Dans le langage courant, l'aléatoire désigne l'absence apparente ou réelle de schémas définis ou de prévisibilité dans l'information. Une séquence aléatoire d'événements, de symboles ou d'étapes est souvent désordonnée et ne suit aucun schéma ou combinaison intelligible. Par définition, les événements aléatoires individuels sont imprévisibles, mais s'il existe une distribution de probabilité connue , la fréquence des différents résultats lors d'événements répétés (ou « essais ») est prévisible. Par exemple, lorsqu'on lance deux dés , le résultat de chaque lancer est imprévisible, mais obtenir un total de 7 aura tendance à se produire deux fois plus souvent qu'obtenir 4. Dans cette perspective, l'aléatoire n'est pas synonyme de hasard ; c'est une mesure de l'incertitude d'un résultat. L'aléatoire s'applique aux concepts de chance, de probabilité et d'entropie de l'information .
Les mathématiques, les probabilités et les statistiques utilisent des définitions formelles de l'aléatoire, supposant généralement l'existence d'une distribution de probabilité « objective ». En statistique, une variable aléatoire est l'attribution d'une valeur numérique à chaque résultat possible d'un espace d'événements . Cette association facilite l'identification et le calcul des probabilités des événements. Les variables aléatoires peuvent apparaître dans des séquences aléatoires . Un processus aléatoire est une séquence de variables aléatoires dont les résultats ne suivent pas un schéma déterministe , mais une évolution décrite par des distributions de probabilité . Ces concepts, parmi d'autres, sont extrêmement utiles en théorie des probabilités et dans les diverses applications de l'aléatoire .
En statistique, le terme « aléatoire » désigne le plus souvent des propriétés statistiques bien définies. Les méthodes de Monte Carlo , qui reposent sur des données d'entrée aléatoires (issues de générateurs de nombres aléatoires ou pseudo-aléatoires ), sont des techniques importantes en sciences, notamment en informatique . Par analogie, les méthodes quasi-Monte Carlo utilisent des générateurs de nombres quasi-aléatoires .
La sélection aléatoire, lorsqu'elle est étroitement associée à un échantillonnage aléatoire simple , est une méthode de sélection d'éléments (souvent appelés unités) au sein d'une population, où la probabilité de choisir un élément spécifique est proportionnelle à la proportion de ces éléments dans la population. Par exemple, dans un bol contenant 10 billes rouges et 90 billes bleues, un mécanisme de sélection aléatoire choisirait une bille rouge avec une probabilité de 1/10. Un mécanisme de sélection aléatoire qui choisirait 10 billes dans ce bol ne donnerait pas nécessairement 1 bille rouge et 9 billes bleues. Dans les situations où une population est composée d'éléments distincts, un mécanisme de sélection aléatoire exige que chaque élément ait la même probabilité d'être choisi. Autrement dit, si le processus de sélection est tel que chaque membre d'une population, par exemple des sujets de recherche, a la même probabilité d'être choisi, alors on peut dire que le processus de sélection est aléatoire.
Selon la théorie de Ramsey , le pur hasard (au sens d'absence de motif discernable) est impossible, notamment pour les grandes structures. Le mathématicien Theodore Motzkin a suggéré que « si le désordre est plus probable en général, le désordre complet est impossible » . Une mauvaise interprétation de ce principe peut donner lieu à de nombreuses théories du complot . Cristian S. Calude a déclaré que « étant donné l'impossibilité du véritable hasard, les efforts se concentrent sur l'étude des degrés de hasard » . On peut démontrer l'existence d'une hiérarchie infinie (en termes de qualité ou d'intensité) des formes de hasard
Dans l'Antiquité, les concepts de hasard et d'aléatoire étaient étroitement liés à celui de destin. De nombreux peuples anciens jetaient des dés pour déterminer leur sort, une pratique qui a ensuite évolué vers les jeux de hasard. La plupart des civilisations antiques utilisaient diverses méthodes de divination pour tenter de contourner l'aléatoire et le destin. Au-delà de la religion et des jeux de hasard , l'aléatoire est attesté dans le cadre du tirage au sort depuis au moins la démocratie athénienne antique, sous la forme du klérotérion .
