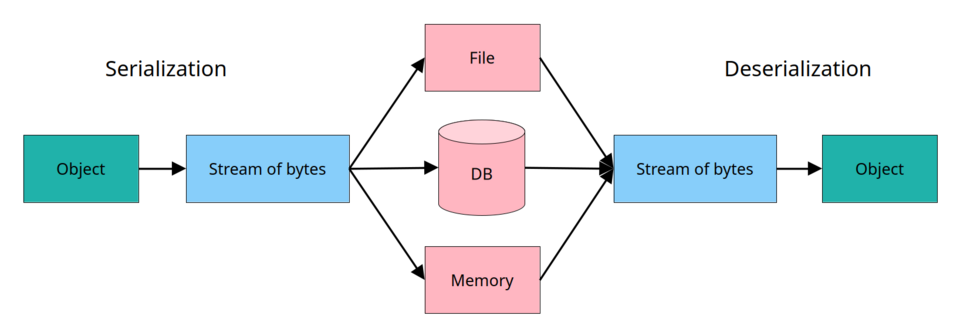
En informatique, la sérialisation (ou pickling en Python ) est le processus de conversion d'une structure de données ou de l'état d'un objet en un format stockable ( fichiers sur des périphériques de stockage secondaires , tampons de données sur des périphériques de stockage primaires) ou transmissible ( flux de données sur des réseaux informatiques ) et reconstruisible ultérieurement (éventuellement dans un environnement informatique différent). La relecture de la suite de bits résultante, selon le format de sérialisation, permet de créer un clone sémantiquement identique de l'objet original. Pour de nombreux objets complexes, notamment ceux qui utilisent abondamment des références , ce processus n'est pas simple. La sérialisation des objets n'inclut pas les méthodes qui leur étaient associées auparavant.
Ce processus de sérialisation d'un objet est également appelé marshalling dans certaines situations. L'opération inverse, l'extraction d'une structure de données à partir d'une série d'octets, est la désérialisation (également appelée unserialisation ou unmarshalling ).
Dans le matériel des équipements de réseau, la partie responsable de la sérialisation et de la désérialisation est communément appelée SerDes .
Utilisations
La sérialisation peut notamment être utilisée pour :
- transfert à travers les câbles et les réseaux ( messagerie ).
- stockage de données (dans des bases de données , sur des disques durs ).
- appels de procédure à distance , par exemple, comme dans SOAP .
- distribution d'objets, notamment dans le génie logiciel à base de composants tels que COM , CORBA , etc.
- Détection des changements dans les données variant dans le temps.
Pour que certaines de ces fonctionnalités soient utiles, l'indépendance de l'architecture doit être préservée. Par exemple, pour une utilisation optimale de la distribution, un ordinateur fonctionnant sur une architecture matérielle différente doit pouvoir reconstruire de manière fiable un flux de données sérialisé, quelle que soit l' endianness . Cela signifie que la méthode plus simple et plus rapide consistant à copier directement l'organisation mémoire de la structure de données ne peut pas fonctionner de manière fiable pour toutes les architectures. La sérialisation de la structure de données dans un format indépendant de l'architecture permet d'éviter les problèmes liés à l'ordre des octets , à l'organisation mémoire ou simplement aux différentes manières de représenter les structures de données dans différents langages de programmation .
Par définition, tout système de sérialisation implique que l'extraction d'une partie de la structure de données sérialisée nécessite la lecture et la reconstruction de l'objet entier, du début à la fin. Dans de nombreuses applications, cette linéarité est un atout, car elle permet d'utiliser des interfaces d'entrée/sortie simples et courantes pour stocker et transmettre l'état d'un objet. En revanche, dans les applications où les performances sont primordiales, il peut être judicieux d'investir davantage d'efforts dans une organisation du stockage plus complexe et non linéaire.
Même sur une seule machine, les objets pointeurs primitifs sont trop fragiles pour être sauvegardés, car les objets qu'ils pointent peuvent être rechargés à un autre emplacement en mémoire. Pour pallier ce problème, le processus de sérialisation comprend une étape appelée « déséquilibrage » ou « déséquilibrage des pointeurs » , où les références directes par pointeur sont converties en références basées sur le nom ou la position. Le processus de désérialisation comprend une étape inverse appelée « déséquilibrage des pointeurs » .
