Algorithmes
Tri et sélection de tas
L'algorithme de base pour sélectionner la
- Trier la collection
- Si le résultat de l' algorithme de tri est un tableau , récupérez son
Le temps d'exécution de cette méthode est principalement dû à l'étape de tri, qui nécessite un temps d'exécution important avec un tri par comparaisonde tri d'entiers peuvent être utilisés, ils sont généralement plus lents que le temps linéaire pouvant être atteint avec des algorithmes de sélection spécialisés. Néanmoins, la simplicité de cette approche la rend attrayante, notamment lorsqu'une routine de tri hautement optimisée est fournie par la bibliothèque d'exécution, contrairement à l'algorithme de sélection. Pour des entrées de taille modérée, le tri peut être plus rapide que les algorithmes de sélection non aléatoires, en raison des facteurs constants plus faibles dans son
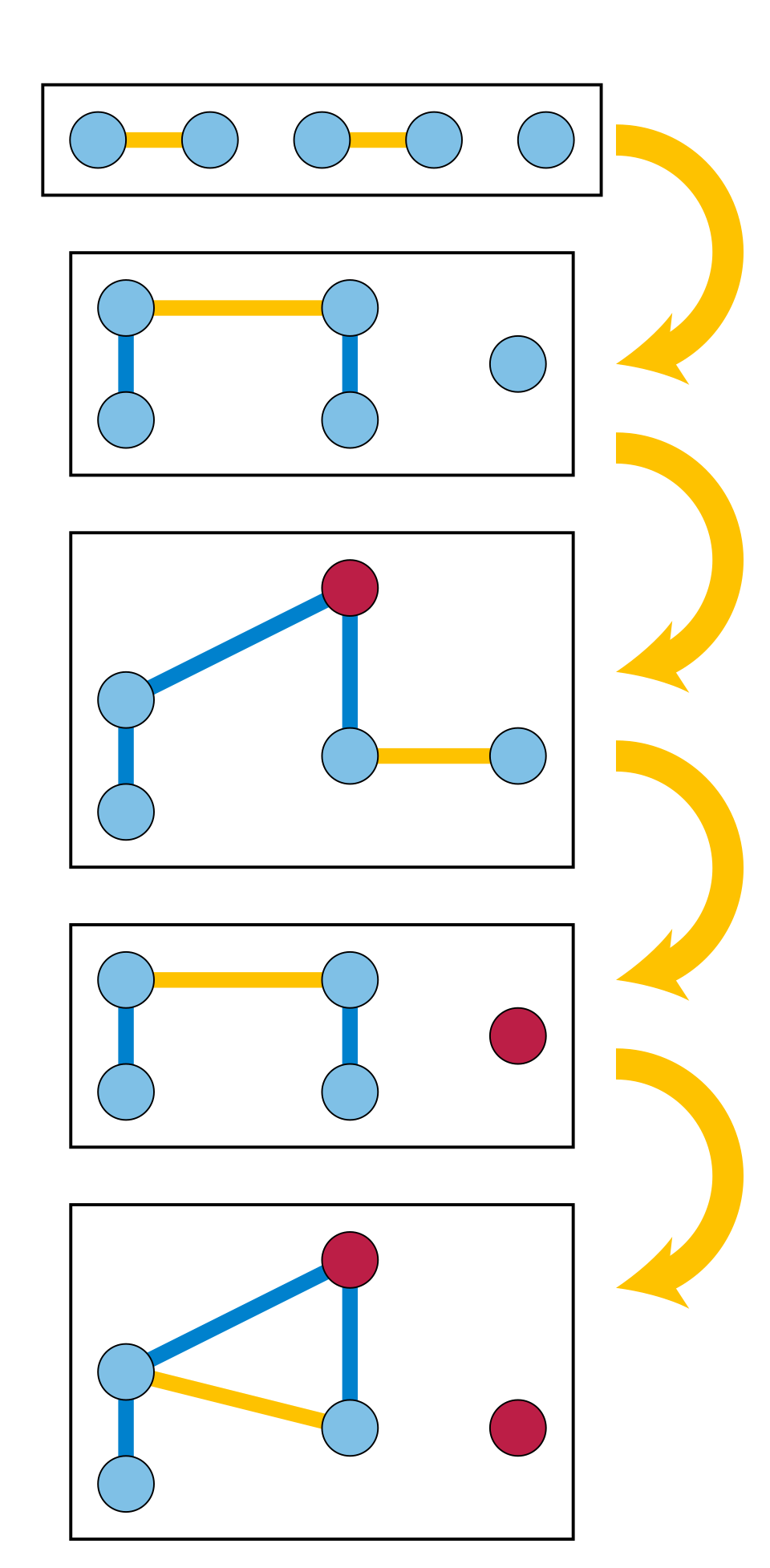
Pour un algorithme de tri qui génère un élément à la fois, comme le tri par sélection , le parcours peut être effectué simultanément au tri, et ce dernier peut être interrompu une fois le tournoi à élimination directe , où les équipes perdantes s'affrontent lors d'un mini-tournoi pour déterminer la deuxième place, illustre cette tri par tas donne l' algorithme de sélection par tas , capable de sélectionner la
Pivotement
