"
En statistique et en mathématiques combinatoires , le test de groupe désigne toute procédure qui décompose la tâche d'identification d'objets en tests portant sur des groupes d'éléments, plutôt que de tester chaque élément individuellement. Étudié pour la première fois par Robert Dorfman en 1943, le test de groupe est un domaine mathématique relativement récent qui trouve de nombreuses applications pratiques et qui fait aujourd'hui l'objet de recherches actives.
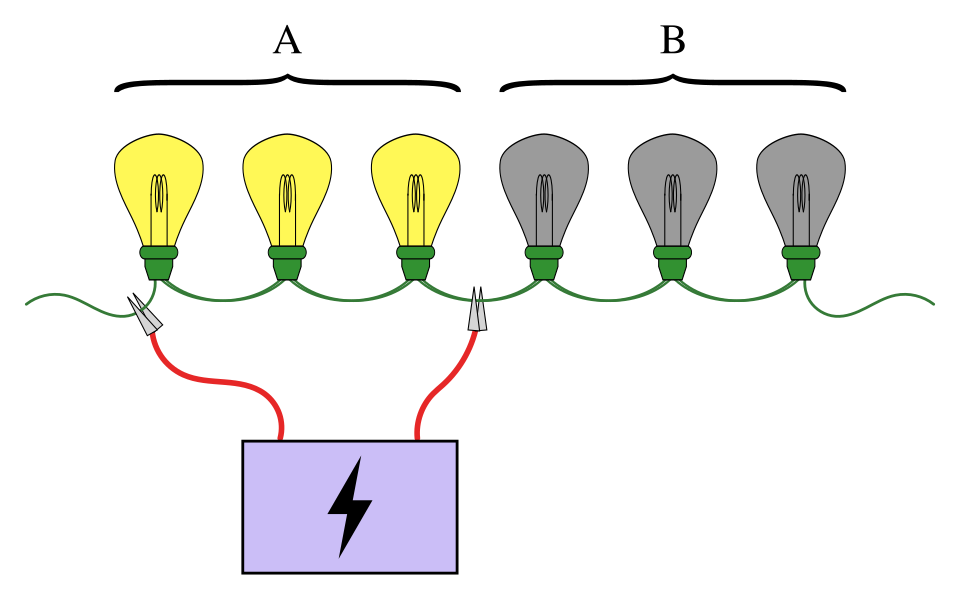
Un exemple courant de test par groupe concerne une guirlande d'ampoules branchées en série, dont une seule est grillée. L'objectif est de trouver l'ampoule défectueuse en effectuant le moins de tests possible (un test consistant à brancher certaines ampoules à une source de courant). Une méthode simple consiste à tester chaque ampoule individuellement. Cependant, lorsqu'il y a un grand nombre d'ampoules, il est beaucoup plus efficace de les regrouper. Par exemple, en branchant la première moitié des ampoules en même temps, on peut déterminer dans quelle moitié se trouve l'ampoule défectueuse, éliminant ainsi la moitié des ampoules en un seul test.
Les protocoles de tests groupés peuvent être simples ou complexes, et les tests mis en œuvre à chaque étape peuvent différer. Les protocoles où les tests de l'étape suivante dépendent des résultats des étapes précédentes sont dits adaptatifs , tandis que ceux où tous les tests sont connus à l'avance sont dits non adaptatifs . La structure du protocole de tests d'une procédure non adaptative est appelée plan de regroupement .
Les tests de groupe ont de nombreuses applications, notamment en statistiques, en biologie, en informatique, en médecine, en ingénierie et en cybersécurité. L’intérêt moderne pour ces schémas de test a été ravivé par le Projet Génome Humain .
Robert Dorfman . Cette idée a germé durant la Seconde Guerre mondiale , lorsque le Service de santé publique des États-Unis et le Service sélectif ont entrepris un vaste projet visant à identifier et à dépister tous les hommes atteints de syphilis appelés sous les drapeaux. Le dépistage de la syphilis consiste à prélever un échantillon de sang, puis à l'analyser afin de déterminer la présence ou l'absence du virus. À l'époque, ce test était coûteux, et tester chaque soldat individuellement aurait été extrêmement onéreux et inefficace.Si l'on considère la présence de soldats, cette méthode de dépistage conduit à des tests individuels. Si une grande proportion de la population est infectée, cette méthode se justifie. Cependant, dans le cas plus probable où seule une très faible proportion d'hommes est infectée, un système de dépistage beaucoup plus efficace peut être mis en place. La faisabilité d'un tel système repose sur le principe suivant : les soldats peuvent être regroupés, et les échantillons sanguins de chaque groupe peuvent être combinés. L'échantillon combiné peut ensuite être analysé afin de vérifier si au moins un soldat du groupe est atteint de syphilis. C'est le principe fondamental du dépistage groupé. Si un ou plusieurs soldats de ce groupe sont atteints de syphilis, un test est inutile (d'autres tests doivent être effectués pour identifier le ou les soldats concernés). En revanche, si aucun soldat du groupe n'est atteint de syphilis, de nombreux tests sont économisés, puisqu'un seul test permet d'éliminer tous les soldats de ce groupe.
Les éléments qui entraînent un résultat positif au test d'un groupe sont généralement appelés éléments défectueux (par exemple, les ampoules cassées, les hommes atteints de syphilis, etc.). Souvent, le nombre total d'éléments est noté et représente le nombre d'éléments défectueux si celui-ci est supposé connu.
Classification des problèmes de tests de groupe
Il existe deux classifications indépendantes pour les problèmes de test de groupe ; chaque problème de test de groupe est soit adaptatif, soit non adaptatif, et soit probabiliste, soit combinatoire.
Dans les modèles probabilistes, on suppose que les articles défectueux suivent une certaine distribution de probabilité et l'objectif est de minimiser le nombre moyen de tests nécessaires pour identifier la défectuosité de chaque article. En revanche, avec les tests combinatoires de groupe, le but est de minimiser le nombre de tests nécessaires dans le pire des cas – c'est-à-dire de créer un algorithme minmax – et aucune connaissance de la distribution des articles défectueux n'est requise.