Puisque la sérialisation et la désérialisation peuvent être gérées par un code commun (par exemple, la fonction Serialize des Microsoft Foundation Classes ), ce code peut effectuer les deux opérations simultanément et ainsi : 1) détecter les différences entre les objets en cours de sérialisation et leurs copies précédentes, et 2) fournir les données nécessaires à la détection suivante. Il n’est pas nécessaire de reconstituer la copie précédente, car les différences peuvent être détectées à la volée, une technique appelée exécution différentielle. Ceci est particulièrement utile pour la programmation d’interfaces utilisateur dont le contenu évolue dans le temps : les objets graphiques peuvent être créés, supprimés, modifiés ou configurés pour gérer des événements d’entrée sans qu’il soit nécessaire d’écrire du code spécifique.
Inconvénients
La sérialisation rompt l’opacité d’un type de données abstrait en exposant potentiellement des détails d’implémentation privés. Les implémentations triviales qui sérialisent tous les membres de données peuvent violer l’encapsulation .
Pour dissuader leurs concurrents de développer des produits compatibles, les éditeurs de logiciels propriétaires gardent souvent secrets commerciaux les détails des formats de sérialisation de leurs programmes . Certains vont jusqu'à obscurcir , voire chiffrer, les données sérialisées. Or, l'interopérabilité exige que les applications puissent comprendre les formats de sérialisation des autres. C'est pourquoi les architectures d'appel de méthodes distantes, telles que CORBA, définissent précisément leurs formats de sérialisation.
De nombreuses institutions, telles que les archives et les bibliothèques, tentent de pérenniser leurs archives de sauvegarde — en particulier les sauvegardes de bases de données — en les stockant dans un format sérialisé relativement lisible par l'homme .
Formats de sérialisation
La technologie Xerox Network Systems Courier du début des années 1980 a influencé la première norme largement adoptée. Sun Microsystems a publié l' External Data Representation (XDR) en 1987. XDR est un format ouvert et normalisé sous la norme STD 67 (RFC 4506) par l'IETF .
À la fin des années 1990, un mouvement s'est développé pour proposer une alternative aux protocoles de sérialisation standard : XML , un sous-ensemble de SGML , a été utilisé pour produire un encodage textuel lisible par l'humain . Un tel encodage peut s'avérer utile pour les objets persistants, susceptibles d'être lus et compris par les humains ou communiqués à d'autres systèmes, indépendamment du langage de programmation. Il présente l'inconvénient de perdre la compacité de l'encodage par flux d'octets, mais à cette époque, les capacités de stockage et de transmission accrues rendaient la taille des fichiers moins problématique qu'aux débuts de l'informatique. Dans les années 2000, XML était fréquemment utilisé pour le transfert asynchrone de données structurées entre le client et le serveur dans les applications web Ajax . XML est un format ouvert et normalisé par le W3C.
JSON est une alternative légère et textuelle à XML, couramment utilisée pour la communication client-serveur dans les applications web. Basé sur la syntaxe JavaScript, JSON est néanmoins indépendant de ce langage et pris en charge par de nombreux autres langages de programmation. JSON est normalisé par les normes STD 90 ( RFC 8259 ), ECMA-404 et ISO/IEC 21778:2017 .
YAML est un sur-ensemble strict de JSON et inclut des fonctionnalités supplémentaires telles que des balises de type de données, la prise en charge des structures de données cycliques, une syntaxe sensible à l'indentation et plusieurs formes de guillemets pour les données scalaires. YAML est un format ouvert.
Les listes de propriétés sont utilisées pour la sérialisation par NeXTSTEP , GNUstep , macOS et les frameworks iOS . Le terme « liste de propriétés » (ou « p-list ») ne désigne pas un format de sérialisation unique, mais plusieurs variantes : certaines lisibles par l’humain et une binaire.
Pour les ensembles de données scientifiques volumineux, tels que les données satellitaires et les résultats des modèles numériques climatiques, météorologiques ou océaniques, des normes de sérialisation binaire spécifiques ont été développées, par exemple HDF , netCDF et l'ancien GRIB .
Prise en charge des langages de programmation
Plusieurs langages de programmation orientés objet prennent directement en charge la sérialisation (ou l'archivage ) d'objets, soit par des raccourcis syntaxiques , soit en fournissant une interface standard . Parmi ces langages figurent Ruby , Smalltalk , Python , PHP , Objective-C , Delphi , Java et la famille de langages .NET . Des bibliothèques permettent également d'ajouter la prise en charge de la sérialisation aux langages qui ne la prennent pas en charge nativement.