La formalisation des probabilités et du hasard remonte peut-être aux Chinois d'il y a 3 000 ans. Les philosophes grecs ont longuement abordé la question du hasard, mais uniquement sous des formes non quantitatives. Ce n'est qu'au XVIe siècle que les mathématiciens italiens ont commencé à formaliser les probabilités associées à divers jeux de hasard. L'invention du calcul infinitésimal a eu un impact positif sur l'étude formelle du hasard. Dans l'édition de 1888 de son ouvrage *The Logic of Chance* , John Venn consacre un chapitre à la conception du hasard, dans lequel il présente sa vision du caractère aléatoire des décimales de pi (π), en les utilisant pour construire une marche aléatoire en deux dimensions.
Le début du XXe siècle a été marqué par un essor rapide de l'analyse formelle du hasard, grâce à l'introduction de diverses approches des fondements mathématiques des probabilités. Au milieu et à la fin du XXe siècle, les idées de la théorie algorithmique de l'information ont enrichi le domaine avec le concept de hasard algorithmique .
Bien que l'aléatoire ait souvent été perçu comme un obstacle et une nuisance pendant des siècles, les informaticiens ont commencé au XXe siècle à comprendre que l' introduction délibérée d'aléatoire dans les calculs pouvait être un outil efficace pour concevoir de meilleurs algorithmes. Dans certains cas, ces algorithmes aléatoires surpassent même les meilleures méthodes déterministes.
En sciences
De nombreux domaines scientifiques s'intéressent au hasard :
Probabilité algorithmiqueDans les sciences physiques
Au XIXe siècle, les scientifiques ont utilisé l'idée de mouvements aléatoires des molécules dans le développement de la mécanique statistique pour expliquer les phénomènes de la thermodynamique et les propriétés des gaz .
Selon plusieurs interprétations classiques de la mécanique quantique , les phénomènes microscopiques sont objectivement aléatoires . Autrement dit, même dans une expérience où tous les paramètres pertinents sont contrôlés, certains aspects du résultat varient aléatoirement. Par exemple, si un atome instable est placé dans un environnement contrôlé, on ne peut prédire le temps nécessaire à sa désintégration, mais seulement la probabilité de désintégration à un intervalle de temps donné . Ainsi, la mécanique quantique ne spécifie pas le résultat des expériences individuelles, mais seulement leurs probabilités. Les théories des variables cachées rejettent l'idée que la nature contienne un aléatoire irréductible : ces théories postulent que, dans les processus qui semblent aléatoires, des propriétés dotées d'une certaine distribution statistique agissent en coulisses, déterminant le résultat dans chaque cas.
En biologie
La synthèse évolutionniste moderne attribue la diversité observée du vivant à des mutations génétiques aléatoires suivies de la sélection naturelle . Cette dernière conserve certaines mutations aléatoires dans le patrimoine génétique en raison de l'amélioration systématique des chances de survie et de reproduction que ces gènes mutés confèrent aux individus qui les possèdent. La localisation de la mutation n'est cependant pas entièrement aléatoire, car des régions biologiquement importantes peuvent être mieux protégées des mutations.
Plusieurs auteurs affirment également que l’évolution (et parfois le développement) requiert une forme spécifique d’aléatoire, à savoir l’introduction de comportements qualitativement nouveaux. Au lieu du choix d’une possibilité parmi plusieurs possibilités prédéfinies, cet aléatoire correspond à la formation de nouvelles possibilités.
Les caractéristiques d'un organisme apparaissent en partie de manière déterministe (par exemple, sous l'influence des gènes et de l'environnement), et en partie de manière aléatoire. Par exemple, la densité des taches de rousseur sur la peau est déterminée par les gènes et l'exposition à la lumière ; en revanche, leur emplacement précis semble aléatoire.
En matière de comportement, l'aléatoire est essentiel pour qu'un animal se comporte de manière imprévisible pour les autres. Par exemple, les insectes en vol ont tendance à changer de direction de façon aléatoire, ce qui rend difficile pour les prédateurs de prédire leurs trajectoires.
