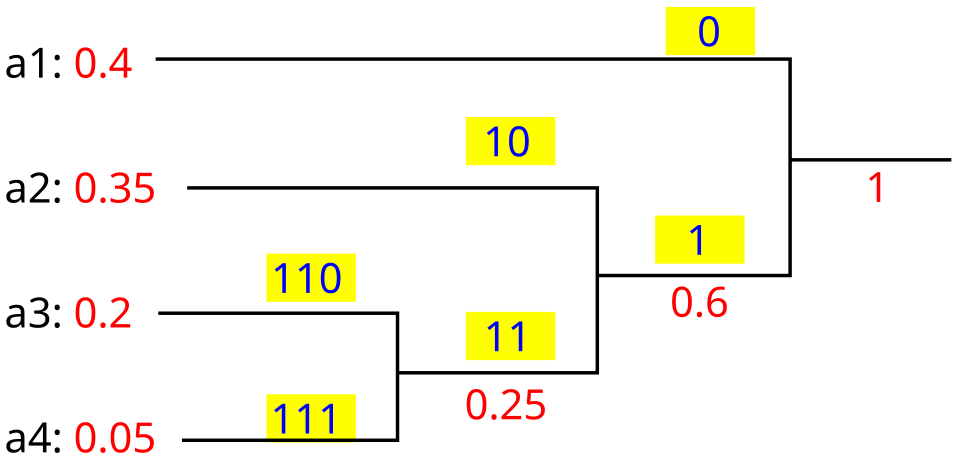 Cette technique consiste à créer un arbre binaire de nœuds. Ces nœuds peuvent être stockés dans un tableau régulier dont la taille dépend du nombre de symboles . Un nœud peut être soit une feuille , soit un nœud interne . Initialement, tous les nœuds sont des feuilles : ils contiennent le symbole lui-même, son poids (fréquence d'apparition) et, éventuellement, un lien vers un nœud parent , ce qui facilite la lecture du code (à l'envers) à partir d'une feuille. Les nœuds internes contiennent un poids , des liens vers deux nœuds enfants et, éventuellement, un lien vers un nœud parent . Par convention, le bit « 0 » indique de suivre l'enfant gauche et le bit « 1 » indique de suivre l'enfant droit. Un arbre complet comporte jusqu'à feuilles et nœuds internes. Un arbre de Huffman qui omet les symboles inutilisés produit les longueurs de code les plus optimales. Le processus commence avec les nœuds feuilles contenant les probabilités du symbole qu'ils représentent. Ensuite, il sélectionne les deux nœuds ayant la plus faible probabilité et crée un nouveau nœud interne dont ces deux nœuds sont les enfants. Le poids de ce nouveau nœud est égal à la somme des poids de ses enfants. On applique ensuite le processus à nouveau, sur le nouveau nœud interne et sur les nœuds restants (c'est-à-dire en excluant les deux nœuds feuilles), et on répète ce processus jusqu'à ce qu'il ne reste qu'un seul nœud, qui est la racine de l'arbre de Huffman. L'algorithme de construction le plus simple utilise une file de priorité où le nœud ayant la plus faible probabilité se voit attribuer la priorité la plus élevée :
Étant donné que les structures de données de file de priorité efficaces nécessitent un temps O(log n ) par insertion, et qu'un arbre avec n feuilles a 2 n −1 nœuds, cet algorithme fonctionne en O( n log n ), où n est le nombre de symboles. Si les symboles sont triés par probabilité, il existe une méthode linéaire (O( n )) pour créer un arbre de Huffman à l'aide de deux files d' attente : la première contient les poids initiaux (ainsi que des pointeurs vers les feuilles associées), et les poids combinés (ainsi que des pointeurs vers les arbres) sont placés à la fin de la seconde file d'attente. Ceci garantit que le poids le plus faible est toujours placé en tête de l'une des deux files d'attente :
Une fois l'arbre de Huffman généré, on le parcourt pour générer un dictionnaire qui associe les symboles à des codes binaires comme suit :
L'encodage final de chaque symbole est alors lu par une concaténation des étiquettes sur les arêtes le long du chemin allant du nœud racine au symbole. Dans de nombreux cas, la complexité temporelle n'est pas très importante dans le choix de l'algorithme, car n représente ici le nombre de symboles dans l'alphabet, qui est généralement un nombre très petit (comparé à la longueur du message à encoder) ; tandis que l'analyse de la complexité concerne le comportement lorsque n devient très grand. Il est généralement avantageux de minimiser la variance de la longueur des mots de code. Par exemple, un tampon de communication recevant des données codées par Huffman peut nécessiter une taille plus importante pour gérer des symboles particulièrement longs si l'arbre est fortement déséquilibré. Pour minimiser la variance, il suffit de départager les files d'attente en choisissant l'élément de la première file. Cette modification préserve l'optimalité mathématique du codage de Huffman tout en minimisant la variance et la longueur du code du caractère le plus long. DécompressionDe manière générale, la décompression consiste simplement à traduire le flux de codes de préfixe en valeurs d'octets individuelles, généralement en parcourant l'arbre de Huffman nœud par nœud à mesure que chaque bit est lu dans