théorie de l'information , les turbocodes sont une classe de codes de correction d'erreurs sans voie de retour (FEC) hautes performances , développés vers 1990-1991, mais publiés pour la première fois en 1993. Ils furent les premiers codes pratiques à approcher de près la capacité maximale du canal, ou limite de Shannon , un maximum théorique du débit de codage permettant une communication fiable pour un niveau de bruit donné. Les turbocodes sont utilisés dans les communications mobiles 3G / 4G (par exemple, UMTS et LTE ) et dans les communications par satellite (y compris dans l'espace lointain ) , ainsi que dans d'autres applications où les concepteurs cherchent à assurer un transfert d'informations fiable sur des liaisons de communication à bande passante ou latence limitées, en présence de bruit corrompant les données. Les turbocodes sont en concurrence avec les codes LDPC ( Low-Density Parity-Check ), qui offrent des performances similaires. Jusqu'à l'expiration du brevet des turbocodes , l'absence de brevet pour les codes LDPC a été un facteur important de leur pertinence continue
Le nom « code turbo » provient de la boucle de rétroaction utilisée lors du décodage normal du code turbo, qui a été comparée à la rétroaction des gaz d'échappement utilisée pour la suralimentation des moteurs . Hagenauer a soutenu que le terme « code turbo » est impropre puisqu'aucune rétroaction n'est impliquée dans le processus d'encodage.
Claude Berrou comme unique inventeur des turbocodes. Le dépôt de ce brevet a donné lieu à plusieurs brevets, dont le brevet américain n° 5 446 747 , qui a expiré le 29 août 2013.Le premier article public sur les turbocodes s'intitulait « Near Shannon Limit Error-correcting Coding and Decoding: Turbo-codes » . Publié en 1993 dans les actes de la Conférence internationale des communications de l'IEEE, cet article de 1993 était issu de la fusion de trois contributions distinctes, faute de place. Cette fusion a conduit à la présence de trois auteurs : Berrou, Glavieux et Thitimajshima (de l'IMT Atlantique, anciennement Télécom Bretagne, puis ENST Bretagne , France). Toutefois, il ressort clairement du dépôt de brevet original que Berrou est le seul inventeur des turbocodes et que les autres auteurs ont apporté des contributions autres que les concepts fondamentaux.les codes convolutifs concaténés en série et les codes à accumulation répétée . Des méthodes de décodage turbo itératives ont également été appliquées à des systèmes FEC plus conventionnels, tels que les codes convolutifs corrigés par Reed-Solomon, bien que ces systèmes soient trop complexes pour des implémentations pratiques de décodeurs itératifs. L'égalisation turbo découle également du concept de turbocodage.
Outre les turbocodes, Berrou a également inventé les codes convolutifs systématiques récursifs (RSC), utilisés dans l'exemple d'implémentation des turbocodes décrit dans le brevet. Les turbocodes utilisant des codes RSC semblent plus performants que ceux qui n'en utilisent pas.
Avant les turbocodes, les meilleures constructions étaient des codes concaténés en série basés sur un code de correction d'erreurs Reed-Solomon externe combiné à un code convolutif interne à courte longueur de contrainte décodé Viterbi , également connu sous le nom de codes RSV.
Dans un article ultérieur, Berrou a rendu hommage à l'intuition de « G. Battail, J. Hagenauer et P. Hoeher, qui, à la fin des années 80, ont souligné l'intérêt du traitement probabiliste ». Il ajoute : « R. Gallager et M. Tanner avaient déjà imaginé des techniques de codage et de décodage dont les principes généraux sont étroitement liés », bien que les calculs nécessaires fussent impraticables à cette époque.
Un exemple d'encodeur
Il existe de nombreuses variantes de turbocodes, utilisant différents encodeurs, rapports entrée/sortie, entrelaceurs et schémas de perforation . Cet exemple d'implémentation d'encodeur décrit un turbocodeur classique et illustre la conception générale des turbocodes parallèles.