En mathématiques
La théorie mathématique des probabilités est née des tentatives de formuler des descriptions mathématiques des événements aléatoires, initialement dans le contexte des jeux de hasard , puis en lien avec la physique. Les statistiques permettent de déduire la distribution de probabilité sous-jacente d'un ensemble d'observations empiriques. Pour la simulation , il est nécessaire de disposer d'une grande quantité de nombres aléatoires , ou de moyens de les générer à la demande.
La théorie algorithmique de l'information étudie, entre autres, ce qui constitue une séquence aléatoire . L'idée centrale est qu'une chaîne de bits est aléatoire si et seulement si elle est plus courte que n'importe quel programme informatique capable de la produire ( aléatoire de Kolmogorov ), ce qui signifie que les séquences aléatoires sont celles qui ne peuvent être compressées . Parmi les pionniers de ce domaine figurent Andreï Kolmogorov et son élève Per Martin-Löf , Ray Solomonoff et Gregory Chaitin . Concernant la notion de séquence infinie, les mathématiciens s'accordent généralement sur la définition semi-éponyme de Per Martin-Löf : une séquence infinie est aléatoire si et seulement si elle résiste à tous les ensembles vides récursivement énumérables. D'autres notions de séquences aléatoires incluent, entre autres, l'aléatoire récursif et l'aléatoire de Schnorr, qui reposent sur les martingales calculables récursivement. Yongge Wang a démontré que ces notions d'aléatoire sont fondamentalement différentes.
L'aléatoire se manifeste dans des nombres tels que log(2) et pi . Les décimales de pi forment une séquence infinie et ne se répètent jamais de manière cyclique. Les nombres comme pi sont également considérés comme probablement normaux .
Pi semble effectivement se comporter ainsi. Dans les six premiers milliards de décimales de pi, chacun des chiffres de 0 à 9 apparaît environ six cents millions de fois. Pourtant, de tels résultats, possiblement fortuits, ne prouvent pas la normalité, même en base 10, et encore moins dans d'autres bases numériques.
En statistiques
En sciences de l'information
En sciences de l'information, les données non pertinentes ou dénuées de sens sont considérées comme du bruit. Le bruit est constitué de nombreuses perturbations transitoires, dont la distribution temporelle est statistiquement aléatoire.
En théorie de la communication , l'aléatoire dans un signal est appelé « bruit », et s'oppose à la composante de sa variation qui est causalement attribuable à la source, le signal.
En ce qui concerne le développement des réseaux aléatoires, l'aléatoire de la communication repose sur les deux hypothèses simples de Paul Erdős et Alfréd Rényi , qui ont dit qu'il y avait un nombre fixe de nœuds et que ce nombre restait fixe pour la durée de vie du réseau, et que tous les nœuds étaient égaux et liés aléatoirement les uns aux autres. hypothèse de la marche aléatoire postule que les prix des actifs sur un marché organisé évoluent de manière aléatoire, en ce sens que l'espérance de leur variation est nulle, mais que leur valeur réelle peut être positive ou négative. Plus généralement, les prix des actifs sont influencés par divers événements imprévisibles de l'environnement économique général.
En politique
Le tirage au sort peut être une méthode officielle pour départager les candidats en cas d'égalité lors d'élections dans certaines juridictions. Son utilisation en politique remonte à l'Antiquité. Dans la Grèce antique, de nombreuses fonctions étaient attribuées par tirage au sort plutôt que par le vote moderne.
Hasard et religion
Le hasard peut être perçu comme incompatible avec les conceptions déterministes de certaines religions, notamment celles qui postulent que l'univers est créé par une divinité omnisciente consciente de tous les événements passés et futurs. Si l'on considère que l'univers a une finalité, alors le hasard peut être considéré comme impossible. C'est l'un des arguments justifiant l'opposition religieuse à la théorie de l'évolution , qui affirme qu'une sélection non aléatoire s'applique aux résultats de variations génétiques aléatoires.
Les philosophies hindoue et bouddhiste affirment que tout événement résulte d’événements antérieurs, comme l’illustre le concept de karma . De ce fait, cette conception s’oppose à l’idée de hasard, et toute conciliation entre les deux nécessiterait une explication.