L'autre classification, l'adaptabilité, concerne les informations utilisables pour choisir les éléments à regrouper dans un test. En général, le choix des éléments à tester peut dépendre des résultats des tests précédents, comme dans l'exemple de l'ampoule. Un algorithme qui effectue un test, puis utilise son résultat (et tous les résultats précédents) pour déterminer le test suivant, est dit adaptatif. À l'inverse, dans les algorithmes non adaptatifs, tous les tests sont décidés à l'avance. Ce principe se généralise aux algorithmes multi-étapes, où les tests sont divisés en étapes et où chaque test de l'étape suivante doit être décidé à l'avance, en se basant uniquement sur les résultats des tests des étapes précédentes. Bien que les algorithmes adaptatifs offrent une plus grande liberté de conception, on sait que les algorithmes de test par groupe adaptatifs n'améliorent pas les algorithmes non adaptatifs de plus d'un facteur constant en termes de nombre de tests nécessaires pour identifier l'ensemble des éléments défectueux. De plus, les méthodes non adaptatives sont souvent utiles en pratique car elles permettent de procéder à des tests successifs sans analyser au préalable les résultats de tous les tests précédents, ce qui permet une distribution efficace du processus de test.
Variantes et extensions
Il existe de nombreuses façons d'étendre le problème des tests de groupe. L'une des plus importantes, appelée tests de groupe bruités , repose sur une hypothèse majeure du problème initial : l'absence d'erreurs lors des tests. Un problème de test de groupe est dit bruité lorsqu'il existe une probabilité, même non négligeable, que le résultat soit erroné (par exemple, un résultat positif alors que le test ne contenait aucun élément défectueux). Le modèle de bruit de Bernoulli suppose que cette probabilité est constante, mais elle peut en général dépendre du nombre réel d'éléments défectueux dans le test et du nombre total d'éléments testés. Par exemple, l'effet de dilution peut être modélisé en considérant qu'un résultat positif est plus probable lorsque le nombre d'éléments défectueux (ou la proportion d'éléments défectueux par rapport au nombre total d'éléments testés) est plus élevé. Un algorithme bruité aura toujours une probabilité non nulle de commettre une erreur (c'est-à-dire d'étiqueter incorrectement un élément).
Les tests de groupe peuvent être étendus en considérant des scénarios où il existe plus de deux résultats possibles pour un test. Par exemple, un test peut avoir les résultats et , correspondant respectivement à l'absence de pièces défectueuses, à la présence d'une seule pièce défectueuse ou à un nombre inconnu de pièces défectueuses supérieur à un. Plus généralement, il est possible de considérer que l'ensemble des résultats d'un test est pour un certain .
Une autre extension consiste à considérer des restrictions géométriques sur les ensembles testables. Le problème des ampoules mentionné précédemment en est un exemple : seules les ampoules apparaissant consécutivement peuvent être testées. De même, les éléments peuvent être disposés en cercle, ou plus généralement, en réseau, les tests étant les chemins possibles sur le graphe. Une autre restriction géométrique concernerait le nombre maximal d'éléments testables dans un groupe, ou encore l'obligation que la taille des groupes soit paire, etc. De la même manière, il peut être utile de considérer la restriction selon laquelle un élément donné ne peut apparaître que dans un certain nombre de tests.
Il existe d'innombrables façons de remanier la formule de base des tests de groupe. Les développements suivants illustrent quelques-unes des variantes les plus originales. Dans le modèle « bon-médiocre-mauvais », chaque élément est classé comme « bon », « médiocre » ou « mauvais », et le résultat d'un test correspond au type de l'élément le moins performant du groupe. Dans les tests de groupe à seuil, le résultat est positif si le nombre d'éléments défectueux dans le groupe dépasse un certain seuil ou une certaine proportion. Les tests de groupe avec inhibiteurs constituent une variante utilisée en biologie moléculaire. Dans ce cas, une troisième catégorie d'éléments, appelés inhibiteurs, est introduite, et le résultat est positif si le test contient au moins un élément défectueux et aucun inhibiteur.
Histoire et développement
Invention et progrès initiaux
Le concept de dépistage groupé a été introduit pour la première fois par Robert Dorfman en 1943 dans un bref rapport publié dans la section Notes des Annals of Mathematical Statistics . Ce rapport, comme tous les premiers travaux sur le dépistage groupé, se concentrait sur le problème probabiliste et visait à utiliser cette idée novatrice pour réduire le nombre de tests nécessaires à l'identification de tous les hommes atteints de syphilis au sein d'un groupe de soldats. La méthode était simple : répartir les soldats en groupes de taille donnée et effectuer des tests individuels (en regroupant les individus par un) sur les groupes positifs afin de déterminer les personnes infectées. Dorfman a établi un tableau des tailles de groupe optimales pour cette stratégie en fonction du taux de prévalence de la syphilis dans la population. Stephen Samuels a trouvé une solution analytique pour la taille de groupe optimale en fonction du taux de prévalence.
Après 1943, les tests groupés sont restés globalement inchangés pendant plusieurs années. Puis, en 1957, Sterrett a amélioré la procédure de Dorfman. Ce nouveau procédé consiste à nouveau à effectuer des tests individuels sur les groupes positifs, mais s'arrête dès qu'un élément défectueux est identifié. Ensuite, les éléments restants du groupe sont testés ensemble, car il est très probable qu'aucun d'entre eux ne soit défectueux.
Le premier exposé approfondi des tests de groupe a été présenté par Sobel et Groll dans leur article fondateur de 1959. Ils y décrivent cinq nouvelles procédures – ainsi que des généralisations pour les cas où le taux de prévalence est inconnu – et fournissent, pour la procédure optimale, une formule explicite permettant de calculer le nombre moyen de tests nécessaires. Cet article établit également, pour la première fois, le lien entre les tests de groupe et la théorie de l'information , tout en abordant plusieurs généralisations du problème des tests de groupe et en proposant de nouvelles applications de la théorie.
Le résultat fondamental de Peter Ungar en 1960 montre que si le taux de prévalence est , où , alors le dépistage individuel est la procédure de dépistage de groupe optimale compte tenu du nombre attendu de tests, et si , alors elle ne l'est pas. Cependant, il est important de noter que malgré 80 ans de recherche, la procédure optimale reste inconnue pour et une population de taille générale . p_{u}" 
 2
2 Tests de groupes combinatoires
Le test de groupe a été étudié pour la première fois dans un contexte combinatoire par Li en 1962 , avec l'introduction de son algorithme à n étapes . Li a proposé une extension de l'algorithme à deux étapes de Dorfman à un nombre arbitraire d'étapes, ne nécessitant pas plus de n tests pour garantir la détection d'un nombre quelconque d'éléments défectueux . L'idée consistait à supprimer tous les éléments ayant donné des résultats négatifs aux tests, puis à diviser les éléments restants en groupes, comme cela avait été fait avec l'ensemble initial. Cette opération devait être répétée n fois avant de procéder aux tests individuels .