le flux d'entrée (atteindre une feuille met fin à la recherche de cette valeur d'octet). Cependant, avant cela, l'arbre de Huffman doit être reconstruit. Dans le cas le plus simple, où les fréquences des caractères sont relativement prévisibles, l'arbre peut être préconstruit (et même ajusté statistiquement à chaque cycle de compression) et ainsi réutilisé, au prix d'une légère perte d'efficacité de compression. Sinon, les informations nécessaires à la reconstruction de l'arbre doivent être transmises a priori. Une approche naïve consisterait à ajouter le nombre d'occurrences de chaque caractère au début du flux de compression. Malheureusement, la surcharge dans ce cas pourrait atteindre plusieurs kilo-octets, ce qui rend cette méthode peu pratique. Si les données sont compressées à l'aide d' un codage canonique , le modèle de compression peut être reconstruit avec précision à partir de quelques bits d'information (où OptimalitéBien que les deux méthodes susmentionnées puissent combiner un nombre arbitraire de symboles pour un codage plus efficace et s'adaptent généralement aux statistiques d'entrée réelles, le codage arithmétique le fait sans augmenter significativement sa complexité de calcul ou algorithmique (bien que sa version la plus simple soit plus lente et plus complexe que le codage de Huffman). Cette flexibilité est particulièrement utile lorsque les probabilités d'entrée sont imprécises ou varient considérablement au sein du flux. Cependant, le codage de Huffman est généralement plus rapide et le codage arithmétique a historiquement suscité des inquiétudes quant aux brevets . De ce fait, de nombreuses technologies ont historiquement privilégié le codage de Huffman et d'autres techniques de codage par préfixe, délaissant ainsi le codage arithmétique. À la mi-2010, les techniques les plus couramment utilisées pour cette alternative au codage de Huffman sont tombées dans le domaine public, les premiers brevets ayant expiré. Pour un ensemble de symboles à distribution de probabilité uniforme et dont le nombre d'éléments est une puissance de deux , le codage de Huffman est équivalent à un codage binaire par blocs simple , tel que le codage ASCII . Ceci s'explique par le fait qu'aucune compression n'est possible avec de telles données d'entrée, quelle que soit la méthode employée ; autrement dit, ne rien modifier aux données est la solution optimale. Le codage de Huffman est optimal parmi toutes les méthodes lorsque chaque position du flux d'entrée est une variable aléatoire indépendante et identiquement distribuée, de probabilité dyadique . Les codes préfixes, et donc le codage de Huffman en particulier, sont généralement inefficaces sur les petits alphabets, où les probabilités se situent souvent entre ces points optimaux (dyadiques). Le pire cas pour le codage de Huffman se produit lorsque la probabilité du symbole le plus probable dépasse largement 2<sup>1/2 </sup> − 1 = 0,5, rendant la limite supérieure de l'inefficacité infinie. Deux approches connexes permettent de contourner cette inefficacité tout en utilisant le codage de Huffman. Le regroupement d'un nombre fixe de symboles (« blocage ») augmente généralement (et ne diminue jamais) la compression. Lorsque la taille du bloc tend vers l'infini, le codage de Huffman tend théoriquement vers la limite d'entropie, c'est-à-dire la compression optimale . Cependant, le blocage de groupes de symboles arbitrairement grands est impraticable, car la complexité d'un code de Huffman est linéaire par rapport au nombre de possibilités de codage, un nombre qui est exponentiel par rapport à la taille d'un bloc. Ceci limite le blocage effectué en pratique. Une alternative pratique et largement répandue est le codage par plages . Cette technique ajoute une étape au codage entropique : le comptage (ou séquence) des symboles répétés, qui sont ensuite codés. Dans le cas simple des processus de Bernoulli , le codage de Golomb est optimal parmi les codes préfixes pour le codage par plages, un fait démontré par les techniques de codage de Huffman . Une approche similaire est utilisée par les télécopieurs, qui emploient un codage de Huffman modifié . Cependant, le codage par plages n'est pas aussi adaptable à un grand nombre de types d'entrées que d'autres technologies de compression. VariationsIl existe de nombreuses variantes du codage de Huffman , dont certaines utilisent un algorithme de type Huffman, et d'autres qui déterminent les codes préfixes optimaux (en imposant, par exemple, différentes restrictions sur la sortie). Il convient de noter que, dans ce dernier cas, la méthode n'est pas nécessairement de type Huffman, et n'a même pas besoin d'être polynomiale . Codage de Huffman n -aireL' algorithme de Huffman n -aire utilise un alphabet de taille n , généralement {0, 1, ..., n-1}, pour encoder les messages et construire un arbre n -aire. Cette approche a été proposée par Huffman dans son article original. Le même algorithme s'applique qu'aux codes binaires, mais au lieu de combiner les deux symboles les moins probables, les n symboles les moins probables sont regroupés. Notez que pour n > 2, tous les ensembles de mots sources ne peuvent pas former correctement un arbre n -aire complet pour le codage de Huffman. Dans ces cas, il peut être nécessaire d'ajouter des symboles de substitution supplémentaires de probabilité nulle. En effet, la structure de l'arbre doit relier de manière répétée n branches en une seule, ce que l'on appelle une combinaison « n à 1 ». Pour le codage binaire, il s'agit d'une combinaison « 2 à 1 », qui fonctionne quel que soit le nombre de symboles. Pour le codage n -aire, un arbre complet n'est possible que si le nombre total de symboles (réels + symboles de substitution) est égal à 1 lorsqu'il est divisé par (n-1). Codage de Huffman adaptatifUne variante appelée codage de Huffman adaptatif consiste à calculer dynamiquement les probabilités en fonction des fréquences réelles récentes dans la séquence des symboles sources, et à modifier la structure de l'arbre de codage pour correspondre aux estimations de probabilité mises à jour. Elle est rarement utilisée en pratique, car le coût de la mise à jour de l'arbre la rend plus lente que le codage arithmétique adaptatif optimisé , qui est plus flexible et offre une meilleure compression.monoïde commutatif totalement ordonné , c'est-à-dire qu'il existe une méthode pour ordonner et additionner les poids. L' algorithme de Huffman permet d'utiliser tout type de poids (coûts, fréquences, paires de poids, poids non numériques) et diverses méthodes de combinaison (et pas seulement l'addition). De tels algorithmes peuvent résoudre d'autres problèmes de minimisation, comme la minimisation de , un problème initialement appliqué à la conception de circuits. Codage de Huffman à longueur limitée/codage de Huffman à variance minimaleLe codage de Huffman à longueur limitée est une variante où l'objectif reste d'obtenir une longueur de chemin pondéré minimale, mais avec une contrainte supplémentaire : la longueur de chaque mot de code doit être inférieure à une constante donnée. L' algorithme de fusion de paquets résout ce problème par une approche gloutonne simple , très similaire à celle de l'algorithme de Huffman. Sa complexité temporelle est O (n^n) , où n est la longueur maximale d'un mot de code. Contrairement aux problèmes de Huffman conventionnels pré-triés et non triés, aucun algorithme connu ne résout ce problème en O(n^n) ou O(n^n), respectivement. Codage de Huffman avec des coûts de lettres inégauxDans le problème de codage de Huffman standard, on suppose que chaque