Les codes EUC les plus couramment utilisés sont des codages à longueur variable : un caractère appartenant à un jeu de caractères codés conforme à la norme ISO/IEC 646 (tel que l’ASCII ) occupe un octet, tandis qu’un caractère appartenant à un jeu de caractères codés 94×94 (tel que le GB 2312 ) est représenté sur deux octets. Les formats EUC-CN ( EUC-KR sont des exemples de tels codes EUC sur deux octets. Le format EUC-JP inclut des caractères représentés par un maximum de trois octets, incluant un code de décalage initial , tandis qu’un seul caractère en EUC-TW peut occuper jusqu’à quatre octets.
Les applications modernes privilégient l'UTF-8 , qui prend en charge tous les glyphes des codes EUC, et bien plus encore, et offre généralement une meilleure portabilité, avec moins de variations et d'erreurs selon les fournisseurs. L'EUC reste cependant très populaire, notamment l'EUC-KR en Corée du Sud.
L'EUC est une famille de profils 8 bits de l'ISO-2022-JP . De ce fait, seuls les jeux de caractères conformes à à l'ISO/IEC 646, tel que l'ASCII , l'ISO 646:JP (la moitié inférieure de ASCII étendu . L'écart le plus courant par rapport à l'ASCII est que 0x5C ( barre oblique inverse en ASCII) est souvent utilisé pour représenter un signe yen en EUC-JP (voir ci-dessous) et un signe won en EUC-KR.
Les autres jeux de caractères sont invoqués via GR (c'est-à-dire avec le bit de poids fort à 1). Par conséquent, pour obtenir la forme EUC d'un caractère, le bit de poids fort de chaque octet de codage est activé (ce qui équivaut à ajouter 128 à chaque octet de codage de 7 bits, ou 160 à chaque nombre du code kuten ) ; cela permet au logiciel de distinguer facilement si un octet donné dans une chaîne de caractères appartient au code SS2 (0x8E) et SS3 (0x8F), et invoqués via GR. Hormis le code de décalage initial, tout octet hors de la plage 0xA0–0xFF apparaissant dans un caractère des jeux de caractères 1 à 3 n'est pas un code EUC valide.
Le code EUC lui-même n’utilise pas les séquences d’annonce et de désignation de L’ encodage à longueur variable basé sur la norme ISO-2022 décrit ci-dessus est parfois appelé format EUC compressé , qui est le format d’encodage généralement désigné par l’acronyme EUC. Cependant, le traitement interne des données EUC peut utiliser un format de transformation à longueur fixe appelé format EUC complet à deux octets . Cela représente : Les octets initiaux 0x00 et 0x80 sont utilisés lorsque le jeu de caractères n'utilise qu'un seul octet. Il existe également un format à longueur fixe de quatre octets. Ces formats d'encodage à longueur fixe sont adaptés au traitement interne et sont rarement utilisés dans les échanges. EUC-JP est enregistré auprès de l'IANA dans ses deux formats : le format compressé sous « EUC-JP » ou « csEUCPkdFmtJapanese » et le format à largeur fixe sous « csEUCFixWidJapanese ». Seul le format compressé est inclus dans la norme d'encodage WHATWG utilisée par HTML5 . Séquence individuelle Hexadécimal Caractéristique de l'EUC désignée ESC SP C1B 20 43ISO-8 (8 bits, G0 en GL, G1 en GR) ESC SP Z1B 20 5AG2 a accédé via SS2 ESC SP [1B 20 5BG3 accessible via SS3 ESC SP \1B 20 5CLes changements de poste uniques invoquent GR Format à longueur fixe
EUC-CN
Un caractère ASCII est représenté selon son codage habituel. Un caractère de la norme GB 2312 , mais n'est pas conforme à la norme Big5 et d'autres systèmes de codage DBCS non conformes à la norme ISO 2022. ) La partie du code 748 non conforme au GB 2312 contient des caractères traditionnels et hongkongais, ainsi que d'autres glyphes utilisés dans la composition de journaux.