Le test de groupe combinatoire en général a ensuite été étudié plus en détail par Katona en 1973. Katona a introduit la représentation matricielle du test de groupe non adaptatif et a produit une procédure pour trouver le défectueux dans le cas non adaptatif 1-défectueux en pas plus de tests, qu'il a également prouvé être optimale.
En général, la recherche d'algorithmes optimaux pour le test de groupe combinatoire adaptatif est difficile, et bien que la complexité computationnelle du test de groupe n'ait pas été déterminée, on suppose qu'elle appartient à une certaine classe de complexité . Cependant, une avancée majeure a eu lieu en 1972 avec l'introduction de l' algorithme de séparation binaire généralisé . Cet algorithme effectue une recherche binaire sur les groupes dont le test est positif ; il s'agit d'un algorithme simple qui détecte un seul élément défectueux en un nombre de tests n'excédant pas la limite inférieure d'information .
Dans les scénarios où deux éléments défectueux ou plus sont présents, l'algorithme de séparation binaire généralisé produit toujours des résultats quasi optimaux, ne nécessitant au plus que le nombre de tests requis au-delà de la limite inférieure d'information, où représente le nombre d'éléments défectueux. En 2013, Allemann a apporté des améliorations considérables à cet algorithme, en réduisant le nombre de tests requis à moins de au-delà de la limite inférieure d'information lorsque et . Ce résultat a été obtenu en remplaçant la recherche binaire de l'algorithme de séparation binaire par un ensemble complexe de sous-algorithmes avec des groupes de tests qui se chevauchent. Ainsi, le problème du test de groupe combinatoire adaptatif – avec un nombre connu ou une limite supérieure du nombre d'éléments défectueux – est quasiment résolu, ne laissant que peu de marge d'amélioration.
La question de savoir quand les tests individuels sont minmax reste ouverte . Hu, Hwang et Wang ont montré en 1981 que les tests individuels sont minmax lorsque , et qu'ils ne le sont pas lorsque . On conjecture actuellement que cette borne est optimale : autrement dit, les tests individuels sont minmax si et seulement si . Des progrès ont été réalisés en 2000 par Riccio et Colbourn, qui ont montré que pour de grandes valeurs de , les tests individuels sont minmax lorsque .
 3d
3d Tests non adaptatifs et probabilistes
L'un des principaux enseignements des tests de groupe non adaptatifs est que des gains significatifs peuvent être obtenus en éliminant l'exigence de réussite certaine de la procédure de test de groupe (le problème « combinatoire »), mais en autorisant plutôt une faible probabilité, mais non nulle, d'erreur d'étiquetage pour chaque élément (le problème « probabiliste »). On sait que lorsque le nombre d'éléments défectueux approche le nombre total d'éléments, les solutions combinatoires exactes nécessitent un nombre de tests nettement supérieur aux solutions probabilistes — même les solutions probabilistes n'autorisant qu'une probabilité d'erreur asymptotiquement faible .
Dans cette optique, Chan et al. (2011) ont introduit COMP , un algorithme probabiliste qui ne nécessite pas plus de tests pour trouver jusqu'à des articles défectueux avec une probabilité d'erreur inférieure ou égale à . Ceci est à un facteur constant de la limite inférieure.
Chan et al. (2011) ont également généralisé la méthode COMP à un modèle bruité simple et ont établi une borne de performance explicite, qui n'était, là encore, qu'une constante (dépendant de la probabilité d'échec d'un test) supérieure à la borne inférieure correspondante. En général, le nombre de tests requis en présence de bruit de Bernoulli est un facteur constant supérieur à celui requis en l'absence de bruit.
Aldridge, Baldassini et Johnson (2014) ont développé une extension de l'algorithme COMP intégrant des étapes de post-traitement supplémentaires. Ils ont démontré que les performances de ce nouvel algorithme, appelé DD , surpassent celles de COMP et que DD est « quasiment optimal » lorsque , en le comparant à un algorithme hypothétique définissant un optimum raisonnable. Les performances de cet algorithme hypothétique suggèrent un potentiel d'amélioration lorsque , et indiquent également l'ampleur de cette amélioration.
Formalisation des tests de groupes combinatoires
Cette section définit formellement les notions et les termes relatifs aux tests de groupe.
- Le vecteur d'entrée , , est défini comme un vecteur binaire de longueur (c'est-à-dire ), l' élément j étant dit défectueux si et seulement si . De plus, tout élément non défectueux est dit « bon ».
- Soit un vecteur d'entrée. Un ensemble est appelé un test . Lorsque le test est sans bruit , le résultat d'un test est positif s'il existe tel que , et négatif sinon.
Par conséquent, l'objectif des tests groupés est de mettre au point une méthode permettant de choisir une série « courte » de tests qui permettent de déterminer, soit avec exactitude, soit avec un degré élevé de certitude.
- On dit qu'un algorithme de test de groupe commet une erreur s'il étiquette incorrectement un élément (c'est-à-dire s'il étiquette un élément défectueux comme non défectueux ou vice versa). Cela ne signifie pas que le résultat d'un test de groupe est incorrect. Un algorithme est dit à erreur nulle si la probabilité qu'il commette une erreur est nulle.
Limites générales
Puisqu'il est toujours possible de recourir à des tests individuels en définissant pour chaque , il est nécessairement que . De plus, puisque toute procédure de test non adaptative peut être écrite comme un algorithme adaptatif en exécutant simplement tous les tests sans tenir compte de leur résultat, . Enfin, lorsque , il existe au moins un élément dont la défectuosité doit être déterminée (par au moins un test), et donc .
En résumé (en supposant ), .
Limite inférieure de l'information
On peut décrire une borne inférieure du nombre de tests nécessaires à l'aide de la notion d' espace d'échantillonnage , noté , qui correspond simplement à l'ensemble des placements possibles des éléments défectueux. Pour tout problème de test groupé avec espace d'échantillonnage et pour tout algorithme de test groupé, on peut démontrer que , où est le nombre minimal de tests requis pour identifier tous les éléments défectueux avec une probabilité d'erreur nulle. On appelle cela la borne inférieure d'information . Cette borne est obtenue en divisant, après chaque test, en deux sous-ensembles disjoints, chacun correspondant à l'un des deux résultats possibles du test.