C et C++
C et C++ ne proposent pas de sérialisation en tant que mécanisme de haut niveau, mais les deux langages permettent d'écrire n'importe quel type de données intégré , ainsi que les structures de données classiques , sous forme de données binaires. De ce fait, il est généralement simple d'écrire des fonctions de sérialisation personnalisées. De plus, les solutions basées sur le compilateur, telles que le système ORM ODB pour C++ et la boîte à outils gSOAP pour C et C++, sont capables de générer automatiquement le code de sérialisation avec peu ou pas de modifications des déclarations de classes. Parmi les autres frameworks de sérialisation populaires, on peut citer Boost.Serialization du framework Boost , le framework S11n et Cereal . Le framework MFC (Microsoft) fournit également une méthodologie de sérialisation dans le cadre de son architecture Document-View.
L’introduction de la programmation réflexive dans C++26 a considérablement simplifié la sérialisation. La réflexion permet la sérialisation à la compilation, par exemple, de JSON en un objet structpossédant une structure correspondante.
CFML
CFML permet de sérialiser des structures de données au format WDDX grâce à la <cfwddx>balise et au format JSON grâce à la fonction SerializeJSON() .
Delphes
Delphi propose un mécanisme intégré de sérialisation des composants (également appelés objets persistants), entièrement intégré à son EDI . Le contenu du composant est enregistré dans un fichier DFM et rechargé à la volée.
Aller
Go prend en charge nativement la désérialisation/sérialisation des données JSON et XML . Des modules tiers prennent également en charge YAML et Protocol Buffers . Go prend également en charge Gobs .
Haskell
En Haskell, la sérialisation est prise en charge pour les types appartenant aux classes `Read` et `Show` . Chaque type membre de cette Readclasse définit une fonction permettant d'extraire les données de leur représentation sous forme de chaîne. La Showclasse `Read` contient elle-même la showfonction permettant de générer une représentation sous forme de chaîne de l'objet. Le programmeur n'a pas besoin de définir explicitement ces fonctions : déclarer un type comme dérivant de `Read` ou de `Show`, voire des deux, suffit généralement au compilateur pour générer les fonctions appropriées (mais pas systématiquement : les types fonctionnels, par exemple, ne peuvent pas dériver automatiquement de `Show` ou de `Read`). L'instance générée automatiquement pour `Show` produit également du code source valide ; ainsi, la même valeur Haskell peut être obtenue en exécutant le code produit par `show` dans un interpréteur Haskell, par exemple. Pour une sérialisation plus efficace, des bibliothèques Haskell permettent une sérialisation rapide au format binaire, comme `binary` .
Java
Java offre une sérialisation automatique qui requiert que l'objet soit marqué comme sérialisable par l'implémentation de l' java.io.Serializableinterface `Serializable`. L'implémentation de cette interface indique que la classe est « sérialisable », et Java gère alors la sérialisation en interne. L' Serializableinterface `Serializable` ne définit aucune méthode de sérialisation, mais une classe sérialisable peut définir des méthodes avec des noms et des signatures spécifiques qui, si elles sont définies, seront appelées lors du processus de sérialisation/désérialisation. Le langage permet également au développeur de personnaliser davantage le processus de sérialisation en implémentant une autre interface, ` ExternalizableSerializable`, qui inclut deux méthodes spéciales permettant de sauvegarder et de restaurer l'état de l'objet. Il existe trois raisons principales pour lesquelles les objets ne sont pas sérialisables par défaut et doivent implémenter l' Serializableinterface `Serializable` pour accéder au mécanisme de sérialisation de Java. Premièrement, tous les objets ne conservent pas de sémantique utile dans un état sérialisé. Par exemple, un Threadobjet est lié à l'état de la JVM courante . Il n'existe aucun contexte dans lequel un Threadobjet désérialisé conserverait une sémantique utile. Deuxièmement, l'état sérialisé d'un objet fait partie du contrat de compatibilité de sa classe. Maintenir la compatibilité entre les versions de classes sérialisables exige des efforts et une réflexion supplémentaires. Par conséquent, rendre une classe sérialisable doit être un choix de conception délibéré et non une condition par défaut. Enfin, la sérialisation permet d'accéder aux membres privés non transitoires d'une classe qui ne sont pas accessibles autrement. Les classes contenant des informations sensibles (par exemple, un mot de passe) ne doivent être ni sérialisables ni externalisables. La méthode d'encodage standard utilise une traduction récursive, basée sur un graphe, du descripteur de classe de l'objet et des champs sérialisables en un flux d'octets. Les types primitifs ainsi que les objets référencés non transitoires et non statiques sont encodés dans le flux. Chaque objet référencé par l'objet sérialisé via un champ non marqué comme transientsérialisable doit également l'être ; et si un objet quelconque du graphe complet des références d'objets non transitoires n'est pas sérialisable, la sérialisation échouera. Le développeur peut influencer ce comportement en marquant les objets comme transitoires, ou en redéfinissant la sérialisation d'un objet afin qu'une partie du graphe de référence soit tronquée et non sérialisée. Java n'utilise pas de constructeur pour sérialiser les objets. Il est possible de sérialiser des objets Java via JDBC et de les stocker dans une base de données. Tandis que SwingBien que les composants implémentent l'interface Serializable, leur portabilité entre différentes versions de la machine virtuelle Java n'est pas garantie. Ainsi, un composant Swing, ou tout composant qui en hérite, peut être sérialisé en un flux d'octets, mais sa reconstitution sur une autre machine n'est pas assurée.
