En informatique , la recherche binaire , également appelée recherche par demi-intervalle , recherche logarithmique [ ou par découpage binaire est un algorithme de recherche qui ...
Worldlex WikiContenu en francaisLecture gratuite
informatique , la recherche binaire , également appelée recherche par demi-intervalle , recherche logarithmique [ ou par découpage binaire est un algorithme de recherche qui trouve la position d'une valeur cible dans un tableau trié . La recherche binaire compare la valeur cible à l'élément médian du tableau. Si ces deux éléments sont différents, la moitié du tableau où la cible ne peut pas se trouver est éliminée et la recherche se poursuit sur la moitié restante, en comparant à nouveau l'élément médian à la valeur cible, et ce jusqu'à ce que la valeur cible soit trouvée. Si la recherche s'achève et que la moitié restante est vide, la cible n'est pas présente dans le tableau.
La recherche binaire s'exécute en temps logarithmique dans le pire des cas , effectuant O( n) comparaisons, où n est le nombre d'éléments du tableau. La recherche binaire est plus rapide que la recherche linéaire, sauf pour les petits tableaux. Cependant, le tableau doit être trié au préalable pour pouvoir appliquer la recherche binaire. Il existe des structures de données spécialisées pour la recherche rapide, telles que les tables de hachage , qui permettent une recherche plus efficace que la recherche binaire. Néanmoins, la recherche binaire peut être utilisée pour résoudre un plus large éventail de problèmes, comme trouver l'élément immédiatement inférieur ou supérieur à l'élément cible dans le tableau, même si celui-ci est absent.
des enregistrements triés de telle sorte que , et une valeur cible , la sous-routine suivante utilise la recherche binaire pour trouver l'index de dans .
Définissez à et à .
Si , la recherche s'arrête comme infructueuse.R" R
Définir (la position de l'élément du milieu) à plus la partie entière de , qui est le plus grand entier inférieur ou égal à .
Si , définissez sur et passez à l'étape 2.
Si , définissez sur et passez à l'étape 2. T" T
La recherche est maintenant terminée ; retournez .
Cette procédure itérative suit les limites de recherche à l'aide des deux variables et . La procédure peut être exprimée en pseudocode comme suit, où les noms et les types des variables restent les mêmes que ci-dessus, est la fonction partie entière , et fait référence à une valeur spécifique qui indique l'échec de la recherche. floorunsuccessful
recherche binaire
la fonction binary_search(A, n, T) est L := 0 R := n − 1 tant que L ≤ R faire m := L + partie entière((R - L) / 2) si A[m] < T alors L := m + 1 sinon si A[m] > T alors R := m − 1 sinon : retourner m retourner échec
L'algorithme peut également prendre la valeur maximale . Cela peut modifier le résultat si la valeur cible apparaît plusieurs fois dans le tableau.
Procédure alternative
Dans la procédure décrite ci-dessus, l'algorithme vérifie à chaque itération si l'élément du milieu ( ) est égal à la cible ( ). Certaines implémentations omettent cette vérification à chaque itération. L'algorithme effectue alors cette vérification uniquement lorsqu'il ne reste qu'un seul élément (lorsque ). Il en résulte une boucle de comparaison plus rapide, car une comparaison est éliminée à chaque itération, pour un temps d'exécution supplémentaire d'une seule itération en moyenne.
Hermann Bottenbruch a publié la première implémentation omettant cette vérification en 1962.
Définissez à et à .
Alors que ,
Définir (la position de l'élément du milieu) à plus le plafond de , qui est le plus petit entier supérieur ou égal à .
Si , définissez sur . T" T
Sinon, ; définir sur .
La recherche est maintenant terminée. Si la recherche a échoué, la fonction retourne ` true`. Sinon, la recherche est considérée comme infructueuse.
Où ceilse trouve la fonction plafond ? Le pseudocode de cette version est :
la fonction binary_search_alternative(A, n, T) est L := 0 R := n − 1 tant que L != R faire m := L + ceil((R - L) / 2) si A[m] > T alors R := m − 1 sinon : L := m Si A[L] = V, alors retourner L. Retourner échec.
Éléments dupliqués
La procédure peut renvoyer n'importe quel index dont l'élément est égal à la valeur cible, même en présence d'éléments dupliqués dans le tableau. Par exemple, si le tableau à parcourir est et la cible est , l'algorithme renverra correctement soit le 4e élément (index 3), soit le 5e (index 4). La procédure classique renverrait le 4e élément (index 3) dans ce cas. Elle ne renvoie pas toujours le premier doublon (considérons qui renvoie toujours le 4e élément). Cependant, il est parfois nécessaire de trouver l'élément le plus à gauche ou le plus à droite pour une valeur cible dupliquée dans le tableau. Dans l'exemple ci-dessus, le 4e élément est l'élément le plus à gauche de la valeur 4, tandis que le 5e élément est l'élément le plus à droite de la valeur 4. La procédure alternative ci-dessus renverra toujours l'index de l'élément le plus à droite s'il existe.