Pages de codes IBM 1380, 1381, 1382 et 1383
La page de codes IBM 1381 ( CCSID 1381) comprend la page de codes mono-octet 1115 (CPGID 1115 sous forme de CCSID 1115) et la page de codes double-octet 1380 (CPGID 1380 sous forme de CCSID 1380), qui encode GB 2312 de la même manière que l'EUC-CN, mais s'écarte de la structure EUC en étendant la plage d'octets de tête jusqu'à 0x8C, en ajoutant 31 caractères sélectionnés par IBM de 0x8CE0 à 0x8CFE et en ajoutant 1880 caractères définis par l'utilisateur avec des octets de tête de 0x8D à 0xA0.
La page de codes IBM 1383 (CCSID 1383) comprend la page de codes mono-octet 367 et la page de codes bi-octet 1382 (CPGID 1382, également appelée CCSID 1382) Cette dernière diffère de la page de codes EUC par sa conformité à la structure EUC, l'ajout des 31 caractères sélectionnés par IBM dans les positions 0xFEE0 à 0xFEFE, et l'inclusion de seulement 1360 caractères définis par l'utilisateur, intercalés dans les positions non utilisées par GB 2312 L'identifiant alternatif CCSID 5479 est utilisé pour la page de codes EUC-CN pure : il utilise le CCSID 9574 comme ensemble bi-octet, lequel utilise le CPGID 1382 mais exclut les caractères sélectionnés par IBM et les caractères définis par l'utilisateur
GBK et GB 18030
Les variantes de GBK sont implémentées par la page de codes Windows 936 (la page de codes Microsoft Windows pour le chinois simplifié) et par la page de codes IBM 1386.
L'encodage de caractères GB 18030, basé sur Unicode, définit une extension de GBK capable d'encoder l'intégralité d' Unicode . Cependant, l'Unicode encodé en encodage à longueur variable pouvant utiliser jusqu'à quatre octets par caractère, en raison d'un espace d'encodage encore plus important requis. Étant une extension de GBK, il s'agit d'un sur-ensemble d'EUC-CN, mais il ne constitue pas un véritable code EUC. En tant qu'encodage Unicode, son répertoire est identique à celui d'autres formats de transformation Unicode tels que l'UTF-8 .
Mac OS Chinois simplifié
D'autres variantes EUC-CN, s'écartant du mécanisme EUC, incluent l' écriture chinoise simplifiée classique de Mac OS (connue sous le nom de page de codes 10008 x-mac-chinesesimp). Elle utilise les octets 0x80, 0x81, 0x82, 0xA0, 0xFD, 0xFE et 0xFF respectivement pour le U tréma (ü), deux caractères spéciaux de la métrique de police, l' espace insécable , le symbole du droit d'auteur (©), le symbole de marque déposée (™) et les points de suspension (...). Cela diffère dans la définition d'un caractère mono-octet par rapport au premier octet d'un caractère bi-octet, tant pour l'EUC (où, parmi ces octets, 0xFD et 0xFE sont définis comme octets de tête) que pour le GBK (où, parmi ces octets, 0x81, 0x82, 0xFD et 0xFE sont définis comme octets de tête).
Cette utilisation de 0xA0, 0xFD, 0xFE et 0xFF correspond à la variante Shift_JIS d'Apple .
Outre ces modifications de la plage d'octets de tête, l'autre caractéristique distinctive de la partie à double octet du chinois simplifié de Mac OS est l'inclusion de deux extensions à l' ensemble de base GB 2312-80 dans les lignes 6 et 8. Celles-ci sont considérées comme des « extensions standard de GB 2312 », dont aucune n'est la propriété d'Apple : l'extension de la ligne 8 a été reprise de GB 6345.1 , les deux extensions sont incluses par GB/T 12345 (la variante chinoise traditionnelle de GB 2312), et les deux extensions sont incluses par GB 18030 (le successeur de GB 2312).