JavaScript
Depuis ECMAScript 5.1, JavaScript inclut l'objet intégré `JSON` JSONet ses méthodes `get` JSON.parse()et `get` JSON.stringify(). Bien que JSON soit initialement basé sur un sous-ensemble de JavaScript, il existe des cas limites où JSON n'est pas du JavaScript valide. Plus précisément, JSON autorise l' affichage non échappé des caractères de fin de ligne Unicode U+2028 ( SÉPARATEUR DE LIGNE) et U+2029 (SÉPARATEUR DE PARAGRAPHE) dans les chaînes entre guillemets, contrairement à ECMAScript 2018 et aux versions antérieures. Voir l'article principal sur JSON .
Julia
Julia implémente la sérialisation via les modules serialize()`/` , conçus pour fonctionner au sein d'une même version de Julia et/ou d'une même instance de l'image système. Le package offre une alternative plus stable, utilisant un format documenté et une bibliothèque commune avec des wrappers pour différents langages, tandis que le format de sérialisation par défaut semble avoir été conçu pour optimiser les performances de communication réseau. deserialize()HDF5.jl
Zézayer
Generally a Lisp data structure can be serialized with the functions "read" and "print". A variable foo containing, for example, a list of arrays would be printed by (print foo). Similarly an object can be read from a stream named s by (read s). These two parts of the Lisp implementation are called the Printer and the Reader. The output of "print" is human readable; it uses lists demarked by parentheses, for example: (42.9"x"y). In many types of Lisp, including Common Lisp, the printer cannot represent every type of data because it is not clear how to do so. In Common Lisp for example the printer cannot print CLOS objects. Instead the programmer may write a method on the generic function print-object, this will be invoked when the object is printed. This is somewhat similar to the method used in Ruby. Lisp code itself is written in the syntax of the reader, called read syntax. Most languages use separate and different parsers to deal with code and data, Lisp only uses one. A file containing lisp code may be read into memory as a data structure, transformed by another program, then possibly executed or written out, such as in a read–eval–print loop. Not all readers/writers support cyclic, recursive or shared structures.
.NET
.NET has several serializers designed by Microsoft. There are also many serializers by third parties. More than a dozen serializers are discussed and tested hereArchived 2015-05-08 at the Wayback Machine. and here
OCaml
OCaml's standard library provides marshalling through the Marshal module and the Pervasives functions output_value and input_value. While OCaml programming is statically type-checked, uses of the Marshal module may break type guarantees, as there is no way to check whether an unmarshalled stream represents objects of the expected type. In OCaml it is difficult to marshal a function or a data structure which contains a function (e.g. an object which contains a method), because executable code in functions cannot be transmitted across different programs. (There is a flag to marshal the code position of a function but it can only be unmarshalled in exactly the same program). The standard marshalling functions can preserve sharing and handle cyclic data, which can be configured by a flag.