Procédure pour trouver l'élément le plus à gauche
Pour trouver l'élément le plus à gauche, la procédure suivante peut être utilisée :
Définissez à et à .
Alors que ,
Définir (la position de l'élément du milieu) à plus la partie entière de , qui est le plus grand entier inférieur ou égal à .
Si , définissez sur .
Sinon, ; définir sur .
Retour .
Si et , alors est l'élément le plus à gauche qui est égal à . Même si n'est pas dans le tableau, est le rang de dans le tableau, ou le nombre d'éléments du tableau qui sont inférieurs à .
Où floorse trouve la fonction plancher ? Le pseudocode de cette version est :
fonction binary_search_leftmost(A, n, T): L := 0 R := n tandis que L < R : m := L + partie entière((R - L) / 2) si A[m] < T : L := m + 1 autre : R := m retour L
Procédure pour trouver l'élément le plus à droite
Pour trouver l'élément le plus à droite, la procédure suivante peut être utilisée :
Définissez à et à .
Alors que ,
Définir (la position de l'élément du milieu) à plus la partie entière de , qui est le plus grand entier inférieur ou égal à .
Si , définissez sur . T" T
Sinon, ; définir sur .
Retour .
Si et , alors est l'élément le plus à droite qui est égal à . Même si n'est pas dans le tableau, est le nombre d'éléments du tableau qui sont supérieurs à . 0" 0
Où floorse trouve la fonction plancher ? Le pseudocode de cette version est :
fonction binary_search_rightmost(A, n, T): L := 0 R := n tandis que L < R : m := L + partie entière((R - L) / 2) si A[m] > T : R := m autre : L := m + 1 retour R - 1
Correspondances approximatives
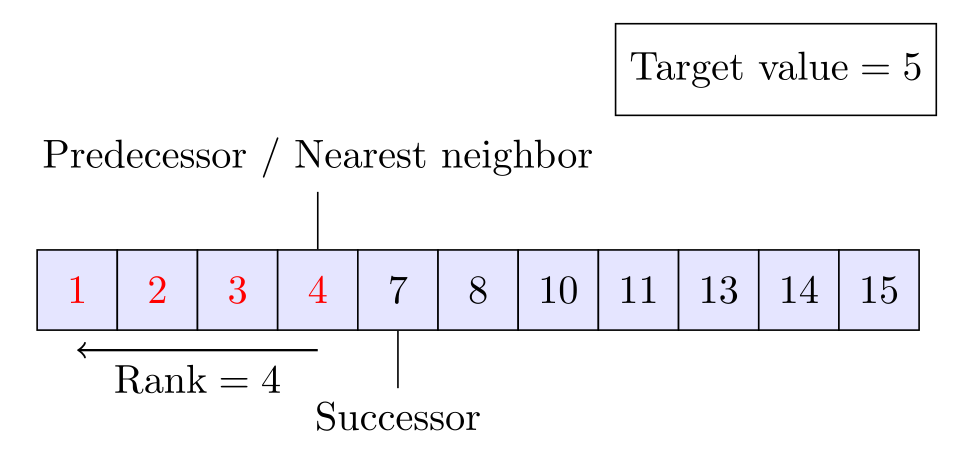
La recherche binaire peut être adaptée pour calculer des correspondances approximatives. Dans l'exemple ci-dessus, le rang, le prédécesseur, le successeur et le plus proche voisin sont affichés pour la valeur cible , qui ne figure pas dans le tableau.
La procédure décrite ci-dessus ne permet que des correspondances exactes , en trouvant la position d'une valeur cible. Cependant, il est simple d'étendre la recherche binaire aux correspondances approximatives, car elle opère sur des tableaux triés. Par exemple, la recherche binaire peut être utilisée pour calculer, pour une valeur donnée, son rang (le nombre d'éléments inférieurs), son prédécesseur (l'élément immédiatement inférieur), son successeur (l'élément immédiatement supérieur) et son plus proche voisin . Les requêtes d'intervalle, qui cherchent le nombre d'éléments entre deux valeurs, peuvent être effectuées avec deux requêtes de rang.
Les requêtes de prédécesseur peuvent être effectuées avec des requêtes de rang. Si le rang de la valeur cible est , son prédécesseur est .
Pour les requêtes de successeur, la procédure de recherche de l'élément le plus à droite peut être utilisée. Si le résultat de l'exécution de la procédure pour la valeur cible est , alors le successeur de la valeur cible est .