Cependant, la borne inférieure d'information est généralement inatteignable, même pour les petits problèmes. Cela s'explique par le fait que la division n'est pas arbitraire, puisqu'elle doit être réalisable par un test quelconque.
En fait, la borne inférieure d'information peut être généralisée au cas où il existe une probabilité non nulle que l'algorithme commette une erreur. Sous cette forme, le théorème nous donne une borne supérieure de la probabilité de succès en fonction du nombre de tests. Pour tout algorithme de test groupé effectuant tests, la probabilité de succès, , satisfait . Cette relation peut être renforcée comme suit : .
Représentation des algorithmes non adaptatifs
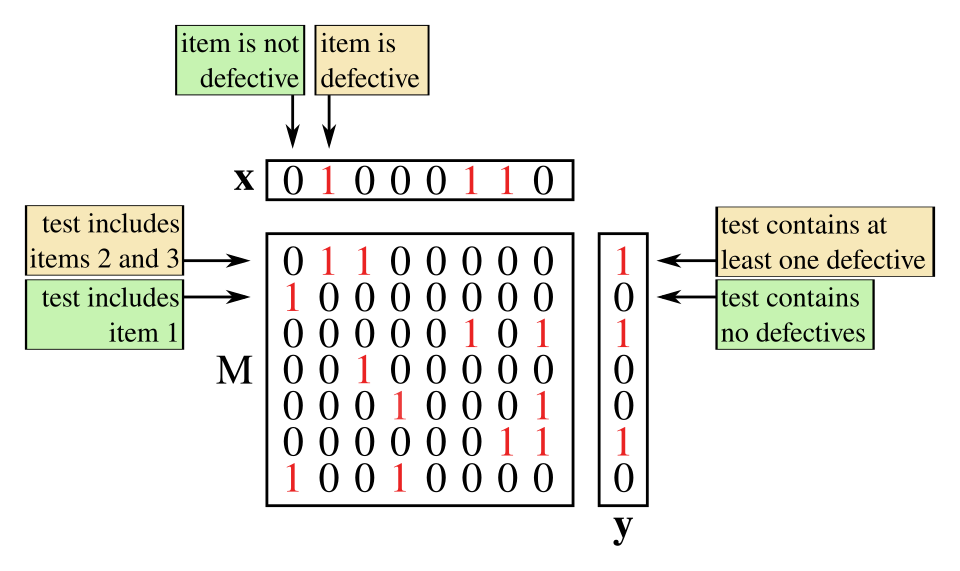
Les algorithmes de tests de groupe non adaptatifs comportent deux phases distinctes. La première consiste à déterminer le nombre de tests à effectuer et les items à inclure dans chaque test. La seconde phase, souvent appelée décodage, analyse les résultats de chaque test de groupe afin d'identifier les items susceptibles d'être défectueux. La première phase est généralement représentée par une matrice, comme suit :
- Supposons qu'une procédure de test de groupe non adaptative pour les items consiste en les tests pour certains . La matrice de test pour ce schéma est la matrice binaire , où si et seulement si (et est zéro sinon).
Ainsi, chaque colonne représente un élément et chaque ligne représente un test, avec un dans l' entrée indiquant que le test comprenait l' élément et un indiquant le contraire.
Outre le vecteur (de longueur ) qui décrit l'ensemble défectueux inconnu, il est courant d'introduire le vecteur de résultat, qui décrit les résultats de chaque test.
- Soit le nombre de tests effectués par un algorithme non adaptatif. Le vecteur de résultats , , est un vecteur binaire de longueur (c'est-à-dire ) tel que si et seulement si le résultat du test était positif (c'est-à-dire contenait au moins un élément défectueux).
Avec ces définitions, le problème non adaptatif peut être reformulé comme suit : on choisit d’abord une matrice de test, , puis on renvoie le vecteur. Le problème consiste alors à analyser pour trouver une estimation de .
Dans le cas bruité le plus simple, où la probabilité d'un résultat erroné lors d'un test de groupe est constante, on considère un vecteur binaire aléatoire , où chaque élément a une probabilité d'être , et sinon. Le vecteur renvoyé est alors , auquel on ajoute (ou XOR élément par élément ). Un algorithme bruité doit estimer à partir de (c'est-à-dire sans connaissance directe de ).
Limites pour les algorithmes non adaptatifs
La représentation matricielle permet de démontrer certaines bornes sur les tests de groupe non adaptatifs. L'approche est similaire à celle de nombreux plans déterministes, où l'on considère des matrices -séparables, telles que définies ci-dessous.
- Une matrice binaire, , est dite -séparable si la somme booléenne (OU logique) de chacune de ses colonnes est distincte. De plus, la notation -séparable indique que la somme des valeurs d' au plus n colonnes de est distincte. (Ceci est différent de la notion de -séparabilité pour toutes les valeurs de .)
Lorsqu'une matrice est une matrice de test, la propriété d'être -séparable ( -séparable) équivaut à pouvoir distinguer jusqu'à 1 éléments défectueux. Cependant, cela ne garantit pas que cette distinction sera simple. Une propriété plus forte, appelée disjonction, le garantit.
- Une matrice binaire est dite disjointe si la somme booléenne de ses colonnes ne contient aucune autre colonne. (Dans ce contexte, on dit qu'une colonne A contient une colonne B si, pour tout indice où B vaut 1, A vaut également 1.)
Une propriété utile des matrices de test disjointes est que, avec jusqu'à n éléments défectueux, chaque élément non défectueux apparaîtra dans au moins un test dont le résultat est négatif. Il existe donc une procédure simple pour identifier les éléments défectueux : il suffit de supprimer tous les éléments qui apparaissent dans un test négatif.
En utilisant les propriétés des matrices -séparables et -disjointes, on peut démontrer ce qui suit pour le problème d'identification des articles défectueux parmi l'ensemble des articles.
- Le nombre de tests nécessaires pour une probabilité d'erreur moyenne asymptotiquement faible varie comme .
- Le nombre de tests nécessaires pour une probabilité d'erreur maximale asymptotiquement faible varie comme .
- Le nombre de tests nécessaires pour une probabilité d'erreur nulle varie comme .