Perl
Plusieurs modules Perl disponibles sur CPAN offrent des mécanismes de sérialisation, notamment `serialize` Storable, `serialize` JSON::XSet ` FreezeThawserialize`. `storable` inclut des fonctions pour sérialiser et désérialiser des structures de données Perl depuis et vers des fichiers ou des scalaires Perl. Outre la sérialisation directe vers des fichiers, `storable` Storableinclut la freezefonction `serialize` pour renvoyer une copie sérialisée des données encapsulées dans un scalaire, et thawla fonction `deserialize` pour désérialiser un tel scalaire. Ceci est utile pour envoyer une structure de données complexe via un socket réseau ou pour la stocker dans une base de données. Lors de la sérialisation de structures avec `storable` Storable, des fonctions réseau sécurisées stockent toujours leurs données dans un format lisible par n'importe quel ordinateur, moyennant une légère perte de vitesse. Ces fonctions sont nommées `serialize` nstore, `serialize` nfreeze, `serialize`, etc. Il n'existe pas de fonctions « n » pour désérialiser ces structures ; les fonctions `serialize` thawet retrieve`serialize` désérialisent les structures sérialisées avec les nfonctions « n » et leurs équivalents spécifiques à la machine.
PHP
PHP implémentait initialement la sérialisation via les fonctions intégrées `serialize` serialize()et `deserialize`. PHP peut sérialiser tous ses types de données, à l'exception des ressources (pointeurs de fichiers, sockets, etc.). La fonction intégrée `serialize` est souvent dangereuse lorsqu'elle est utilisée sur des données totalement non fiables. Pour les objets, deux « méthodes magiques » peuvent être implémentées au sein d'une classe : ` cleanup` et `restor`. Appelées respectivement depuis ` serialize` et `restorize`, elles permettent de nettoyer et de restaurer un objet. Par exemple, il peut être souhaitable de fermer une connexion à une base de données lors de la sérialisation et de la rétablir lors de la désérialisation ; cette fonctionnalité est gérée par ces deux méthodes magiques. Elles permettent également à l'objet de choisir les propriétés à sérialiser. Depuis PHP 5.1, un mécanisme de sérialisation orienté objet est disponible pour les objets : l' interface `Serialize`. unserialize()unserialize()__sleep()__wakeup()serialize()unserialize()Serializable
Prologue
La structure de termes de Prolog , unique structure de données du langage, peut être sérialisée via le prédicat intégré `serialize` write_term/3et `serialize` via les prédicats intégrés `serialize` read/1et ` read_term/2serialize`. Le flux résultant est un texte non compressé (dans un encodage déterminé par la configuration du flux cible), où les variables libres du terme sont représentées par des noms de variables génériques. Le prédicat `serialize` write_term/3est normalisé dans la spécification ISO pour Prolog (ISO/IEC 13211-1), pages 59 et suivantes (« Écriture d'un terme, § 7.10.5 »). Par conséquent, on s'attend à ce que les termes sérialisés par une implémentation puissent être sérialisés par une autre sans ambiguïté ni surprise. En pratique, les extensions spécifiques à l'implémentation (par exemple, les dictionnaires de SWI-Prolog) peuvent utiliser des structures de termes non standard, ce qui peut entraîner des problèmes d'interopérabilité dans certains cas particuliers. À titre d'exemple, voir les pages de manuel correspondantes pour SWI-Prolog, SICStus Prolog et GNU Prolog. Il appartient à l'implémenteur de décider si et comment les termes sérialisés reçus sur le réseau sont vérifiés par rapport à une spécification (après désérialisation du flux de caractères). Les grammaires de clauses définies intégrées à Prolog peuvent être utilisées à ce stade.
