codage entropique utilisée en compression de données sans perte . Normalement, une chaîne de caractères est représentée par un nombre fixe de bits par caractère, comme dans le code ASCII . Lors de la conversion d'une chaîne en codage arithmétique, les caractères fréquents sont stockés avec moins de bits et les caractères moins fréquents avec plus de bits, ce qui réduit le nombre total de bits utilisés. Le codage arithmétique diffère des autres formes de codage entropique, comme le codage de Huffman , en ce qu'au lieu de séparer l'entrée en symboles composants et de remplacer chacun par un code, le codage arithmétique encode le message entier en un seul nombre, une fraction q de précision arbitraire , où
Lorsque tous les symboles sont équiprobables, chaque sous-intervalle a la même taille et aucun symbole ne peut être représenté avec moins de bits qu'un autre. Dans ce cas, l'entropie atteint son maximum de bits par symbole (où n est la taille de l'alphabet), et aucune compression n'est possible. Par exemple, un flux de lancers de pièces équilibrées et indépendants a une entropie de 1 bit par symbole — soit le coût total du stockage —, de sorte que le codage arithmétique n'apporte aucun avantage. De même, des symboles ternaires indépendants de probabilités égales ont une entropie d'environ 1,585 bits par symbole, le maximum pour un alphabet à trois symboles, et sont également incompressibles.
La compression devient possible lorsque les probabilités sont inégales, car les sous-intervalles deviennent alors de tailles inégales. Par exemple, une source binaire avec des probabilités de 0,9 et 0,1 possède une entropie d'environ 0,469 bits par symbole. Le symbole de probabilité 0,9 occupe 90 % de chaque intervalle ; ainsi, la plupart des étapes de codage ne réduisent que très légèrement l'intervalle, et moins de bits sont nécessaires pour identifier la valeur finale. Ceci permet au codage arithmétique d'atteindre un taux de compression d'environ 2,1:1.
Détails et exemples de mise en œuvre
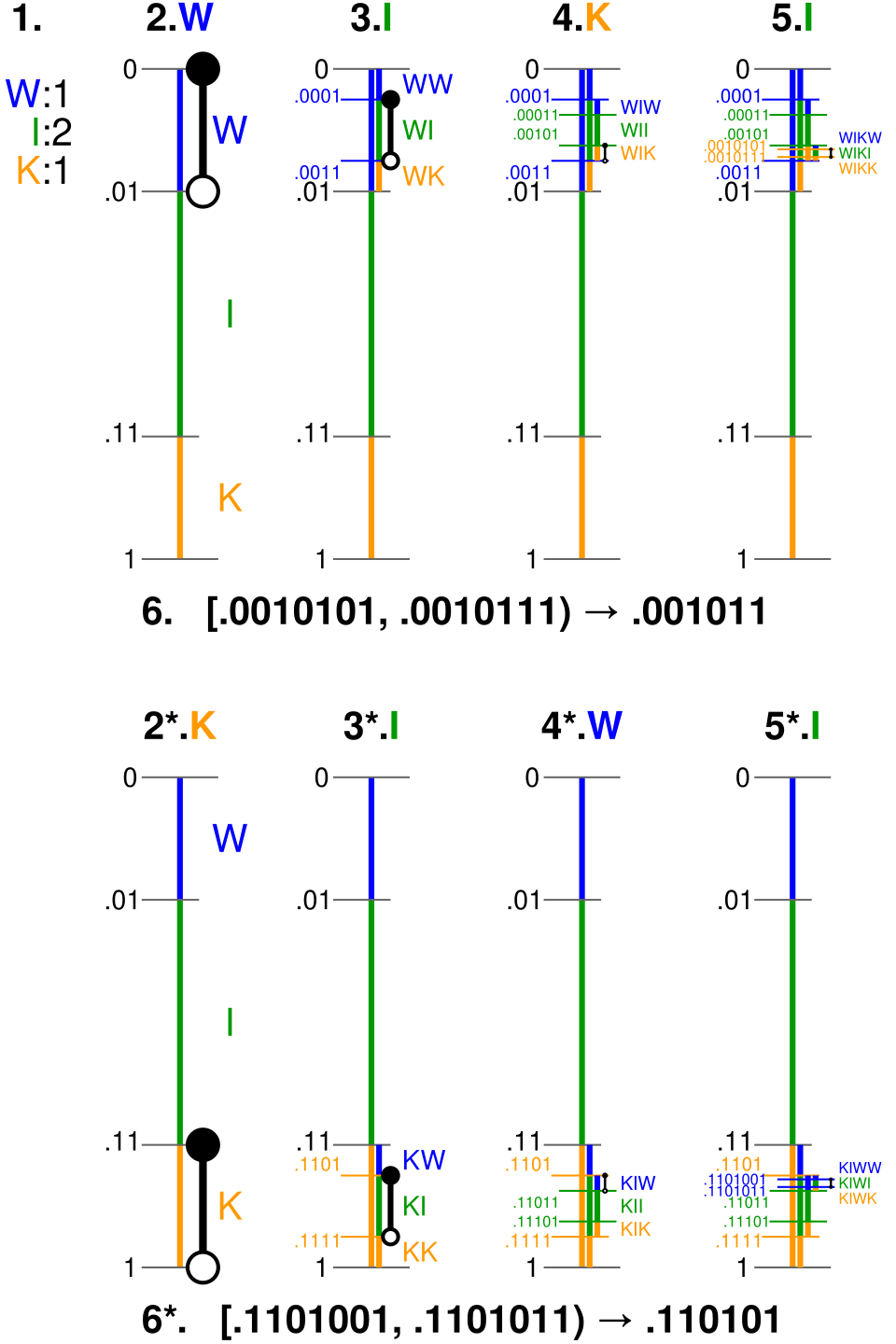
| 1. | Les fréquences des lettres ont été déterminées. |
|---|---|
| 2. | L'intervalle [0, 1) est divisé dans le rapport des fréquences. |
