En informatique , un algorithme indépendant du cache (ou algorithme transcendant le cache) est conçu pour exploiter le cache du processeur sans que la taille du cache (ou la longueur des lignes de cache , etc.) ne soit un paramètre explicite. Un algorithme indépendant du cache optimal est un algorithme qui utilise le cache de manière optimale ( asymptotiquement , en négligeant les facteurs constants). Ainsi, un algorithme indépendant du cache est conçu pour fonctionner correctement, sans modification, sur plusieurs machines avec des tailles de cache différentes, ou pour une hiérarchie mémoire comportant différents niveaux de cache de tailles différentes. Les algorithmes indépendants du cache s'opposent au pavage de boucles explicite , qui divise explicitement un problème en blocs de taille optimale pour un cache donné.
Les algorithmes optimaux indépendants du cache sont connus pour la multiplication matricielle , la transposition matricielle , le tri et plusieurs autres problèmes. Certains algorithmes plus généraux, comme la FFT de Cooley-Tukey , sont optimaux sans contrainte de cache pour certains choix de paramètres. Comme ces algorithmes ne sont optimaux qu'asymptotiquement (en négligeant les facteurs constants), un réglage plus poussé, spécifique à la machine , peut être nécessaire pour obtenir des performances quasi optimales en valeur absolue. L'objectif des algorithmes indépendants du cache est de réduire l'ampleur de ce réglage.
Un algorithme insensible au cache fonctionne généralement selon un algorithme récursif de type « diviser pour régner » , où le problème est divisé en sous-problèmes de plus en plus petits. On atteint finalement une taille de sous-problème compatible avec la taille du cache, quelle que soit la taille de ce dernier. Par exemple, une multiplication matricielle optimale et insensible au cache est obtenue en divisant récursivement chaque matrice en quatre sous-matrices à multiplier, puis en effectuant la multiplication de ces sous-matrices en parcourant le système en profondeur . Pour optimiser l'algorithme pour une machine spécifique, on peut utiliser un algorithme hybride qui utilise un pavage de boucles optimisé pour les tailles de cache spécifiques au niveau le plus bas, tout en utilisant par ailleurs l'algorithme insensible au cache.
Charles E. Leiserson dès 1996 et publiée pour la première fois par Harald Prokop dans sa thèse de maîtrise au Massachusetts Institute of Technology en 1999. De nombreux travaux antérieurs ont analysé des problèmes spécifiques ; ceux-ci sont discutés en détail dans Frigo et al. 1999. Parmi les premiers exemples cités, on peut citer Singleton 1969 pour une transformée de Fourier rapide récursive, des idées similaires dans Aggarwal et al. 1987, Frigo 1996 pour la multiplication matricielle et la décomposition LU, et Blitz++ .Modèle de cache idéalisé
En général, un programme peut être rendu plus sensible à la mise en cache :
- Localité temporelle , où l'algorithme récupère plusieurs fois les mêmes morceaux de mémoire ;
- Localité spatiale , où les accès mémoire suivants sont des adresses mémoire adjacentes ou proches .
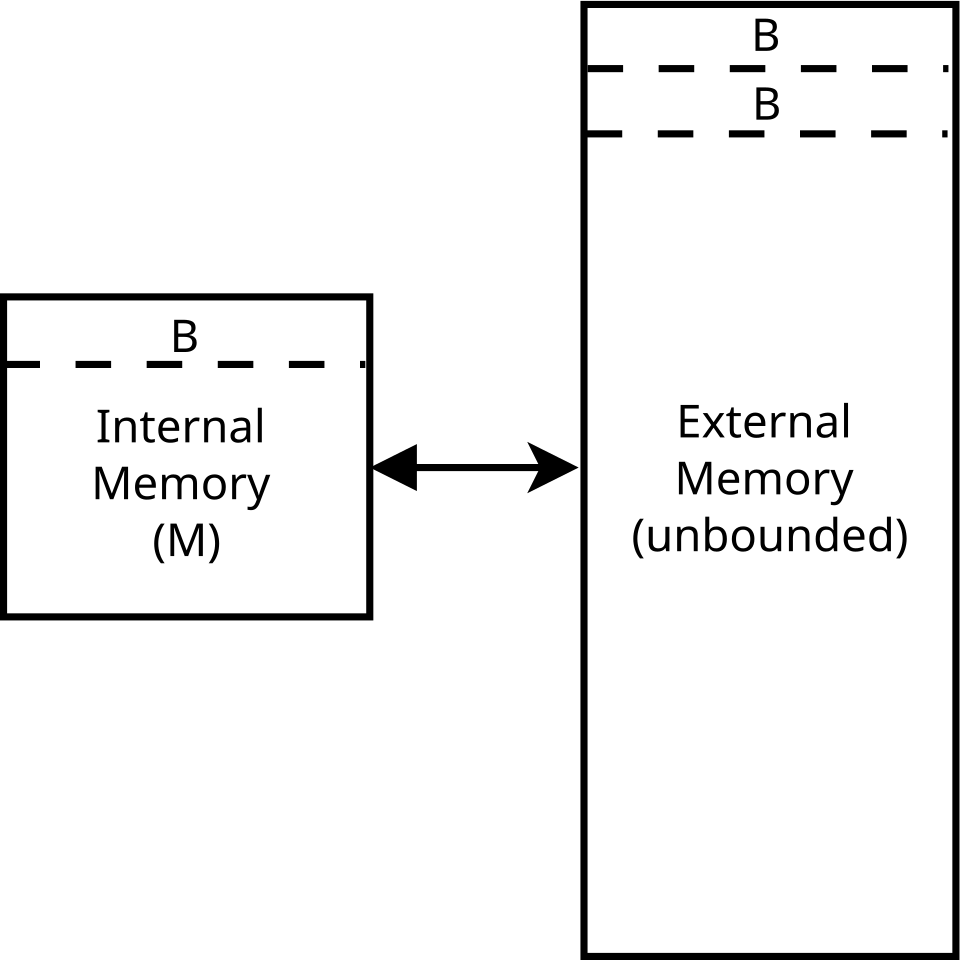
Les algorithmes indépendants du cache sont généralement analysés à l'aide d'un modèle idéalisé de ce dernier, parfois appelé modèle sans cache . Ce modèle est beaucoup plus simple à analyser que les caractéristiques réelles d'un cache (qui présentent une associativité complexe, des politiques de remplacement, etc.), mais dans de nombreux cas, ses performances sont, à un facteur constant près, modèle de mémoire externe car les algorithmes indépendants du cache ne connaissent ni la taille des blocs ni la taille du cache .