Cette implémentation d'encodeur envoie trois sous-blocs de bits. Le premier sous-bloc correspond aux données utiles ( m bits). Le deuxième sous-bloc contient n/2 bits de parité pour ces données, calculés à l'aide d'un code convolutif systématique récursif (code RSC). Le troisième sous-bloc contient n/2 bits de parité pour une permutation connue des données utiles, également calculés à l'aide d'un code RSC. Ainsi, deux sous-blocs de bits de parité redondants mais différents sont envoyés avec les données utiles. Le bloc complet contient permutation des données utiles est effectuée par un entrelaceur .
Du point de vue matériel, cet encodeur de turbo code se compose de deux codeurs RSC identiques, C 1 et C 2 , comme illustré sur la figure, qui sont connectés entre eux à l'aide d'un schéma de concaténation, appelé concaténation parallèle :
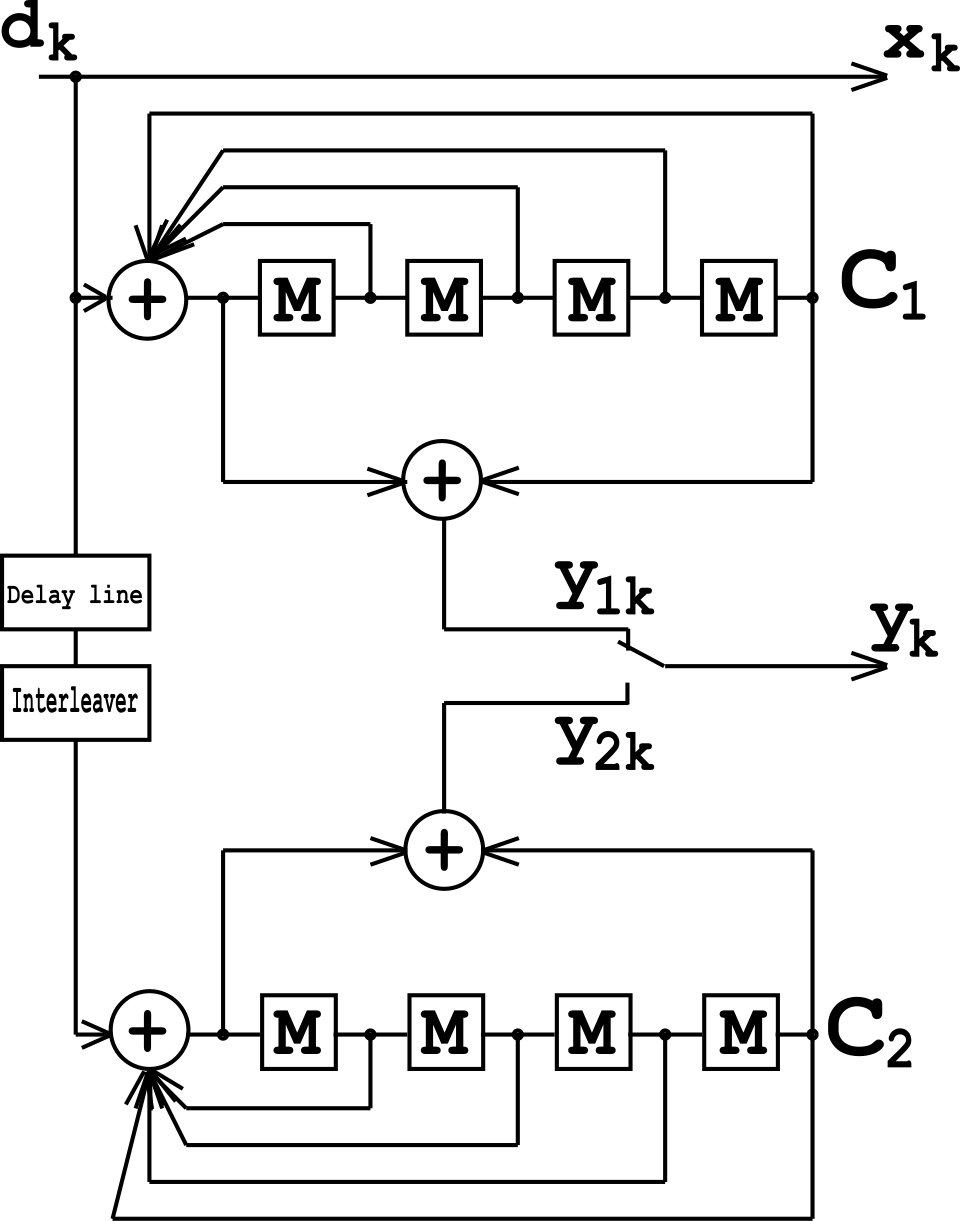
Sur la figure, M est un registre de mémoire. La ligne à retard et l'entrelaceur imposent aux bits d'entrée d<sub> k</sub> d'apparaître dans des séquences différentes. À la première itération, la séquence d'entrée d <sub> k </sub> apparaît aux deux sorties de l'encodeur, x <sub>k</sub> et