| 3–5. | L'intervalle correspondant est partitionné de manière itérative pour chaque lettre du message. |
| 6. | Toute valeur de l'intervalle final est choisie pour représenter le message. |
| 2*–6*. | Le partitionnement et la valeur si le message était « KIWI » à la place. |
Probabilités égales
Dans le cas le plus simple, la probabilité d'apparition de chaque symbole est égale. Par exemple, considérons un ensemble de trois symboles, A, B et C, ayant chacun la même probabilité d'apparaître. Encoder les symboles un par un nécessiterait 2 bits par symbole, ce qui est un gaspillage : l'une des variations de bits n'est jamais utilisée. Autrement dit, les symboles A, B et C pourraient être codés respectivement par 00, 01 et 10, le bit 11 restant inutilisé.
Une solution plus efficace consiste à représenter une séquence de ces trois symboles par un nombre rationnel en base 3, où chaque chiffre représente un symbole. Par exemple, la séquence « ABBCAB » pourrait devenir 0,011201<sub> 3</sub> , en codage arithmétique, une valeur dans l'intervalle [ 0, 1). L'étape suivante consiste à encoder ce nombre ternaire à l'aide d'un nombre binaire à virgule fixe d'une précision suffisante pour le retrouver, tel que 0,0010110001<sub> 2</sub> – soit seulement 10 bits ; 2 bits sont ainsi économisés par rapport à un codage par blocs naïf. Cette méthode est applicable aux longues séquences car il existe des algorithmes efficaces, exécutés sur place, pour convertir la base de nombres d'une précision arbitraire.
Pour décoder la valeur, sachant que la chaîne d'origine avait une longueur de 6, il suffit de la reconvertir en base 3, d'arrondir à 6 chiffres et de récupérer la chaîne.
Définir un modèle
En général, les codeurs arithmétiques peuvent produire un résultat quasi optimal pour tout ensemble donné de symboles et de probabilités. (La valeur optimale est de −log₂P bits par symbole de probabilité P ; voir le théorème de codage source .) Les algorithmes de compression utilisant le codage arithmétique commencent par déterminer un modèle des données, c’est-à-dire une prédiction des motifs présents dans les symboles du message. Plus cette prédiction est précise, plus le résultat sera proche de l’optimum.