Algorithme de séparation binaire généralisé
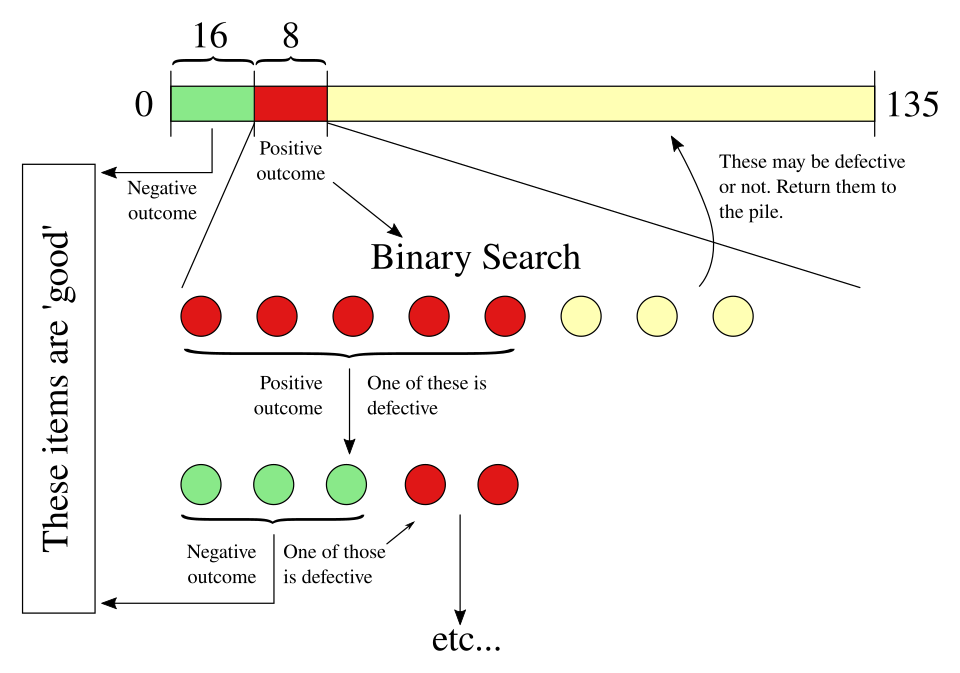
L'algorithme de division binaire généralisé est un algorithme de test de groupe adaptatif essentiellement optimal qui trouve ou moins de défectueux parmi les articles comme suit :
- Si oui , testez les éléments individuellement. Sinon, définissez et .
- Tester un groupe de taille . Si le résultat est négatif, tous les éléments du groupe sont considérés comme non défectueux ; définir et retourner à l’étape 1. Sinon, effectuer une recherche dichotomique pour identifier un élément défectueux et un nombre indéterminé, appelé , d’éléments non défectueux ; définir et . Retourner à l’étape 1.
L'algorithme de division binaire généralisé ne nécessite pas plus de tests où .
Pour de grandes valeurs de , on peut montrer que , ce qui est comparable aux tests requis pour l'algorithme à - étapes de Li. En fait, l'algorithme de séparation binaire généralisé est proche de l'optimum au sens suivant. Lorsque , on peut montrer que , où est la borne inférieure de l'information.
Algorithmes non adaptatifs
Les algorithmes de test de groupe non adaptatifs supposent généralement que le nombre de pièces défectueuses, ou du moins une bonne borne supérieure de ce nombre, est connu. Cette quantité est notée dans cette section. Si aucune borne n'est connue, il existe des algorithmes non adaptatifs à faible complexité de requête qui peuvent aider à l'estimer .
Poursuite de correspondance orthogonale combinatoire (COMP)
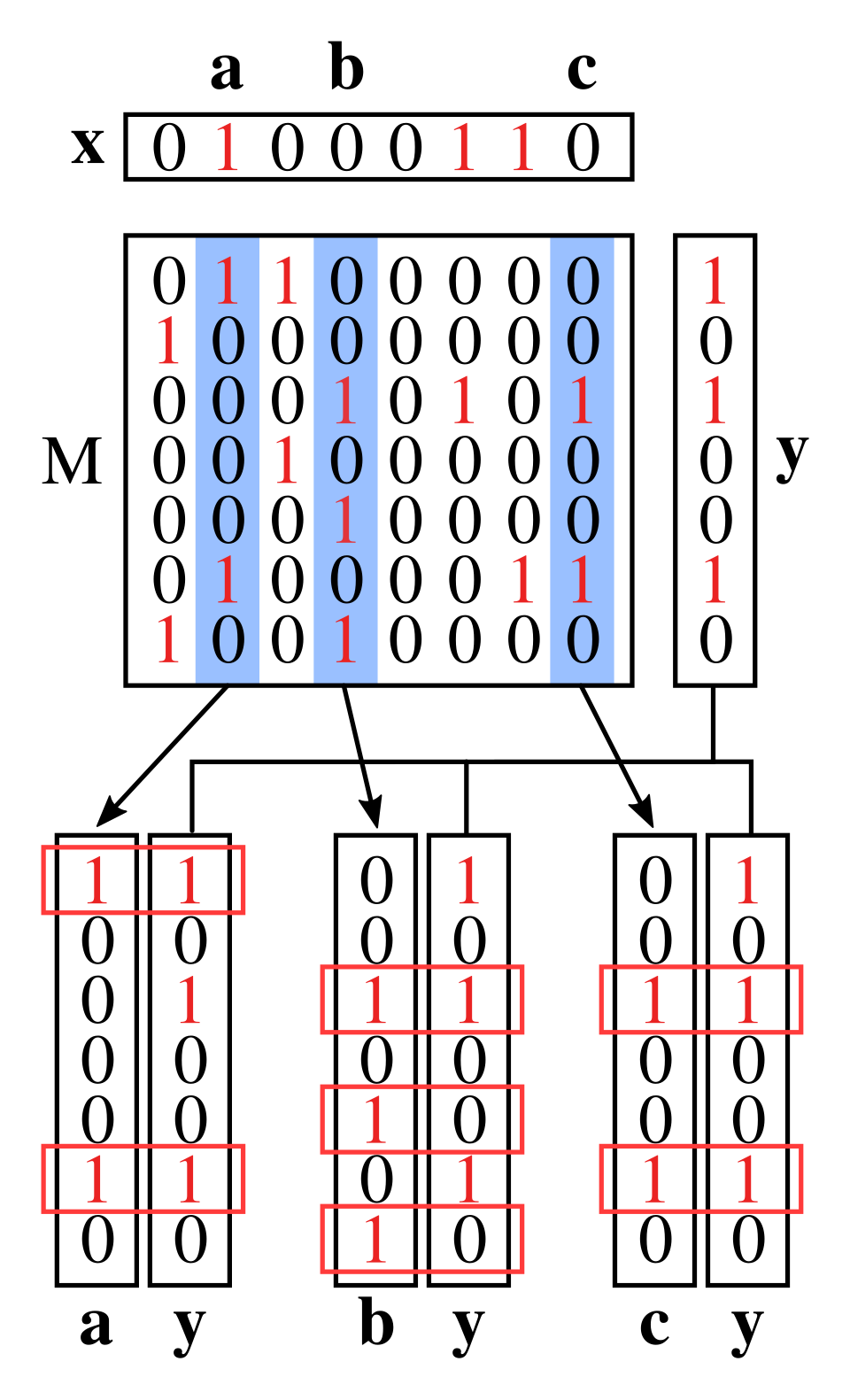
Combinatorial Orthogonal Matching Pursuit , ou COMP, est un algorithme de test de groupe simple et non adaptatif qui constitue la base des algorithmes plus complexes qui suivent dans cette section.