Dans certains contextes religieux, des pratiques généralement perçues comme aléatoires sont utilisées à des fins divinatoires. La cléromancie, par exemple , utilise le jet d'osselets ou de dés pour révéler ce qui est considéré comme la volonté des dieux.
Applications
Jeux : Les nombres aléatoires ont d’abord été étudiés dans le contexte des jeux de hasard , et de nombreux dispositifs de génération de nombres aléatoires, tels que les dés , les cartes à jouer mélangées et les roulettes , ont été initialement conçus pour les jeux de hasard. La capacité à produire des nombres aléatoires de manière équitable est essentielle aux jeux de hasard en ligne ; c’est pourquoi les méthodes utilisées pour les créer sont généralement réglementées par les commissions de contrôle des jeux . Des tirages au sort sont également utilisés pour déterminer les gagnants des loteries . En réalité, le hasard a été utilisé dans les jeux de hasard à travers l’histoire, et notamment pour sélectionner équitablement des individus pour une tâche non désirée (voir le tirage au sort ).
Sports : Certains sports, comme le football américain , utilisent le tirage au sort pour déterminer aléatoirement les conditions de départ des matchs ou pour départager les équipes à égalité en séries éliminatoires . La NBA utilise une loterie pondérée pour classer les équipes lors de sa draft.
Mathématiques : Les nombres aléatoires sont également utilisés lorsque leur application est mathématiquement importante, comme pour les sondages d’opinion et l’échantillonnage statistique dans les systèmes de contrôle qualité . Les solutions informatiques à certains types de problèmes font un usage intensif des nombres aléatoires, notamment dans la méthode de Monte-Carlo et les algorithmes génétiques .
Médecine : L’attribution aléatoire d’une intervention clinique est utilisée pour réduire les biais dans les essais contrôlés (par exemple, les essais contrôlés randomisés ).
Religion : Bien que n'étant pas censées être aléatoires, diverses formes de divination telles que la cléromancie considèrent ce qui semble être un événement aléatoire comme un moyen pour un être divin de communiquer sa volonté (voir aussi Libre arbitre et Déterminisme pour plus d'informations).
Génération
Il est généralement admis qu'il existe trois mécanismes responsables du comportement (apparemment) aléatoire des systèmes :
- L'aléatoire provenant de l'environnement (par exemple, le mouvement brownien , mais aussi les générateurs de nombres aléatoires matériels ).
- L' aléatoire lié aux conditions initiales est étudié par la théorie du chaos et s'observe dans les systèmes dont le comportement est très sensible aux petites variations des conditions initiales (comme les machines à pachinko et les dés ).
- L'aléatoire est généré intrinsèquement par le système. On parle aussi d'aléatoire pseudo-aléatoire , et c'est ce type d'aléatoire qui est utilisé dans les générateurs de nombres pseudo-aléatoires . Il existe de nombreux algorithmes (basés sur l'arithmétique ou les automates cellulaires ) pour générer des nombres pseudo-aléatoires. Le comportement du système peut être déterminé en connaissant l' état initial et l'algorithme utilisé. Ces méthodes sont souvent plus rapides que l'obtention d'un véritable aléatoire à partir de l'environnement.
Les nombreuses applications du hasard ont donné lieu à de nombreuses méthodes de génération de données aléatoires. Ces méthodes diffèrent par leur degré d'imprévisibilité ou d'aléatoire statistique , ainsi que par leur rapidité de génération.
Avant l'avènement des générateurs de nombres aléatoires informatiques , la génération de grandes quantités de nombres suffisamment aléatoires (essentielle en statistiques) exigeait un travail considérable. Les résultats étaient parfois collectés et diffusés sous forme de tables de nombres aléatoires .
Mesures et tests
La non-localité quantique a été utilisée pour certifier la présence d'une forme authentique ou forte d'aléatoire dans une chaîne de nombres donnée.
Idées fausses et sophismes
Erreur de raisonnement : un nombre est « maudit » ou « béni ».