Exemple : un modèle simple et statique permettant de décrire l'évolution des données d'un instrument de surveillance particulier au fil du temps pourrait être le suivant :
- 60 % de chances que le symbole soit NEUTRE
- 20 % de chances d'obtenir le symbole POSITIF
- 10 % de chances que le symbole soit NÉGATIF
- 10 % de chances de rencontrer le symbole END-OF-DATA. (La présence de ce symbole signifie que le flux sera « terminé en interne », ce qui est assez courant en compression de données ; lorsque ce symbole apparaît dans le flux de données, le décodeur sait que le flux entier a été décodé.)
Les modèles peuvent également gérer des alphabets autres que le simple ensemble de quatre symboles choisi pour cet exemple. Des modèles plus sophistiqués sont également possibles : la modélisation d’ordre supérieur modifie son estimation de la probabilité actuelle d’un symbole en fonction des symboles qui le précèdent (le contexte ). Ainsi, dans un modèle pour un texte anglais, par exemple, la probabilité que « u » apparaisse est beaucoup plus élevée lorsqu’il suit un « Q » ou un « q ». Les modèles peuvent même être adaptatifs , c’est-à-dire qu’ils modifient continuellement leur prédiction des données en fonction du contenu réel du flux. Le décodeur doit utiliser le même modèle que l’encodeur.
Encodage et décodage : aperçu
En général, chaque étape du processus d'encodage, à l'exception de la dernière, est la même ; l'encodeur n'a essentiellement que trois éléments de données à prendre en compte :
- Le prochain symbole à encoder
- L' intervalle actuel (au tout début du processus d'encodage, l'intervalle est fixé à [0,1] , mais cela changera)
- Les probabilités que le modèle attribue à chacun des différents symboles possibles à ce stade (comme mentionné précédemment, les modèles d'ordre supérieur ou adaptatifs impliquent que ces probabilités ne sont pas nécessairement les mêmes à chaque étape).
L'encodeur divise l'intervalle courant en sous-intervalles, chacun représentant une fraction de l'intervalle courant proportionnelle à la probabilité de ce symbole dans le contexte actuel. L'intervalle correspondant au symbole qui sera ensuite encodé devient l'intervalle utilisé à l'étape suivante.
Exemple : pour le modèle à quatre symboles ci-dessus :
- l'intervalle pour NEUTRE serait [0, 0,6)
- l'intervalle pour POSITIF serait [0,6 ; 0,8).
- l'intervalle pour NÉGATIF serait [0,8 ; 0,9).
- l'intervalle pour END-OF-DATA serait [0.9, 1) .
Une fois tous les symboles encodés, l'intervalle résultant identifie sans ambiguïté la séquence de symboles qui l'a produit. Quiconque possède le même intervalle final et le même modèle que celui utilisé peut reconstituer la séquence de symboles qui a dû entrer dans l'encodeur pour produire cet intervalle final.
Il n’est pas nécessaire de transmettre l’intervalle final ; il suffit de transmettre une fraction qui s’y trouve. Plus précisément, il suffit de transmettre suffisamment de chiffres (quelle que soit la base) de la fraction pour que toutes les fractions commençant par ces chiffres appartiennent à l’intervalle final ; cela garantit que le code résultant est un code préfixe .
Encodage et décodage : exemple
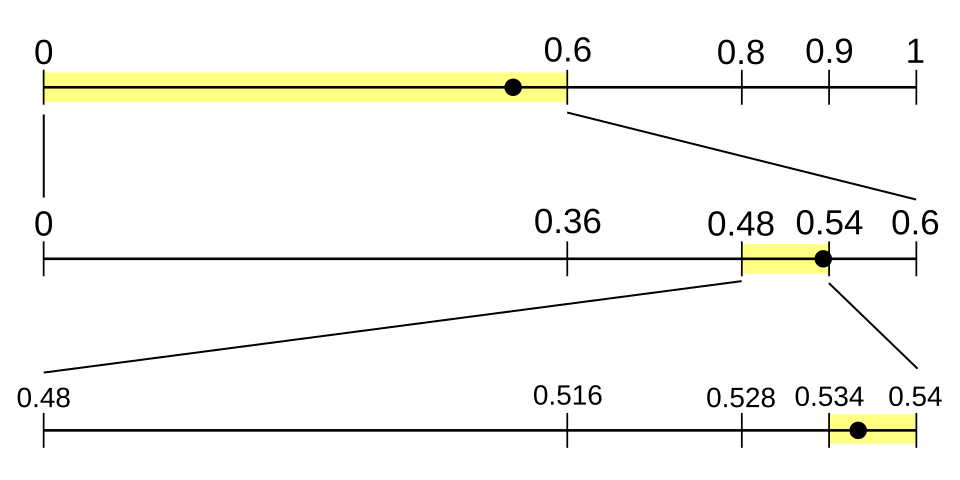
Considérons le processus de décodage d'un message codé avec le modèle à quatre symboles donné. Le message est codé dans la fraction 0,538 (en utilisant le système décimal pour plus de clarté, au lieu du binaire ; en supposant également qu'il n'y a que le nombre de chiffres nécessaires pour décoder le message).