symbole de l'ensemble à partir duquel les mots de code sont construits a un coût de transmission identique : un mot de code de longueur N chiffres aura toujours un coût de N , quel que soit le nombre de 0, de 1, etc. parmi ces chiffres. Sous cette hypothèse, minimiser le coût total du message et minimiser le nombre total de chiffres reviennent au même. Le codage de Huffman avec coûts de lettres inégaux est une généralisation qui s'affranchit de cette hypothèse : les lettres de l'alphabet de codage peuvent avoir des longueurs non uniformes, du fait des caractéristiques du support de transmission. L'alphabet de codage du code Morse en est un exemple : un tiret est plus long à transmettre qu'un point, et son coût temporel est donc plus élevé. L'objectif reste de minimiser la longueur moyenne pondérée des mots de code, mais il ne suffit plus de minimiser uniquement le nombre de symboles utilisés par le message. Aucun algorithme connu ne résout ce problème de la même manière ni avec la même efficacité que le codage de Huffman classique, bien qu'il ait été résolu par Richard M. Karp , dont la solution a été affinée pour le cas des coûts entiers par Mordecai J. Golin Arbres binaires alphabétiques optimaux (codage Hu-Tucker)Dans le problème de codage de Huffman standard, on suppose que tout mot de code peut correspondre à n'importe quel symbole d'entrée. Dans la version alphabétique, l'ordre alphabétique des entrées et des sorties doit être identique. Ainsi, par exemple, le code « a » ne peut pas être attribué à « a » , mais devrait plutôt être attribué à « a » ou « a ». Ce problème est également connu sous le nom de problème de Hu-Tucker , d'après T.C. Hu et Alan Tucker , auteurs de l'article présentant la première solution en O( n) à ce problème binaire alphabétique optimal . Ce problème présente certaines similitudes avec l'algorithme de Huffman, mais n'en est pas une variante. Une méthode ultérieure, l' algorithme de Garsia-Wachs d' Adriano Garsia et Michelle L. Wachs (1977), utilise une logique plus simple pour effectuer les mêmes comparaisons dans le même laps de temps total. Ces arbres binaires alphabétiques optimaux sont souvent utilisés comme arbres de recherche binaire . Le code Huffman canoniqueApplicationsLe codage arithmétique et le codage de Huffman produisent des résultats équivalents — atteignant l'entropie — lorsque chaque symbole a une probabilité de la forme 1/ 2k . Dans d'autres cas, le codage arithmétique offre une meilleure compression que le codage de Huffman car , intuitivement , ses « mots de code » peuvent avoir des longueurs de bits non entières, contrairement aux mots de code des codes préfixes tels que les codes de Huffman qui ne peuvent avoir qu'un nombre entier de bits. Par conséquent, un mot de code de longueur k ne correspond de manière optimale qu'à un symbole de probabilité 1/ 2k , les autres probabilités n'étant pas représentées de manière optimale ; alors que la longueur du mot de code en codage arithmétique peut être ajustée pour correspondre exactement à la probabilité réelle du symbole. Cette différence est particulièrement marquée pour les petits alphabets.de l'absence de brevets . Ils servent souvent de couche d'extraction à d'autres méthodes de compression. Deflate ( l'algorithme de PKZIP ) et les codecs multimédias tels que JPEG et MP3 possèdent un modèle d'extraction et une quantification suivis de l'utilisation de codes préfixes ; on les appelle souvent « codes de Huffman », même si la plupart des applications utilisent des codes de longueur variable prédéfinis plutôt que des codes conçus à l'aide de l'algorithme de Huffman. Plus d articles de Worldlex WikiRevenez a l index pour explorer davantage de pages sur l histoire, la science, la culture, la geographie et la societe en francais. Explorer l index |