De nombreuses méthodes de sélection reposent sur le choix d'un élément « pivot » spécifique dans l'ensemble d'entrée, puis sur la comparaison avec cet élément pour diviser les valeurs restantes en deux sous-ensembles : l'ensemble des éléments inférieurs au pivot et l'ensemble des éléments supérieurs au pivot. L'algorithme peut alors déterminer la
Comme pour l'algorithme de tri rapide par pivot , la partition de l'entrée en ensembles peut être réalisée en créant de nouvelles collections pour ces ensembles, ou par une méthode partitionnant directement une liste ou un tableau. Les détails varient selon la
- Si le pivot était exactement à la médiane de l'entrée, chaque appel récursif renverrait au maximum deux fois moins de valeurs que l'appel précédent, et le nombre total d'itérations augmenterait de géométrique
- Quickselect choisit le pivot de manière aléatoire et uniforme parmi les valeurs d'entrée. Il peut être décrit comme un algorithme d'élagage et de recherche , une variante de quicksort , avec la même stratégie de pivotement, mais là où quicksort effectue deux appels récursifs pour trier les deux sous-collections temps d'exécution moyen
- L' algorithme de Floyd-Rivest , une variante de quickselect, choisit un pivot en échantillonnant aléatoirement un sous-ensemble de valeurs de données, pour une générateur de nombres véritablement aléatoires , il a été prouvé qu'une version de l'algorithme de Floyd-Rivest utilisant un générateur de nombres pseudo-aléatoires initialisé avec seulement un nombre logarithmique de bits véritablement aléatoires s'exécute en temps linéaire avec une probabilité élevée.