Le processus débute avec le même intervalle que celui utilisé par l'encodeur : [0,1) . En utilisant le même modèle, cet intervalle est divisé en quatre sous-intervalles identiques à ceux de l'encodeur. La fraction 0,538 se situe dans le sous-intervalle correspondant à NEUTRE, [0, 0,6) ; cela indique que le premier symbole lu par l'encodeur était NEUTRE, et qu'il s'agit donc du premier symbole du message.
Ensuite, divisez l'intervalle [0, 0,6) en sous-intervalles :
- l'intervalle pour NEUTRE serait [0, 0,36) , 60% de [0, 0,6) .
- l'intervalle pour POSITIF serait [0,36, 0,48) , 20% de [0, 0,6) .
- l'intervalle pour NÉGATIF serait [0,48, 0,54) , 10% de [0, 0,6) .
- l'intervalle pour END-OF-DATA serait [0,54, 0,6) , 10% de [0, 0,6) .
Puisque 0,538 se trouve dans l'intervalle [0,48, 0,54) , le deuxième symbole du message doit avoir été NÉGATIF.
Divisons à nouveau notre intervalle actuel en sous-intervalles :
- l'intervalle pour NEUTRE serait [0,48, 0,516) .
- l'intervalle pour POSITIF serait [0,516, 0,528) .
- l'intervalle pour NÉGATIF serait [0,528, 0,534) .
- l'intervalle pour END-OF-DATA serait [0.534, 0.540) .
La valeur 0,538 se situe dans l'intervalle du symbole de fin de données ; il s'agit donc du symbole suivant. Comme il s'agit également du symbole de terminaison interne, le décodage est terminé. Si le flux n'est pas terminé en interne, il est nécessaire d'indiquer son point d'arrêt. Autrement, le processus de décodage pourrait se poursuivre indéfiniment, lisant par erreur plus de symboles de la fraction que ceux qui y sont réellement encodés.
Sources d'inefficience
Le message 0,538 de l'exemple précédent aurait pu être codé par les fractions tout aussi courtes 0,534, 0,535, 0,536, 0,537 ou 0,539. Cela suggère que l'utilisation du système décimal au lieu du binaire a introduit une certaine inefficacité. C'est exact ; le contenu informationnel d'un nombre décimal à trois chiffres est de 8 bits ; le même message aurait pu être codé dans la fraction binaire 0,10001001 (équivalente à 0,53515625 en décimal) en utilisant seulement 8 bits.
Cette sortie de 8 bits est supérieure au contenu informationnel, ou entropie , du message, qui est
Cependant, l'encodage binaire nécessite un nombre entier de bits ; par conséquent, un encodeur pour ce message utiliserait au moins 8 bits, ce qui augmenterait la taille du message de 8,4 % par rapport à son contenu entropique. Cette perte d'au plus 1 bit engendre une surcharge relativement faible lorsque la taille du message augmente.
De plus, les probabilités des symboles annoncées étaient [0,6 ; 0,2 ; 0,1 ; 0,1) , mais les fréquences réelles dans cet exemple sont [0,33 ; 0 ; 0,33 ; 0,33) . Si les intervalles sont réajustés à ces fréquences, l’entropie du message serait de 4,755 bits et le même message NEUTRAL NEGATIVE END-OF-DATA pourrait être codé sous forme d’intervalles [0 ; 1/3) ; [1/9 ; 2/9) ; [5/27 ; 6/27) ; et d’un intervalle binaire de [0,00101111011 ; 0,00111000111) . Ceci illustre également comment les méthodes de codage statistique, telles que le codage arithmétique, peuvent produire un message de sortie plus long que le message d’entrée, en particulier si le modèle de probabilité est erroné.