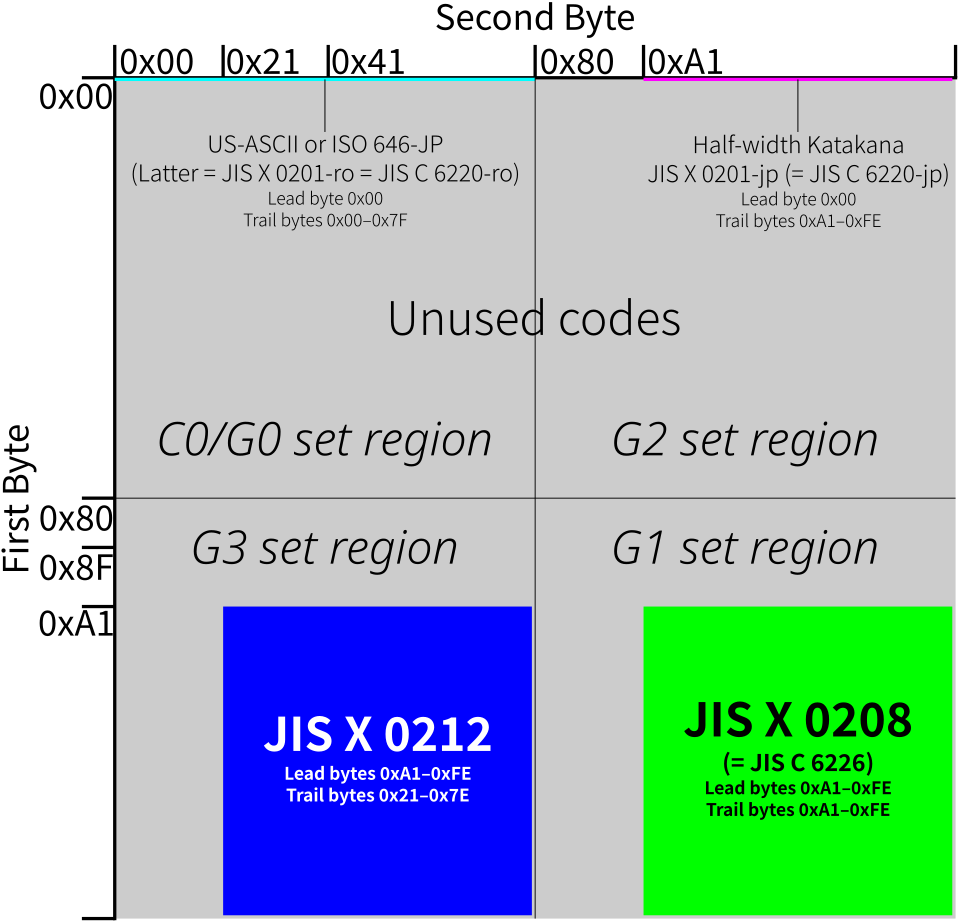
EUC-JP
Ce schéma d'encodage permet de mélanger facilement l'ASCII 7 bits et le japonais 8 bits sans avoir besoin des caractères d'échappement utilisés par l'ISO-2022-JP , qui est basé sur les mêmes normes de jeu de caractères, et sans que les octets ASCII n'apparaissent comme octets de fin (contrairement à Shift JIS ).
Un encodage apparenté et partiellement compatible, appelé EUC-JISx0213 ou EUC-JIS-2004 , encode JIS X 0201 et JIS X 0213 (de la même manière que Shift_JISx0213 , son homologue basé sur Shift_JIS).
Comparé à EUC-CN ou EUC-KR, EUC-JP n'a pas connu le même succès sur les systèmes PC et Macintosh au Japon, qui utilisaient page de codes Windows 932 sur Microsoft Windows et MacJapanese sur Mac OS classique ), bien qu'il soit devenu très répandu sur les systèmes d'exploitation Unix ou de type Unix (à l'exception de HP-UX ). Par conséquent, le choix entre EUC-JP et Shift_JIS pour les sites web japonais dépend souvent du système d'exploitation utilisé par l'auteur.
Les caractères sont encodés comme suit :
- En tant qu'encodage conforme à la norme EUC/ ISO 2022 , les caractères de contrôle C0 , l'espace et DEL sont représentés comme en ASCII.
- Un caractère graphique ASCII (jeu de codes 0) est représenté par sa représentation habituelle sur un octet, dans la plage 0x21 – 0x7E. Bien que certaines variantes d'EUC-JP encodent ici la moitié inférieure de HTML5 , et EUC-JIS-2004 également . Cela signifie que 0x5C est généralement mappé en Unicode comme U+005C REVERSE SOLIDUS (la barre oblique inverse ASCII ). Cependant, U+005C peut être affiché comme le symbole du yen par certaines polices de caractères japonaises, par exemple sous Microsoft Windows, pour assurer la compatibilité avec la moitié inférieure de kana demi-largeur , jeu de caractères 2) est représenté par deux octets : le premier est 0x8E, le second correspond à la représentation des extensions spécifiques au fournisseur IBM dans certaines variantes.