Erreur de raisonnement : les probabilités ne sont jamais dynamiques.
Au début d'un scénario, on peut calculer la probabilité d'un certain événement. Cependant, dès que l'on obtient davantage d'informations sur le scénario, il peut être nécessaire de recalculer cette probabilité en conséquence.
Par exemple, si l'on apprend qu'une femme a deux enfants, on peut vouloir savoir si l'un d'eux est une fille et, le cas échéant, quelle est la probabilité que l'autre enfant soit également une fille. En considérant les deux événements indépendamment, on pourrait s'attendre à ce que la probabilité que l'autre enfant soit une fille soit de ½ (50 %), mais en construisant un espace probabiliste illustrant tous les résultats possibles, on constaterait que cette probabilité n'est en réalité que de ⅓ (33 %).
Certes, l'espace des probabilités illustre quatre façons d'avoir ces deux enfants : deux garçons, deux garçons, un garçon et une fille, et deux filles. Mais dès lors qu'on sait qu'au moins un des enfants est une fille, le scénario « deux garçons » est exclu, ne laissant que trois possibilités : un garçon et une fille, un garçon et une fille, et deux filles. On constate ainsi que seulement un tiers de ces scénarios impliquent que l'autre enfant soit également une fille (voir le paradoxe du garçon ou de la fille pour plus de détails).
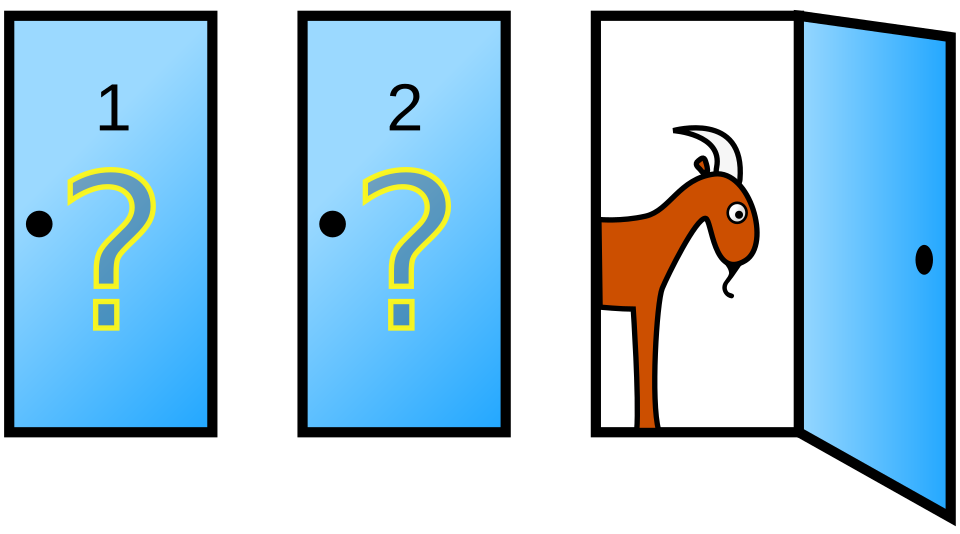
En général, l'utilisation d'un espace de probabilité réduit le risque de passer à côté de scénarios possibles ou de négliger l'importance de nouvelles informations. Cette technique peut être utilisée pour mieux comprendre d'autres situations, comme le problème de Monty Hall , un jeu télévisé où une voiture est cachée derrière l'une des trois portes, et deux chèvres sont dissimulées derrière les autres, servant de lots de consolation . Une fois que le candidat a choisi une porte, l'animateur ouvre l'une des portes restantes pour révéler une chèvre, éliminant ainsi cette porte. Avec seulement deux portes restantes (l'une avec la voiture, l'autre avec une autre chèvre), le joueur doit décider soit de maintenir son choix, soit de changer et de sélectionner l'autre porte. Intuitivement, on pourrait penser que le joueur choisit entre deux portes avec une probabilité égale et que la possibilité d'en choisir une autre ne change rien. Cependant, une analyse des espaces de probabilité révélerait que le candidat a reçu de nouvelles informations et que changer de porte augmenterait ses chances de gagner.