Codage arithmétique adaptatif
En tant que nombre dans une certaine base, en supposant que les symboles impliqués forment un ensemble ordonné et que chaque symbole de cet ensemble représente un entier séquentiel (A = 0, B = 1, C = 2, D = 3, etc.), on obtient les fréquences et fréquences cumulées suivantes :
| Symbole | Fréquence d'occurrence | Fréquence cumulée |
|---|---|---|
| UN | 1 | 0 |
| B | 2 | 1 |
| D | 3 | 3 |
La fréquence cumulée d'un élément est la somme de toutes les fréquences qui le précèdent. Autrement dit, la fréquence cumulée est un total glissant des fréquences.
Dans un système de numération positionnel , la base est numériquement égale à un certain nombre de symboles différents utilisés pour exprimer le nombre. Par exemple, dans le système décimal, il existe 10 symboles : 0, 1, 2, 3, 4, 5, 6, 7, 8 et 9. La base sert à exprimer tout entier fini sous forme polynomiale, en utilisant un multiplicateur implicite. Par exemple, le nombre 457 s'écrit en réalité 4 × 10² + 5 × 10¹ + 7 × 10⁰ , la base 10 étant sous-entendue.
Dans un premier temps, nous convertirons DABDDB en un nombre en base 6, car 6 correspond à la longueur de la chaîne. Celle-ci est d'abord transformée en la chaîne de chiffres 301331, qui est ensuite convertie en un entier par le polynôme :
Le résultat 23671 a une longueur de 15 bits, ce qui n'est pas très proche de la limite théorique (l' entropie du message), qui est d'environ 9 bits.
Pour encoder un message dont la longueur se rapproche de la limite théorique imposée par la théorie de l'information, il est nécessaire de généraliser légèrement la formule classique de changement de base. Nous calculerons les bornes inférieure et supérieure L et U et choisirons une valeur comprise entre elles. Pour le calcul de L, nous multiplions chaque terme de l'expression ci-dessus par le produit des fréquences de tous les symboles précédemment apparus :
La différence entre ce polynôme et le polynôme précédent réside dans le fait que chaque terme est multiplié par le produit des fréquences de tous les symboles précédemment apparus. Plus généralement, L peut être calculé comme suit :
où représentent les fréquences cumulées et les fréquences d'occurrence. Les indices indiquent la position du symbole dans un message. Dans le cas particulier où toutes les fréquences sont égales à 1, il s'agit de la formule de changement de base.
La borne supérieure U sera égale à L plus le produit de toutes les fréquences ; dans ce cas, U = L + (3 × 1 × 2 × 3 × 3 × 2) = 25 002 + 108 = 25 110. En général, U est donné par :
On peut maintenant choisir n'importe quel nombre de l'intervalle [ L , U ) pour représenter le message ; un choix judicieux est la valeur avec la plus longue suite de zéros possible, soit 25100, car elle permet une compression en représentant le résultat sous la forme 251 × 10² . On peut également tronquer les zéros, ce qui donne 251, si la longueur du message est stockée séparément. Les messages plus longs auront généralement des suites de zéros plus longues.
Pour décoder l'entier 25100, le calcul polynomial peut être inversé comme indiqué dans le tableau ci-dessous. À chaque étape, le symbole courant est identifié, puis le terme correspondant est soustrait du résultat.
| Reste | Identification | Symbole identifié | Reste corrigé |
|---|---|---|---|
| 25100 | 25100 / 6 5 = 3 | D | (25100 − 6 5 × 3) / 3 = 590 |
| 590 | 590 / 6 4 = 0 | UN | (590 − 6 4 × 0) / 1 = 590 |
| 590 | 590 / 6 3 = 2 | B | (590 − 6 3 × 1) / 2 = 187 |
| 187 | 187 / 6 2 = 5 | D | (187 − 6 2 × 3) / 3 = 26 |
 0
0