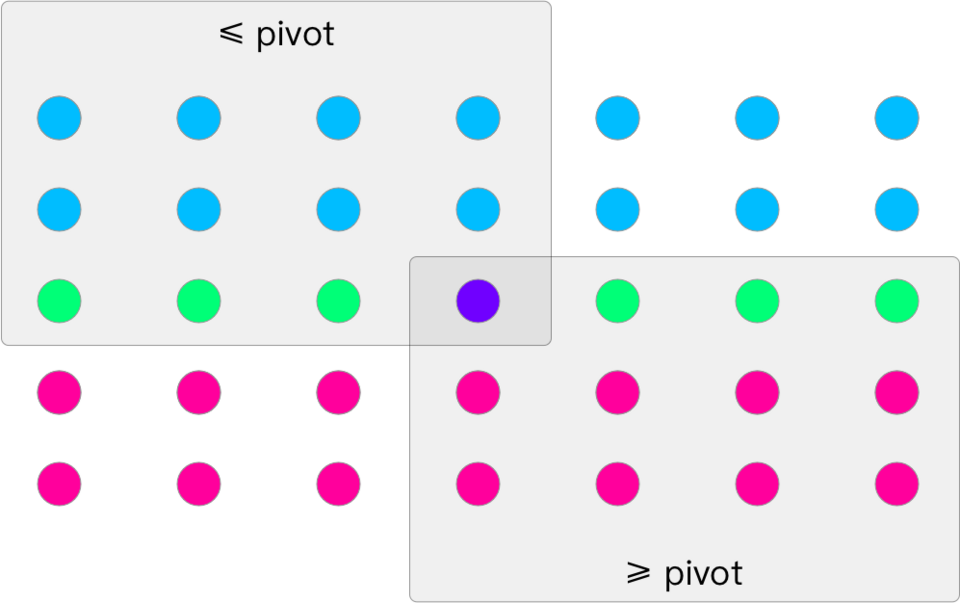
- La méthode de la médiane des médianes partitionne l'entrée en ensembles de cinq éléments et utilise une autre méthode non récursive pour trouver la médiane de chacun de ces ensembles en temps constant par ensemble. Elle s'appelle ensuite récursivement pour trouver la médiane de ces médianes. L'utilisation de la médiane des médianes ainsi obtenue comme pivot produit une partition avec diviser pour régner qui ne se divise pas en deux
- Des algorithmes hybrides tels que introselect peuvent être utilisés pour atteindre les performances pratiques de quickselect avec un repli sur les médianes des médianes garantissant
usines
Les algorithmes de sélection déterministes nécessitant le plus petit nombre de comparaisons connu, pour des valeurs très éloignées de Arnold Schönhage , Mike Paterson et Nick Pippenger des ordres partiels de certains types spécifiés, sur de petits sous-ensembles de valeurs d'entrée, en combinant des ordres partiels plus petits par comparaison. À titre d'exemple très simple, une fabrique peut prendre en entrée une séquence d'ordres partiels à un seul élément, comparer les éléments de ces ordres par paires et produire en sortie une séquence d'ensembles totalement ordonnés à deux éléments. Les éléments utilisés comme entrées de cette fabrique peuvent être soit des valeurs d'entrée n'ayant encore été comparées, soit des valeurs « inutilisées » produites par d'autres fabriques. L'objectif d'un algorithme de type « usine » est de combiner différentes usines, les sorties de certaines usines alimentant les entrées d'autres, afin d'obtenir un ordre partiel dans lequel un élément (le
Algorithmes parallèles
Les algorithmes parallèles de sélection sont étudiés depuis 1975, date à laquelle Leslie Valiant a introduit le modèle d'arbre de comparaison parallèle pour analyser ces algorithmes. Il a démontré que, dans ce modèle, la sélection par un nombre linéaire de comparaisons nécessite des étapes parallèles, même pour sélectionner le minimum ou de RAM parallèle plus réaliste , utilisant un accès mémoire exclusif en lecture et en écriture, la sélection peut être effectuée en un temps O(n) processeurs , ce qui est optimal à la fois en termes de temps et de nombre de
Structures de données sous-linéaires
Lorsque les données sont déjà organisées dans une structure de données , il est possible d'effectuer une sélection en un temps sous-linéaire par rapport au nombre de valeurs. À titre d'exemple simple, pour des données déjà triées dans un tableau, la sélection du
La sélection de données dans un tas binaire prend Ce temps est indépendant de la taille du tas et plus rapide que la limite de temps obtenue par la recherche du meilleur d'abordoptimisation combinatoire , comme la recherche des plus courts chemins dans un graphe pondéré, en définissant un espace d'états des solutions sous la forme d'un arbre ordonné de type tas implicite , puis en appliquant cet algorithme de sélection à cet de type file de priorité associée au tas, améliorant le temps d'extraction du i logarithme itéré
Pour un ensemble de données subissant des insertions et des suppressions dynamiques, l' arbre de statistiques d'ordre enrichit une structure d'arbre binaire de recherche auto-équilibrée d'une quantité constante d'informations supplémentaires par nœud, permettant ainsi d'effectuer les insertions, les suppressions et les requêtes de sélection demandant le Un algorithme de flux avec une complexité mémoire sous-linéaire en n et n ne peut pas résoudre exactement les requêtes de sélection pour des données dynamiques, mais l' algorithme de comptage-minimum permet de les résoudre approximativement, en trouvant une valeur dont la position dans l'ordre des éléments (si elle y était ajoutée) serait à un pas près de n , pour un algorithme dont la taille est à un facteur logarithmique près de n .