Premièrement, chaque entrée de la matrice de test est choisie iid pour être avec une probabilité et sinon.
L'étape de décodage s'effectue colonne par colonne (c'est-à-dire par élément). Si tous les tests auxquels un élément participe sont positifs, l'élément est déclaré défectueux ; sinon, il est considéré comme non défectueux. De même, si un élément participe à au moins un test dont le résultat est négatif, il est déclaré non défectueux ; sinon, il est considéré comme défectueux. Une propriété importante de cet algorithme est qu'il ne génère jamais de faux négatifs . Toutefois, un faux positif peut se produire lorsque toutes les positions contenant des 1 dans la j -ième colonne (correspondant à un élément non défectueux j ) sont masquées par les 1 des autres colonnes correspondant à des éléments défectueux.
L'algorithme COMP ne nécessite pas plus de tests pour avoir une probabilité d'erreur inférieure ou égale à . Ceci se situe dans un facteur constant de la limite inférieure de la probabilité d'erreur moyenne ci-dessus.
En présence de bruit, on assouplit la condition de l'algorithme COMP original selon laquelle l'ensemble des positions des 1 dans chaque colonne de la matrice correspondant à un élément positif doit être entièrement inclus dans l'ensemble des positions des 1 dans le vecteur résultat. On autorise plutôt un certain nombre de « non-correspondances », ce nombre dépendant à la fois du nombre de 1 dans chaque colonne et du paramètre de bruit . Cet algorithme COMP bruité ne nécessite pas plus de tests pour atteindre une probabilité d'erreur d'au plus .
Défectueux avérés (DD)
La méthode des défauts avérés (DD) est une extension de l'algorithme COMP qui vise à éliminer les faux positifs. Il a été démontré que les performances de DD sont nettement supérieures à celles de COMP.
L'étape de décodage exploite une propriété utile de l'algorithme COMP : tout élément déclaré non défectueux par COMP l'est assurément (c'est-à-dire qu'il n'y a pas de faux négatifs). Elle se déroule comme suit.
- L'algorithme COMP est d'abord exécuté, et tous les éléments non défectueux qu'il détecte sont supprimés. Tous les éléments restants sont désormais considérés comme « potentiellement défectueux ».
- L'algorithme examine ensuite tous les tests positifs. Si un élément apparaît comme le seul « potentiellement défectueux » lors d'un test, alors il est nécessairement défectueux et l'algorithme le déclare donc défectueux.
- Tous les autres articles sont considérés comme non défectueux. Cette dernière étape se justifie par l'hypothèse que le nombre d'articles défectueux est bien inférieur au nombre total d'articles.
Il est important de noter que les étapes 1 et 2 sont infaillibles ; l’algorithme ne peut donc se tromper que s’il déclare un article défectueux comme non défectueux. Par conséquent, l’algorithme DD ne peut produire que des faux négatifs.
COMP séquentiel (SCOMP)
SCOMP (Sequential COMP) est un algorithme qui exploite le fait que DD ne commet aucune erreur jusqu'à la dernière étape, où l'on suppose que les éléments restants sont non défectueux. Soit l'ensemble des éléments déclarés défectueux . Un test positif est dit expliqué par s'il contient au moins un élément de . L'observation clé concernant SCOMP est que l'ensemble des éléments défectueux trouvés par DD peut ne pas expliquer tous les tests positifs, et que tout test non expliqué contient nécessairement un élément défectueux caché.
L'algorithme se déroule comme suit.
- Effectuez les étapes 1 et 2 de l'algorithme DD pour obtenir , une estimation initiale pour l'ensemble des défectueux.
- Si explique chaque test positif, terminez l'algorithme : est l'estimation finale pour l'ensemble des défectueux.
- S'il reste des tests inexpliqués, identifiez le « défectueux potentiel » qui apparaît dans le plus grand nombre de tests inexpliqués et déclarez-le comme défectueux (c'est-à-dire, ajoutez-le à l'ensemble ). Passez à l'étape 2.
Dans les simulations, il a été démontré que SCOMP fonctionne de manière quasi optimale.
Pools de polynômes (PP)
L'algorithme de regroupement polynomial (PP) est un algorithme déterministe qui garantit l'identification exacte des valeurs positives jusqu'à un certain nombre d'observations. Cet algorithme permet de construire la matrice de regroupement , qui peut être utilisée directement pour décoder les observations . De manière similaire à l'algorithme COMP, un échantillon est décodé selon la relation : , où représente la multiplication élément par élément et est la i-ème colonne de . L'étape de décodage étant simple, PP est spécialisé dans la génération de .