La valeur la plus proche de la valeur cible est soit son prédécesseur, soit son successeur, selon celui qui est le plus proche.
Les requêtes par intervalle sont également simples. Une fois les rangs des deux valeurs connus, le nombre d'éléments supérieurs ou égaux à la première valeur et inférieurs à la seconde correspond à la différence entre ces deux rangs. Ce nombre peut être ajusté de un selon que les bornes de l'intervalle doivent être considérées comme faisant partie de celui-ci et selon que le tableau contient ou non des entrées correspondant à ces bornes.
Performance
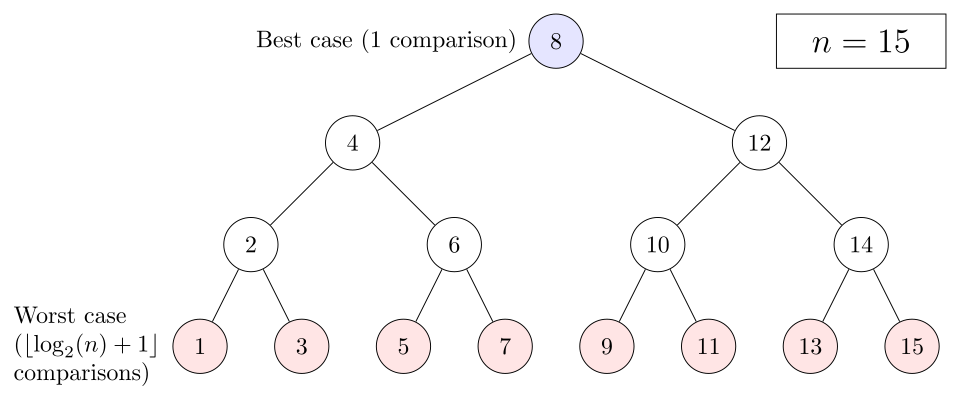
Un arbre représentant la recherche binaire. Le tableau recherché est , et la valeur cible est .Le pire des cas se produit lorsque la recherche atteint le niveau le plus profond de l'arbre, tandis que le meilleur des cas se produit lorsque la valeur cible est l'élément médian.
En termes de nombre de comparaisons, les performances de la recherche binaire peuvent être analysées en observant son exécution sur un arbre binaire. Le nœud racine de l'arbre est l'élément médian du tableau. L'élément médian de la moitié inférieure est le nœud enfant gauche de la racine, et l'élément médian de la moitié supérieure est le nœud enfant droit de la racine. Le reste de l'arbre est construit de manière similaire. À partir du nœud racine, les sous-arbres gauche ou droit sont parcourus selon que la valeur cible est inférieure ou supérieure à celle du nœud considéré.
Dans le pire des cas, la recherche binaire effectue des itérations de la boucle de comparaison, où la notation désigne la fonction partie entière qui renvoie le plus grand entier inférieur ou égal à l'argument, et représente le logarithme binaire . En effet, le pire cas est atteint lorsque la recherche atteint le niveau le plus profond de l'arbre, et il y a toujours des niveaux dans un arbre pour toute recherche binaire.
Le pire des cas peut également se produire lorsque l'élément cible n'est pas présent dans le tableau. Si n est inférieur de 1 à une puissance de deux , alors c'est toujours le cas. Sinon, la recherche peut effectuer n itérations si elle atteint le niveau le plus profond de l'arbre. Cependant, elle peut effectuer n itérations, soit une de moins que dans le pire des cas, si la recherche s'arrête au deuxième niveau le plus profond de l'arbre.
En moyenne, en supposant que chaque élément a la même probabilité d'être recherché, la recherche binaire effectue N itérations lorsque l'élément cible est présent dans le tableau. Ce nombre est approximativement égal à N itérations. Lorsque l'élément cible n'est pas présent dans le tableau, la recherche binaire effectue en moyenne N itérations, en supposant que la plage entre les éléments et les éléments extérieurs a la même probabilité d'être explorée.
Dans le meilleur des cas, lorsque la valeur cible est l'élément du milieu du tableau, sa position est renvoyée après une itération.
En termes d'itérations, aucun algorithme de recherche fonctionnant uniquement par comparaison d'éléments ne peut offrir de meilleures performances moyennes et dans le pire des cas que la recherche binaire. L'arbre de comparaison représentant la recherche binaire possède le moins de niveaux possible, car chaque niveau supérieur au niveau le plus bas est entièrement rempli. Autrement, l'algorithme de recherche peut éliminer certains éléments lors d'une itération, augmentant ainsi le nombre d'itérations nécessaires en moyenne et dans le pire des cas. C'est le cas pour d'autres algorithmes de recherche basés sur des comparaisons : bien qu'ils puissent être plus rapides sur certaines valeurs cibles, leurs performances moyennes sur l'ensemble des éléments sont inférieures à celles de la recherche binaire. En divisant le tableau en deux, la recherche binaire garantit que la taille des deux sous-tableaux est aussi similaire que possible.
