Un cube OLAP est un cube de données , un tableau multidimensionnel de données, utilisé pour le traitement analytique en ligne (OLAP), une technique informatique d'analyse de données pour rechercher des informations.
feuille de calcul à deux ou trois dimensions . Par exemple, une entreprise peut souhaiter synthétiser des données financières par produit, par période et par ville afin de comparer les dépenses réelles et les dépenses budgétées. Le produit, la période, la ville et le scénario (réel et budgété) constituent les dimensions des données.Le terme « cube » est une abréviation pour « ensemble de données multidimensionnel » , car les données peuvent avoir un nombre quelconque de dimensions . On utilise parfois le terme « hypercube », notamment pour les données à plus de trois dimensions. Un cube n'est pas un « cube » au sens mathématique strict, car ses côtés ne sont pas nécessairement tous égaux. Cependant, ce terme est couramment employé.
Une tranche désigne un sous-ensemble de données, obtenu en sélectionnant une valeur pour une dimension et en n'affichant que les données correspondant à cette valeur (par exemple, les données à un instant précis). Les tableurs étant bidimensionnels, le découpage (continu) ou d'autres techniques permettent de visualiser des données multidimensionnelles.
Chaque case du cube contient un nombre qui représente une mesure de l'activité, comme les ventes, les bénéfices, les dépenses, le budget et les prévisions.
Les données OLAP sont généralement stockées dans un schéma en étoile ou en flocon de neige au sein d'un entrepôt de données relationnel ou d'un système de gestion de données spécialisé. Les mesures sont dérivées des enregistrements de la table de faits et les dimensions sont dérivées des tables de dimensions .
Hiérarchie
Les éléments d'une dimension peuvent être organisés sous forme de hiérarchie , un ensemble de relations parent-enfant, où un membre parent résume généralement ses enfants. Les éléments parents peuvent être agrégés en tant qu'enfants d'un autre parent.
Par exemple, le deuxième trimestre 2005 est le parent de mai 2005, qui est lui-même un enfant de l'année 2005. De même, les villes sont les enfants des régions ; les produits se regroupent en groupes de produits et les postes de dépenses individuels en types de dépenses.
Opérations
Concevoir les données comme un cube à dimensions hiérarchiques simplifie les opérations d'analyse. Associer le contenu des données à une visualisation familière améliore l'apprentissage et la productivité des analystes. Le processus de navigation initié par l'utilisateur, qui consiste à afficher les pages de manière interactive en spécifiant des sections par rotation et exploration (drill-down/window), est parfois appelé « découpage et exploration ». Les opérations courantes incluent le découpage et l'exploration, l'exploration détaillée, le regroupement et le pivotement.
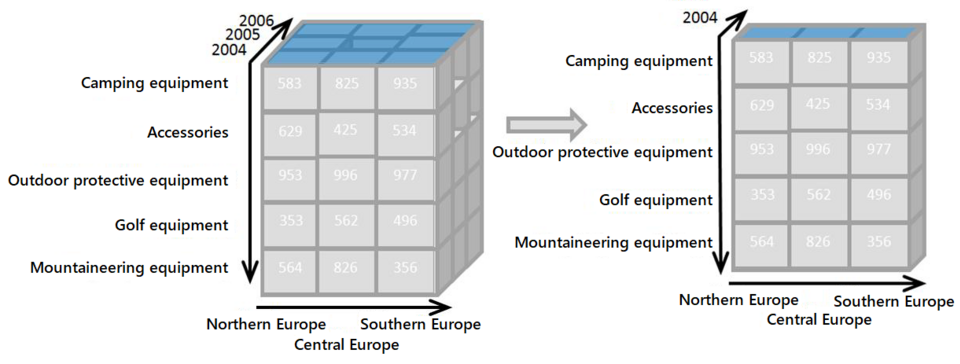
Le découpage consiste à sélectionner un sous-ensemble rectangulaire d'un cube en choisissant une seule valeur pour l'une de ses dimensions, créant ainsi un nouveau cube avec une dimension en moins. L'image montre une opération de découpage : les chiffres de vente de toutes les régions de vente et de toutes les catégories de produits de l'entreprise pour les années 2005 et 2006 sont « découpés » à partir du cube de données.
Dé : L’opération de découpage produit un sous-cube en permettant à l’analyste de sélectionner des valeurs spécifiques de plusieurs dimensions. L’image illustre une opération de découpage : le nouveau cube présente les chiffres de vente d’un nombre limité de catégories de produits ; les dimensions temporelles et géographiques couvrent la même plage qu’auparavant.
La fonction « Exploration » permet à l’utilisateur de naviguer entre différents niveaux de données, du plus synthétique (exploration) au plus détaillé (exploration). L’image illustre une opération d’exploration : l’analyste passe de la catégorie synthétique « Équipements de protection extérieure » aux chiffres de vente des produits individuels.
COUNT, MAX, MIN,et SUMdans OLAP, car ceux-ci peuvent être calculés pour chaque cellule du cube OLAP puis agrégés, car la somme globale (ou le nombre, etc.) est la somme des sous-sommes, mais il est difficile de prendre en charge MEDIAN, car cela doit être calculé pour chaque vue séparément : la médiane d'un ensemble n'est pas la médiane des médianes des sous-ensembles.La fonction Pivot permet à un analyste de faire pivoter le cube dans l'espace pour en visualiser les différentes faces. Par exemple, les villes peuvent être disposées verticalement et les produits horizontalement lors de la consultation des données d'un trimestre donné. La fonction Pivot peut également remplacer les produits par des périodes afin d'observer l'évolution des données d'un produit unique au fil du temps.
L'image illustre une opération de pivotement : le cube entier est tourné, offrant une autre perspective sur les données.
- f : ( X , Y , Z ) → W ,
Les attributs X , Y et Z correspondent aux axes du cube, tandis que la valeur W correspond à l'élément de données qui remplit chaque cellule du cube.
Dans la mesure où les périphériques de sortie bidimensionnels ne peuvent pas facilement caractériser trois dimensions, il est plus pratique de projeter des « tranches » du cube de données (nous disons projeter au sens classique de réduction dimensionnelle de l'analyse vectorielle, et non au sens SQL , bien que les deux soient conceptuellement similaires).
- g : ( X , Y ) → W
qui peut supprimer une clé primaire, mais conserver une certaine signification sémantique, peut-être une tranche de la représentation fonctionnelle triadique pour une valeur Z donnée d'intérêt.
La motivation derrière les affichages OLAP remonte au paradigme des rapports croisés des SGBD des années 1980 et aux tables de contingence antérieures de 1904. Le résultat est un affichage de type feuille de calcul, où les valeurs de X remplissent la ligne $1 ; les valeurs de Y remplissent la colonne $A ; et les valeurs de g : ( X , Y ) → W remplissent les cellules individuelles aux intersections des colonnes étiquetées X et des lignes étiquetées Y , « sud-est », pour ainsi dire, de $B$2, avec $B$2 lui-même inclus.