y <sub>1k</sub> ou y <sub>2k</sub> , du fait de la nature systématique de l'encodeur. Si les encodeurs C <sub>1</sub> et C <sub>2</sub> sont utilisés respectivement lors des itérations n <sub>1</sub> et n<sub> 2</sub> , leurs taux sont égaux à :
Le décodeur
Le décodeur est construit de manière similaire à l'encodeur décrit précédemment. Deux décodeurs élémentaires sont interconnectés en série, et non en parallèle. Fonctionnant à une vitesse inférieure (soit 10 Hz), il est conçu pour l' encodeur et, par conséquent, pour le décodeur. La sortie du décodeur produit une décision souple , ce qui induit un délai. Ce même délai est causé par la ligne à retard de l'encodeur. Le fonctionnement du décodeur provoque donc un délai.
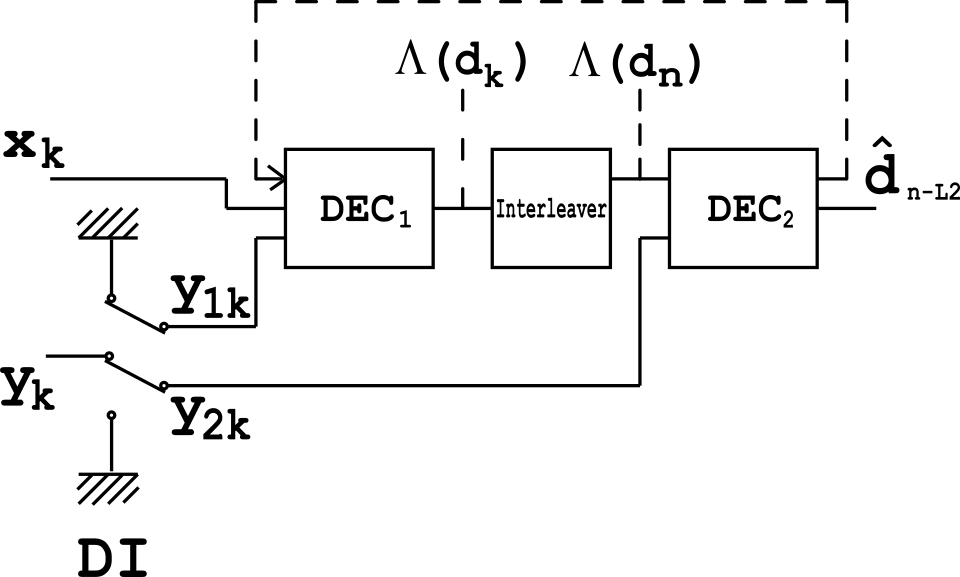
Un entrelaceur installé entre les deux décodeurs est utilisé ici pour disperser les rafales d'erreurs provenant de la sortie. Le bloc DI est un module de démultiplexage et d'insertion. Il fonctionne comme un commutateur, redirigeant les bits d'entrée vers une entrée à un instant donné et vers une autre à un autre. À l'état OFF, il alimente les deux entrées avec des bits de remplissage (zéros).