Formation de groupes

Un groupe/pool est généré à l'aide d'une relation polynomiale qui spécifie les indices des échantillons contenus dans chaque pool. Un ensemble de paramètres d'entrée détermine l'algorithme. Pour un nombre premier et un entier, toute puissance d'un nombre premier est définie par . Pour un paramètre de dimension, le nombre total d'échantillons est et le nombre d'échantillons par pool est . De plus, le corps fini d' ordre est noté (c'est-à-dire les entiers définis par des opérations arithmétiques spéciales qui garantissent que l'addition et la multiplication dans restent dans ). La méthode dispose chaque échantillon dans une grille et le représente par des coordonnées . Les coordonnées sont calculées selon une relation polynomiale utilisant les entiers ,
 1
1 La combinaison de boucles sur les valeurs est représentée par un ensemble dont les éléments sont une séquence d' entiers, c'est-à-dire , où . Sans perte de généralité , la combinaison est telle que effectue itérations toutes les fois, itérations toutes les fois, jusqu'à ce que ne s'exécute plus qu'une seule fois. Les formules qui calculent les indices d'échantillon, et donc les pools correspondants, pour et fixés , sont données par
Les calculs peuvent être effectués à l'aide de bibliothèques logicielles publiques pour les corps finis, lorsque n est une puissance d'un nombre premier. Lorsque n est un nombre premier, les calculs se simplifient en arithmétique du module, soit n ≥ 0. Un exemple de génération d'un pool lorsque n = 0 est présenté dans le tableau ci-dessous, tandis que la sélection d'échantillons correspondante est illustrée dans la figure ci-dessus.
Cette méthode utilise des tests pour identifier avec précision jusqu'à un certain nombre de cas positifs parmi les échantillons. De ce fait, la méthode PP est particulièrement efficace pour les grands échantillons, car le nombre de tests croît linéairement avec le nombre d'échantillons, tandis que ce dernier croît exponentiellement. Cependant, la méthode PP peut également être efficace pour les petits échantillons.
Exemples d'applications
La généralité de la théorie des tests de groupe la rend applicable à de nombreuses applications diverses, notamment le criblage de clones, la localisation de courts-circuits électriques ; les réseaux informatiques à haut débit ; l’examen médical, la recherche quantitative, les statistiques ; l’apprentissage automatique, le séquençage de l’ADN ; la cryptographie ; et l’analyse forensique des données. Cette section présente un bref aperçu d’une petite sélection de ces applications.
canaux multi-accès
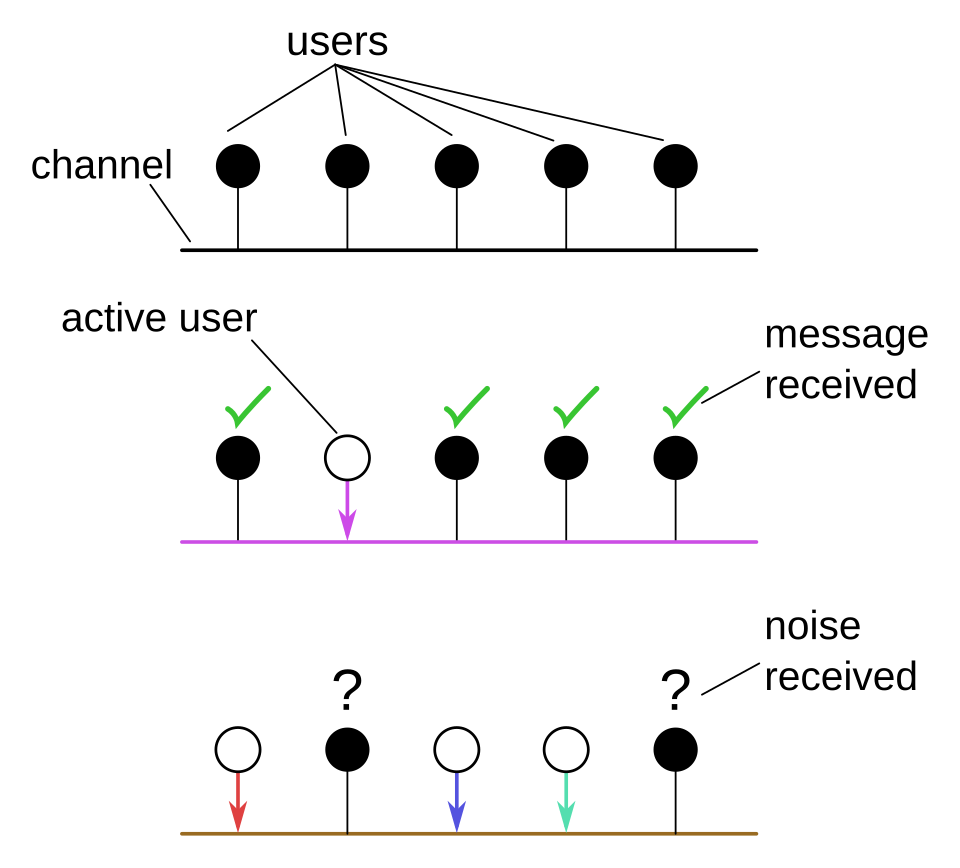
Un canal multi-accès est un canal de communication qui connecte simultanément plusieurs utilisateurs. Chaque utilisateur peut écouter et transmettre sur ce canal, mais si plusieurs utilisateurs transmettent en même temps, les signaux entrent en collision et sont réduits à un bruit inintelligible. Les canaux multi-accès sont importants pour diverses applications concrètes, notamment les réseaux informatiques sans fil et les réseaux téléphoniques.
Un problème majeur des canaux multi-accès réside dans l'attribution des créneaux horaires de transmission aux utilisateurs afin d'éviter les conflits entre leurs messages. Une méthode simple consiste à attribuer à chaque utilisateur un intervalle de temps dédié à la transmission (on parle alors de multiplexage temporel , ou TDM). Cependant, cette méthode est très inefficace, car elle attribue des créneaux à des utilisateurs qui n'ont peut-être pas de message à transmettre. Or, on suppose généralement que seuls quelques utilisateurs souhaitent transmettre simultanément ; autrement, un canal multi-accès n'est tout simplement pas viable.
Dans le cadre des tests de groupe, ce problème est généralement abordé en divisant le temps en « époques » de la manière suivante : Un utilisateur est dit « actif » s’il a un message au début d’une époque. (Si un message est généré pendant une époque, l’utilisateur ne devient actif qu’au début de l’époque suivante.) Une époque se termine lorsque chaque utilisateur actif a transmis son message avec succès. Le problème consiste alors à identifier tous les utilisateurs actifs au cours d’une époque donnée et à planifier une transmission pour chacun d’eux (s’ils ne l’ont pas déjà fait avec succès). Ici, un test sur un ensemble d’utilisateurs correspond aux utilisateurs qui tentent de transmettre. Les résultats du test sont le nombre d’utilisateurs ayant tenté de transmettre, et , correspondant respectivement à aucun utilisateur actif, exactement un utilisateur actif (message transmis avec succès) ou plus d’un utilisateur actif (collision de messages). Par conséquent, en utilisant un algorithme de test de groupe adaptatif avec les résultats , il est possible de déterminer quels utilisateurs souhaitent transmettre au cours de l’époque. Ainsi, tout utilisateur n'ayant pas encore effectué de transmission réussie peut désormais se voir attribuer un créneau horaire pour transmettre, sans gaspiller de temps en attribuant inutilement des plages horaires à des utilisateurs inactifs.