- Un caractère de la norme JIS X 0212 (jeu de caractères 3) est représenté en EUC-JP par trois octets : le premier vaut 0x8F, les deux suivants étant compris entre 0xA1 et 0xFE (bit de poids fort activé). Outre la norme OSF . En EUC-JIS-2004, le second plan de la Python , autorisent à la fois les caractères Open Software Foundation , d'IBM ou de NEC ) étaient souvent allouées dans les ensembles de code individuels, par opposition à l'utilisation de séquences EUC invalides (comme dans les extensions populaires d'EUC-CN et d'EUC-KR).
Cependant, certains encodages spécifiques à certains fournisseurs sont partiellement compatibles avec l'EUC-JP, car ils encodent Digital Equipment Corporation définit deux variantes d'EUC-JP qui ne sont que partiellement conformes au format EUC compressé, mais qui présentent également une certaine ressemblance avec le format complet sur deux octets. Le format global de l'encodage « DEC Kanji » correspond en grande partie à l'EUC à longueur fixe (format complet sur deux octets) ; cependant, le jeu de codes 0 n'est pas nécessairement complété à gauche par des octets nuls (comme dans le format compressé). La norme JIS X 0208 est, comme d'habitude, utilisée pour le jeu de codes 1 ; le jeu de codes 2 (katakana demi-largeur) est absent. Le jeu de codes 3 est encodé comme le format à largeur fixe de deux octets (c'est-à-dire sans octet de décalage et avec seulement le premier bit de poids fort à 1), mais utilisé pour les caractères définis par l'utilisateur sur deux octets plutôt que d'être spécifié pour JIS X 0212. Dans l'encodage de base « DEC Kanji », seules les 31 premières lignes du jeu de codes 3 sont utilisées pour les caractères définis par l'utilisateur : les lignes 32 à 94 sont réservées, de la même manière que les lignes inutilisées du jeu de codes 1.
L’encodage « Super DEC Kanji » accepte les codes issus à la fois de l’encodage « DEC Kanji » et de l’EUC au format compacté, pour un total de cinq jeux de codes. Il permet également d’utiliser l’intégralité du jeu de codes défini par l’utilisateur, ainsi que les lignes inutilisées aux extrémités des jeux de codes JIS X 0208 et JIS X 0212 (lignes 85 à 94 et 78 à 94 respectivement), pour les caractères définis par l’utilisateur.
HP-16
Hewlett-Packard définit un encodage appelé « HP-16 ». Celui-ci accompagne leur encodage « HP-15 », qui est une variante de Shift JIS . HP-16 encode Data General ressemble à l'EUC-JP sans décalages simples, c'est-à-dire avec uniquement les jeux de codes 0 et 1. Les katakana demi-largeur sont quant à eux inclus dans la ligne 8 de la norme JIS X 0208 (entraînant un conflit avec les caractères de dessin de cases ajoutés à la norme en 1983). Les lignes 9 à 12 de la norme JIS X 0208 sont utilisées pour les caractères définis par l'utilisateur.
Adaptations de l'EUC-JP pour l'EBCDIC
espace idéographique : 0x4040 selon la structure de code DBCS-Host et 0xA1A1 comme dans EUC-JP. Ceci diffère de l'encodage DBCS-Host d'IBM pour le japonais, dont la structure repose sur des versions antérieures à JIS X 0208. La plage d'octets de tête est étendue jusqu'à 0x59, dont les octets de tête 0x81–A0 sont destinés aux caractères définis par l'utilisateur, et le reste est utilisé pour les caractères définis par l'entreprise, y compris les kanji et les non-kanji. JEF (Japanese-processing Extended Feature) est un codage EBCDIC utilisé sur les ordinateurs centraux Fujitsu FACOM, contrairement à FMR (une variante de Shift JIS) utilisé sur les PC Fujitsu. À l'instar de KEIS, JEF est un codage à état, basculant vers un mode DBCS-Host double octet à l'aide de séquences de décalage (où `<` de kuten , la ligne 162 (octet de tête 0x7E) étant inutilisée. Les lignes 101 à 148 sont utilisées pour les kanji étendus, tandis que les lignes 149 à 163 sont utilisées pour les caractères non-kanji étendus.