Considérons un canal AWGN sans mémoire , et supposons qu'à la k -ième itération, le décodeur reçoive une paire de variables aléatoires :
où et sont des composantes de bruit indépendantes ayant la même variance . est un k -ième bit de la sortie de l'encodeur.
Les informations redondantes sont démultiplexées et envoyées via DI à (lorsque ) et à (lorsque ).
et le transmet à . est appelé le logarithme du rapport de vraisemblance (LLR). est la probabilité a posteriori (APP) du bit de données, qui indique la probabilité d'interpréter un bit reçu comme . En tenant compte du LLR , on obtient une décision définitive ; c'est-à-dire un bit décodé.
L' algorithme de Viterbi étant incapable de calculer l'APP, il ne peut être utilisé dans ce cas . On utilise alors un algorithme BCJR modifié. Pour ce dernier , l' algorithme de Viterbi est approprié.
Cependant, la structure représentée n'est pas optimale, car elle n'exploite qu'une fraction suffisante des informations redondantes disponibles. Afin d'améliorer cette structure, une boucle de rétroaction est mise en œuvre (voir la ligne pointillée sur la figure).
Approche décisionnelle souple
L'étage d'entrée du décodeur produit un entier pour chaque bit du flux de données. Cet entier, appelé bit souple , mesure la probabilité que le bit soit un 0 ou un 1. Il peut être tiré dans l'intervalle [−127, 127], où :
- −127 signifie « certainement 0 ».
- −100 signifie « très probablement 0 »
- 0 signifie « cela peut être soit 0, soit 1 ».
- 100 signifie « très probablement 1 »
- 127 signifie « certainement 1 »
Cela introduit un aspect probabiliste dans le flux de données provenant du front-end, mais cela transmet plus d'informations sur chaque bit que simplement 0 ou 1.
Par exemple, pour chaque bit, l'étage d'entrée d'un récepteur sans fil classique doit déterminer si une tension analogique interne est supérieure ou inférieure à un seuil donné. Pour un décodeur de turbocode, l'étage d'entrée fournirait une valeur entière indiquant l'écart entre la tension interne et le seuil donné.
Pour décoder le bloc de données de les mots croisés ou le sudoku . Prenons l'exemple d'une grille de mots croisés partiellement remplie, voire brouillée. Deux personnes tentent de la résoudre : l'une ne possède que les définitions verticales (bits de parité), l'autre que les définitions horizontales. Au départ, chacune émet des hypothèses sur les réponses à ses propres définitions, en notant son degré de certitude pour chaque lettre (bit utile). Ensuite, elles comparent leurs réponses et leurs niveaux de confiance, en observant leurs divergences. Fortes de ces nouvelles informations, elles proposent des réponses et des niveaux de confiance mis à jour, et répètent le processus jusqu'à parvenir à la même solution.
Performance
Les turbocodes offrent de bonnes performances grâce à la combinaison avantageuse de leur apparition aléatoire sur le canal et de leur structure de décodage physiquement réalisable. Les turbocodes sont toutefois sujets à un plancher d'erreur .
Applications pratiques utilisant les turbocodes
Télécommunications :
- Les turbocodes sont largement utilisés dans les normes de téléphonie mobile 3G et 4G ; par exemple, dans HSPA , EV-DO et LTE .
- MediaFLO , système de télévision mobile terrestre de Qualcomm .
- Le canal d’interaction des systèmes de communication par satellite , tels que DVB-RCS et DVB-RCS2 .
- Des missions récentes de la NASA , telles que Mars Reconnaissance Orbiter, utilisent des turbocodes comme alternative aux codes de correction d'erreurs Reed-Solomon - décodeur Viterbi .
- La norme IEEE 802.16 ( WiMAX ), une norme de réseau métropolitain sans fil, utilise le codage turbo par blocs et le codage turbo convolutionnel.
formulation bayésienne
Du point de vue de l'intelligence artificielle , les turbo codes peuvent être considérés comme un exemple de propagation de croyances en boucle dans les réseaux bayésiens .