Plus précisément, le modèle sans cache est une machine abstraite (c'est-à-dire un modèle théorique de calcul ). Il est similaire au modèle de machine RAM , qui remplace le ruban infini de la machine de Turing par un tableau infini. Chaque emplacement du tableau est accessible en temps réel, à l'instar de la mémoire vive d'un ordinateur. Contrairement au modèle de machine RAM, il introduit également un cache : un second niveau de stockage entre la RAM et le processeur. Les autres différences entre les deux modèles sont énumérées ci-dessous. Dans le modèle sans cache :
Exemples

L'algorithme le plus simple, insensible au cache, présenté dans Frigo et al., est une transposition de matrice hors place ( des algorithmes sur place ont également été conçus pour la transposition, mais ils sont beaucoup plus complexes pour les matrices non carrées). Étant donné un tableau A de dimensions m × n et un tableau B de dimensions n × m , nous souhaitons stocker la transposée de
L'algorithme insensible au cache présente une complexité de travail et une complexité de cache optimales . L'idée principale est de réduire la transposée de deux grandes matrices à la transposée de petites (sous-)matrices. Pour ce faire, on divise les matrices en deux selon leur plus grande dimension jusqu'à n'avoir plus qu'à transposer une matrice pouvant tenir dans le cache. La taille du cache étant inconnue de l'algorithme, les matrices continuent d'être divisées récursivement, même après ce point, mais ces subdivisions supplémentaires sont stockées dans le cache. Dès que les dimensions
(En principe, on pourrait continuer à diviser les matrices jusqu'à atteindre un cas de base de taille 1 × 1, mais en pratique, on utilise un cas de base plus grand (par exemple 16 × 16) afin d' amortir la surcharge des appels de sous-routines récursives.)
La plupart des algorithmes insensibles au cache reposent sur une approche de type « diviser pour régner ». Ils réduisent le problème afin qu'il tienne finalement dans le cache, quelle que soit sa taille, et arrêtent la récursion à une petite taille déterminée par la surcharge des appels de fonction et d'autres optimisations similaires non liées au cache. Ils utilisent ensuite un modèle d'accès efficace au cache pour fusionner les résultats de ces petits problèmes résolus.
À l'instar du tri externe dans le modèle de mémoire externe , le tri indépendant du cache se décline en deux variantes : le tri en entonnoir , qui s'apparente au tri fusion ; et le tri par distribution indépendant du cache , qui s'apparente au tri rapide . Comme leurs homologues en mémoire externe, les deux atteignent un temps d'exécution de O(n log n) , ce qui correspond à une borne inférieure et est donc asymptotiquement optimal .
aspect pratique
Une comparaison empirique de 2 algorithmes basés sur la RAM, 1 algorithme prenant en compte le cache et 2 algorithmes ignorant le cache implémentant des files d'attente prioritaires a révélé que :
- Les algorithmes ne tenant pas compte du cache ont obtenu des performances inférieures à celles des algorithmes basés sur la RAM et prenant en compte le cache lorsque les données tiennent dans la mémoire principale.
- L'algorithme prenant en compte le cache ne semblait pas significativement plus complexe à mettre en œuvre que les algorithmes ne tenant pas compte du cache, et a offert les meilleures performances dans tous les cas testés dans l'étude.
- Les algorithmes ne tenant pas compte du cache ont surpassé les algorithmes basés sur la RAM lorsque la taille des données dépassait celle de la mémoire principale.
Une autre étude a comparé les tables de hachage (basées sur la RAM ou ne tenant pas compte du cache), les arbres B (tenant compte du cache) et une structure de données insensible au cache appelée « ensemble de Bender ». En termes de temps d'exécution et d'utilisation de la mémoire, la table de hachage s'est avérée la plus performante, suivie de l'arbre B, l'ensemble de Bender étant le moins performant dans tous les cas. L'utilisation de la mémoire pour tous les tests n'a pas dépassé la mémoire principale. Les tables de hachage ont été décrites comme faciles à implémenter, tandis que l'ensemble de Bender « nécessitait un effort plus important pour être implémenté correctement ».