Python
Le mécanisme de sérialisation général principal est le module picklede la bibliothèque standard , faisant référence au terme « pickling » utilisé dans les systèmes de bases de données pour décrire la sérialisation des données ( et la désérialisation , ou « unpickling »). Pickle utilise une machine virtuelle simple basée sur une pile qui enregistre les instructions nécessaires à la reconstruction de l'objet. Il s'agit d'un format de sérialisation multiversion personnalisable , mais non sécurisé (non protégé contre les données erronées ou malveillantes). Des données malformées ou construites de manière malveillante peuvent amener le désérialiseur à importer des modules arbitraires et à instancier n'importe quel objet . La bibliothèque standard inclut également des modules permettant la sérialisation vers des formats de données standard : (avec prise en charge intégrée des types scalaires et collections de base, et capable de prendre en charge des types arbitraires via des points d'entrée d'encodage et de décodage ) ; (avec prise en charge des formats de listes de propriétés binaires et XML ) ; (avec prise en charge de la norme XDR (External Data Representation) décrite dans la RFC 1014). Enfin, il est recommandé qu'un objet soit évaluable dans l'environnement approprié, ce qui correspond approximativement à celui de Common Lisp . Tous les types d'objets ne peuvent pas être sérialisés automatiquement, notamment ceux qui contiennent des ressources du système d'exploitation comme des descripteurs de fichiers . Cependant, les utilisateurs peuvent enregistrer des fonctions de « réduction » et de construction personnalisées pour prendre en charge la sérialisation et la désérialisation de types arbitraires. Pickle a été initialement implémenté comme un module Python pur, mais, dans les versions de Python antérieures à 3.0, le module (également intégré) offre des performances améliorées (jusqu'à 1 000 fois plus rapides ). Il a été adapté du projet Unladen Swallow . En Python 3, les utilisateurs doivent toujours importer la version standard, qui tente d'importer la version accélérée et utilise la version Python pure en cas d'échec. jsonplistlibxdrlib__repr__print-objectpicklecPicklecPickle
R
R possède une fonction dputqui écrit une représentation textuelle ASCII d'un objet R dans un fichier ou une connexion. Cette représentation peut être lue depuis un fichier à l'aide de dget . Plus précisément, la fonction sérialise un objet R sur une connexion, le résultat étant un vecteur brut codé en hexadécimal. La fonction permet de lire un objet depuis une connexion ou un vecteur brut. serializeunserialize
REBOL
REBOL sérialise les données dans un fichier ( save/all) ou dans un objet string!( mold/all). Les chaînes de caractères et les fichiers peuvent être désérialisés à l'aide de la fonction polymorphe . permet la sérialisation de données interlangage en R, grâce aux Protocol Buffers . loadRProtoBuf
Rubis
Ruby inclut le module standard `serialize` Marshalavec deux méthodes `serialize` dumpet load`serialize`, similaires aux utilitaires Unix standard `serialize` dumpet restore`serialize`. Ces méthodes sérialisent les objets en une classe `Serialize` String, c'est-à-dire qu'ils deviennent une séquence d'octets. Certains objets ne peuvent pas être sérialisés (une TypeErrorexception serait levée) : les liaisons, les objets de procédure, les instances de la classe `IO`, les objets singleton et les interfaces. Si une classe nécessite une sérialisation personnalisée (par exemple, pour effectuer des actions de nettoyage lors de la sérialisation/restauration), cela peut se faire en implémentant deux méthodes : `serialize` _dumpet `serialize` _load. La méthode d'instance_dump doit retourner un Stringobjet `Serialize` contenant toutes les informations nécessaires à la reconstitution des objets de cette classe et de tous les objets référencés jusqu'à une profondeur maximale spécifiée par un paramètre entier (une valeur de -1 désactive la vérification de la profondeur). La méthode de classe_load doit prendre un `Serialize` Stringet retourner un objet `Serialize` de cette classe.
Rouiller
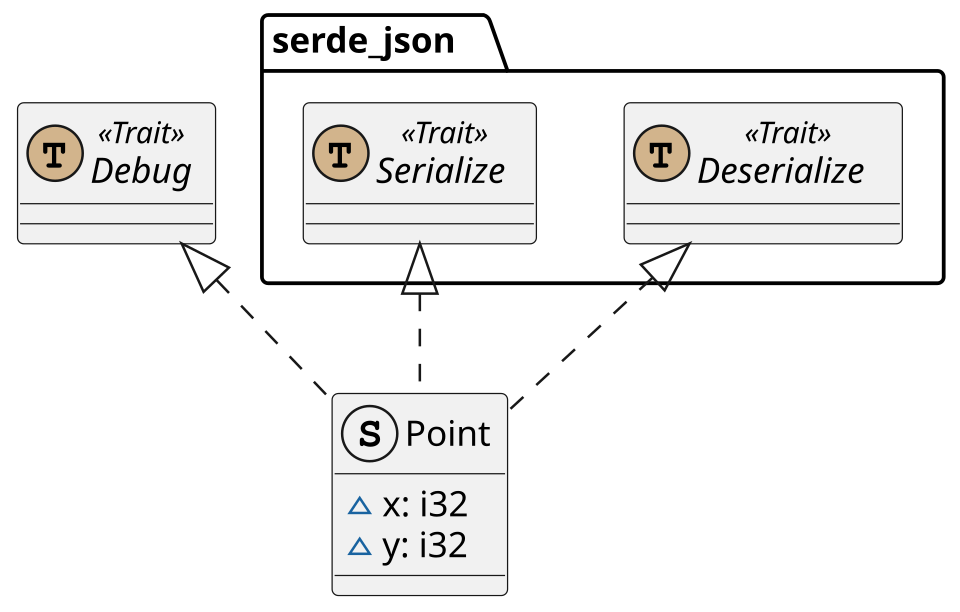
Pointimplémente les traits SerializeetDeserializeSerdeest la bibliothèque, ou crate, la plus largement utilisée pour la sérialisation en Rust qui fournit les traits Serializeet Deserialize.