Apprentissage automatique et détection compressée
L'apprentissage automatique est un domaine de l'informatique qui compte de nombreuses applications logicielles, telles que la classification de l'ADN, la détection de la fraude et la publicité ciblée . L'un des principaux sous-domaines de l'apprentissage automatique est le problème de « l'apprentissage par l'exemple », qui consiste à approximer une fonction inconnue à partir de sa valeur en un certain nombre de points spécifiques. Comme indiqué dans cette section, ce problème d'apprentissage de fonction peut être abordé par une approche de test par groupes.
Dans une version simplifiée du problème, il existe une fonction inconnue, où et (en utilisant l'arithmétique logique : l'addition correspond à l'opérateur OU logique et la multiplication à l'opérateur ET logique). Ici, est « creuse », ce qui signifie qu'au plus ses entrées sont égales à . L'objectif est de construire une approximation de en utilisant des évaluations ponctuelles, où est aussi petit que possible. (La récupération exacte de correspond aux algorithmes sans erreur, tandis que est approchée par des algorithmes ayant une probabilité d'erreur non nulle.)
Dans ce problème, la récupération est équivalente à la recherche de . De plus, si et seulement s'il existe un indice , où . Ce problème est donc analogue à un problème de test de groupe avec des éléments défectueux et un nombre total d'éléments. Les entrées de sont les éléments, qui sont défectueux s'ils sont , spécifie un test, et un test est positif si et seulement si .
En réalité, on s'intéressera souvent à des fonctions plus complexes, telles que , où . La compression de données , étroitement liée aux tests de groupe, peut être utilisée pour résoudre ce problème.
En échantillonnage compressé, l'objectif est de reconstruire un signal, , à partir d'un certain nombre de mesures. Ces mesures sont modélisées comme le produit scalaire de avec un vecteur choisi. Le but est d'utiliser un petit nombre de mesures, ce qui est généralement impossible sans faire d'hypothèses sur le signal. Une de ces hypothèses (courante ) est que seules quelques composantes de sont significatives , c'est-à-dire qu'elles ont une grande amplitude. Puisque les mesures sont des produits scalaires de , l'équation est vérifiée, où est une matrice décrivant l'ensemble des mesures choisies et est l'ensemble des résultats de mesure. Cette construction montre que l'échantillonnage compressé est une forme de test de groupe « continu ».
La principale difficulté de l'échantillonnage compressé réside dans l'identification des entrées significatives . Une fois cette étape franchie, diverses méthodes permettent d'estimer les valeurs réelles de ces entrées . Cette identification peut être abordée par une simple application de tests de groupe. Un test de groupe produit un nombre complexe : la somme des entrées testées. Le résultat du test est dit positif s'il produit un nombre complexe de grande magnitude, ce qui, compte tenu de l'hypothèse que les entrées significatives sont rares, indique qu'au moins une entrée significative est présente dans le test.
Il existe des constructions déterministes explicites pour ce type d' algorithme de recherche combinatoire , nécessitant des mesures. Cependant, comme pour les tests de groupe, celles-ci sont sous-optimales, et les constructions aléatoires (telles que COMP) peuvent souvent récupérer de manière sous-linéaire en .
Conception d'un test multiplex pour le dépistage de la COVID-19
Lors d'une pandémie telle que l'épidémie de COVID-19 en 2020, les tests de détection virale sont parfois réalisés à l'aide de protocoles de tests groupés non adaptatifs. Le projet Origami Assays en a fourni un exemple en publiant des protocoles de tests groupés open source utilisables sur une plaque 96 puits standard de laboratoire.

En laboratoire, l'une des difficultés des tests de groupe réside dans le fait que la préparation des mélanges peut s'avérer longue et complexe à réaliser manuellement avec précision. Les tests d'origami ont permis de contourner ce problème en fournissant des gabarits en papier pour guider le technicien dans la répartition des échantillons de patients dans les puits de test.
Grâce au protocole de test le plus complet (XL3), il a été possible d'analyser 1 120 échantillons de patients dans 94 puits de dosage. Si le taux de vrais positifs était suffisamment faible, aucun test supplémentaire n'était requis.
hachage cryptographique unidirectionnel . Cette fonction prend les données et, grâce à une procédure difficilement réversible, produit un nombre unique appelé hachage. Les hachages, souvent beaucoup plus courts que les données elles-mêmes, permettent de vérifier si les données ont été modifiées sans avoir à stocker inutilement des copies complètes de l'information : le hachage des données actuelles peut être comparé à un hachage antérieur pour déterminer si des modifications sont survenues. Un inconvénient de cette méthode est que, bien qu'il soit facile de constater si les données ont été modifiées, il est impossible de déterminer comment : autrement dit, il est impossible de retrouver quelle partie des données a été modifiée.Une façon de contourner cette limitation consiste à stocker davantage de hachages – cette fois-ci de sous-ensembles de la structure de données – afin de restreindre la zone d'attaque. Cependant, pour trouver l'emplacement exact de l'attaque avec une approche naïve, il faudrait stocker un hachage pour chaque donnée de la structure, ce qui annulerait tout l'intérêt des hachages. (Il serait tout aussi simple de stocker une copie classique des données.) Les tests de groupe permettent de réduire considérablement le nombre de hachages à stocker. Un test consiste à comparer les hachages stockés et les hachages actuels ; le résultat est positif en cas de différence. Cela indique qu'au moins une donnée modifiée (considérée comme une anomalie dans ce modèle) est présente dans le groupe ayant généré le hachage actuel.
En fait, le nombre de hachages nécessaires est si faible que ceux-ci, ainsi que la matrice de test à laquelle ils se rapportent, peuvent même être stockés au sein de la structure organisationnelle des données elles-mêmes. Cela signifie que, du point de vue de la mémoire, le test peut être effectué « gratuitement ». (Ceci est vrai à l’exception d’une clé principale/mot de passe qui est utilisé pour déterminer secrètement la fonction de hachage.)