EUC-KR
Un caractère tiré de KS X 1001 (G1, jeu de codes 1) est encodé sur deux octets dans GR (0xA1–0xFE) et un caractère tiré de République de Corée , on l'appelle généralement Wansung ( RR : Wanseong ;
macOS , autres systèmes d'exploitation de type Unix et Windows), mais son utilisation se déplace très lentement vers l'UTF-8 à mesure que ce dernier gagne en popularité, notamment sous Linux et macOS.
Comme pour la plupart des autres encodages, l'UTF-8 est désormais privilégié pour les nouvelles utilisations, résolvant ainsi les problèmes de cohérence entre les plateformes et les fournisseurs.
Code Hangul unifié
Le code Hangul unifié étend l'EUC-KR en utilisant des codes non conformes à la structure de l'EUC pour intégrer des blocs syllabiques supplémentaires, complétant ainsi la couverture des blocs syllabiques composés disponibles dans Johab et Unicode. La norme d'encodage W3C / WHATWG utilisée par HTML5 intègre les extensions du code Hangul unifié dans sa définition de l'EUC-KR.
Mac OS coréen (HangulTalk)
D'autres encodages intégrant EUC-KR comme sous-ensemble incluent le script coréen de Mac OS (connu sous le nom de page de codes 10003 ou x-mac-korean), utilisé par HangulTalk (MacOS-KH), la localisation coréenne du Mac OS classique . Il a été développé par Elex Computer ( des dingbats stylisés indépendants du style de police . Nombre de ces caractères n'ont pas de correspondance Unicode exacte, et les logiciels Apple les associent de diverses manières : soit à des séquences combinatoires , soit à des correspondances approximatives avec un caractère à usage privé ajouté comme modificateur pour les allers-retours, soit à des caractères à usage privé.
Apple utilise également certains codes mono-octets en dehors du plan EUC-KR pour des caractères supplémentaires : 0x80 pour l’ espace obligatoire , 0x81 pour le symbole won (₩), 0x82 pour le tiret demi-cadratin ( – ), 0x83 pour le symbole de copyright ( trait de soulignement large ( points de suspension (...). Bien qu’aucun de ces codes mono-octets supplémentaires ne se situe dans la plage d’octets de tête de l’EUC-KR standard (contrairement aux extensions d’Apple pour l’EUC-CN, voir ci-dessus ), certains se situent dans la plage d’octets de tête du code Hangul unifié (plus précisément, 0x81, 0x82, 0x83 et 0x84).
EUC-KP
EUC-TH
Bien que certains codages mono-octets, tels que la série ISO/IEC 8859, soient techniquement conformes à la structure EUC, ils sont rarement désignés comme tels. Cependant, ce terme Solaris pour désigner TIS-620 .
EUC-TW
L'EUC-TW est un encodage à longueur variable prenant en charge l'ASCII et 16 plans du CNS 11643 , chacun de 94×94 pixels. Il est rarement utilisé pour les caractères chinois traditionnels tels qu'ils sont employés à Taïwan . Les variantes de Big5 sont beaucoup plus répandues que l'EUC-TW, bien que Big5 n'encode que les deux premiers plans du hanzi CNS 11643 , tandis que l'UTF-8 gagne en popularité.
- En tant qu'encodage EUC/ ISO 2022 , les caractères de contrôle C0 , l'espace ASCII et DEL sont encodés comme en ASCII.
- Un caractère graphique de l'ASCII (G0, jeu de codes 0) est encodé dans GL comme sa représentation habituelle sur un seul octet (0x21–0x7E).
- Un caractère du plan 1 du CNS 11643 (jeu de codes 1) est encodé sur deux octets en GR (0xA1–0xFE).
- Un caractère des plans 1 à 16 du CNS 11643 (jeu de codes 2) est encodé sur quatre octets :
- Le premier octet est toujours 0x8E (décalage simple 2).
- Le deuxième octet (0xA1–0xB0) indique le plan, dont le numéro est obtenu en soustrayant 0xA0 de cet octet.
- Les troisième et quatrième octets sont dans GR (0xA1–0xFE).
Notez que le plan 1 de CNS 11643 est codé deux fois, à la fois comme jeu de codes 1 et comme partie du jeu de codes 2.