limites inférieures
Le temps d'exécution des algorithmes de sélection décrits ci-dessus est nécessaire, car un algorithme capable de traiter des entrées dans un ordre arbitraire doit consacrer ce temps à l'examen de toutes ses entrées. Si l'une de ses valeurs d'entrée n'est pas comparée, il se peut que cette valeur soit celle qui aurait dû être sélectionnée, et l'algorithme risque alors de produire une réponse incorrecte. Au-delà de ce simple argument, de nombreuses recherches ont porté sur le nombre exact de comparaisons nécessaires à la sélection, tant dans le cas aléatoire que déterministe.
La sélection de la valeur minimale nécessite des comparaisons, car les valeurs non retenues doivent chacune avoir été jugées non minimales, étant les plus grandes dans au moins une comparaison, et deux de ces valeurs ne peuvent être les plus grandes dans la même comparaison. Le même raisonnement s'applique symétriquement à la sélection de la
Le cas suivant, le plus simple, consiste à sélectionner la deuxième plus petite valeur. Après plusieurs tentatives infructueuses, la première borne inférieure précise pour ce cas a été publiée en 1964 par le mathématicien soviétique Sergueï Kislitsyn . On peut le démontrer en observant que la sélection de la deuxième plus petite valeur nécessite également de distinguer la plus petite valeur des autres, et en considérant le nombre de comparaisons impliquant la plus petite valeur effectuées par un algorithme pour ce problème. Chaque élément comparé à la plus petite valeur est un candidat pour la deuxième plus petite valeur, et parmi ces valeurs, il faut qu'elles soient supérieures à une autre valeur lors d'une seconde comparaison pour les éliminer. Avec des valeurs supérieures dans au moins une comparaison, et des valeurs supérieures dans au moins deux comparaisons, il y a au total au moins comparaisons. Un argument adverse , dans lequel le résultat de chaque comparaison est choisi de manière à maximiser (sous réserve de cohérence avec au moins un ordre possible) plutôt que par les valeurs numériques des éléments donnés, montre qu'il est possible de contraindre à être algorithme aléatoire avec un nombre moyen de
Plus généralement, la sélection du les permutations possibles des le principe de Yao , il s'applique également au nombre moyen de comparaisons pour un algorithme randomisé sur son entrée la plus défavorable
Pour les algorithmes déterministes, il a été démontré que la sélection du fonction d'entropie binaire
Nombre exact de comparaisons
Knuth fournit le triangle de nombres suivant, récapitulant les paires de valeurs pour lesquelles le nombre exact de comparaisons nécessaires à un algorithme de sélection optimal est connu. La
Histoire
L'algorithme Quickselect a été présenté sans analyse par Tony Hoare 42 ] et analysé pour la première fois dans un rapport technique de 1971 par Donald Knuth de la médiane des médianes , publiée en 1973 par Manuel Blum , Robert W. Floyd , Vaughan Pratt , Ron Rivest et Robert Tarjan . Ces auteurs font remonter la formulation du problème de sélection aux travaux de Charles L. Dodgson (plus connu sous le nom de Lewis Carroll ), qui, en 1883, a souligné que la conception habituelle des tournois sportifs à élimination directe ne garantit pas que le deuxième meilleur joueur remporte la deuxième place , et aux travaux d' Hugo Steinhaus vers 1930, qui a poursuivi cette réflexion en proposant une conception de tournoi permettant d'assurer cette garantie, avec un nombre minimal de matchs joués (c'est-à-dire de 5 ] .