Conversation
En général, les objets non récursifs et non partagés peuvent être stockés et récupérés sous une forme lisible par l'humain grâce au protocole storeOn:`/` . Cette méthode génère le texte d'une expression Smalltalk qui, une fois évaluée , recrée l'objet original. Ce schéma est particulier car il utilise une description procédurale de l'objet, et non les données elles-mêmes. Il est donc très flexible, permettant aux classes de définir des représentations plus compactes. Cependant, dans sa forme originale, il ne gère pas les structures de données cycliques ni ne préserve l'identité des références partagées (c'est-à-dire que deux références à un même objet seront restaurées comme des références à deux copies égales, mais non identiques). Pour pallier ce problème, il existe diverses alternatives, portables ou non. Certaines sont spécifiques à une implémentation Smalltalk ou à une bibliothèque de classes particulière. Squeak Smalltalk propose plusieurs méthodes pour sérialiser et stocker des objets. Les plus simples et les plus utilisées sont les formats de stockage binaires basés sur des sérialiseurs. De plus, les objets groupés peuvent être stockés et récupérés à l'aide de `/` . Ces deux méthodes fournissent un « cadre de stockage d'objets binaires », qui prend en charge la sérialisation et la récupération à partir d'une forme binaire compacte. Les deux langages gèrent les structures cycliques, récursives et partagées, le stockage et la récupération des informations de classe et de métaclasse , et incluent des mécanismes de migration d'objets à la volée (c'est-à-dire la conversion d'instances écrites par une version antérieure d'une classe avec une structure d'objets différente). Les API sont similaires (storeBinary/readBinary), mais les détails d'encodage diffèrent, rendant ces deux formats incompatibles. Cependant, le code Smalltalk/X est libre et gratuit, et peut être chargé dans d'autres implémentations Smalltalk pour permettre l'échange d'objets entre dialectes. La sérialisation d'objets ne fait pas partie de la spécification ANSI Smalltalk. Par conséquent, le code de sérialisation d'un objet varie selon l'implémentation Smalltalk. Les données binaires résultantes varient également. Par exemple, un objet sérialisé créé avec Squeak Smalltalk ne peut pas être restauré avec Ambrai Smalltalk . De ce fait, diverses applications fonctionnant sur plusieurs implémentations Smalltalk et reposant sur la sérialisation d'objets ne peuvent pas partager de données entre ces différentes implémentations. Parmi ces applications figurent la base de données d'objets MinneStore et certains packages RPC . Une solution à ce problème est SIXX, qui est un package pour plusieurs Smalltalks qui utilise un format basé sur XML pour la sérialisation. readFrom:storeOn:readFrom:storeOn:/readFrom:SmartRefStreamImageSegments
Rapide
La bibliothèque standard Swift fournit deux protocoles, Encodableet Decodable(composés ensemble sous la forme Codable), qui permettent de sérialiser ou de désérialiser des instances de types conformes au format JSON , listes de propriétés ou autres formats. Des implémentations par défaut de ces protocoles peuvent être générées par le compilateur pour les types dont les propriétés stockées sont également Decodableou Encodable.
PowerShell
PowerShell implémente la sérialisation via l' applet de commande intégrée `serialize`Export-CliXML . Export-CliXMLCette dernière sérialise les objets .NET et enregistre le XML résultant dans un fichier. Pour reconstituer les objets, utilisez l' Import-CliXMLapplet de commande `deserialize`, qui génère un objet désérialisé à partir du XML du fichier exporté. Les objets désérialisés, souvent appelés « sacs de propriétés », ne sont pas des objets dynamiques ; ce sont des instantanés qui possèdent des propriétés, mais aucune méthode. Les structures de données bidimensionnelles peuvent également être (dé)sérialisées au format CSV à l'aide des applets de commande intégrées `serialize` Import-CSVet ` deserialize` Export-CSV.