Complexité spatiale
La recherche binaire nécessite trois pointeurs vers les éléments, qui peuvent être des indices de tableau ou des pointeurs vers des adresses mémoire, quelle que soit la taille du tableau. Par conséquent, la complexité spatiale de la recherche binaire est de l' ordre du modèle RAM .
Dérivation du cas moyen
Le nombre moyen d'itérations effectuées par la recherche dichotomique dépend de la probabilité de trouver chaque élément. Ce nombre moyen diffère selon que la recherche aboutit ou non. On supposera que chaque élément a la même probabilité d'être trouvé lors d'une recherche aboutie. En cas d'échec, on supposera que les intervalles entre les éléments et ceux qui les entourent ont la même probabilité d'être trouvés. Le nombre moyen d'itérations nécessaires pour une recherche aboutie correspond au nombre d'itérations requises pour trouver chaque élément une seule fois, divisé par le nombre d'éléments. Le nombre moyen d'itérations nécessaires pour un échec correspond au nombre d'itérations requises pour trouver un élément dans chaque intervalle une seule fois, divisé par le nombre d'intervalles.
Recherches réussies
Dans la représentation arborescente binaire, une recherche fructueuse est représentée par un chemin allant de la racine au nœud cible, appelé chemin interne . La longueur d'un chemin correspond au nombre d'arêtes (connexions entre les nœuds) qu'il traverse. Le nombre d'itérations effectuées par une recherche, sachant que le chemin correspondant a une longueur
Étant donné que la recherche binaire est l'algorithme optimal pour la recherche avec comparaisons, ce problème se réduit au calcul de la longueur minimale du chemin interne de tous les arbres binaires à
Par exemple, dans un tableau à 7 éléments, la racine nécessite une itération, les deux éléments situés en dessous de la racine nécessitent deux itérations et les quatre éléments situés en dessous nécessitent trois itérations. Dans ce cas, la longueur du chemin interne est :
Le nombre moyen d'itérations serait basé sur l'équation du cas moyen. La somme peut être simplifiée à :
En substituant l'équation de dans l'équation de :
Pour un entier
Ce problème peut également être ramené à la détermination de la longueur minimale du chemin externe de tous les arbres binaires comportant nœuds. Pour tous les arbres binaires, la longueur du chemin externe est égale à la longueur du chemin interne plus . En substituant l'équation dans :
En substituant l'équation de dans l'équation de , le cas moyen des recherches infructueuses peut être déterminé :
Exécution de la procédure alternative
Chaque itération de la procédure de recherche binaire définie ci-dessus effectue une ou deux comparaisons, vérifiant à chaque itération si l'élément médian est égal à la cible. En supposant que chaque élément a la même probabilité d'être recherché, chaque itération effectue en moyenne 1,5 comparaison. Une variante de l'algorithme vérifie si l'élément médian est égal à la cible à la fin de la recherche. En moyenne, cela élimine une demi-comparaison par itération. Ceci réduit légèrement le temps d'exécution par itération sur la plupart des ordinateurs. Cependant, cela garantit que la recherche effectue le nombre maximal d'itérations, ajoutant en moyenne une itération à la recherche. Étant donné que la boucle de comparaison n'est exécutée que fois dans le pire des cas, le léger gain d'efficacité par itération ne compense pas l'itération supplémentaire, sauf pour des valeurs de N très élevées .
Considérations supplémentaires
Coût de la comparaison
Lors de l'analyse des performances de la recherche binaire, il convient également de considérer le temps nécessaire à la comparaison de deux éléments. Pour les entiers et les chaînes de caractères, ce temps augmente linéairement avec la longueur de leur encodage (généralement le nombre de bits ). Par exemple, comparer deux entiers non signés de 64 bits nécessite de comparer jusqu'à deux fois plus de bits que pour comparer deux entiers non signés de 32 bits. Le pire des cas est atteint lorsque les entiers sont égaux. Cela peut s'avérer significatif lorsque la longueur d'encodage des éléments est importante, comme c'est le cas pour les grands entiers ou les longues chaînes de caractères, ce qui rend la comparaison coûteuse. De plus, la comparaison de valeurs à virgule flottante (la représentation numérique la plus courante des nombres réels ) est souvent plus coûteuse que la comparaison d'entiers ou de chaînes de caractères courtes.
La comparaison rapide de nombres à virgule flottante est possible en les comparant comme des entiers. Cependant, ce type de comparaison établit un ordre total , ce qui fait que chaque valeur à virgule flottante est comparée différemment des autres et identique à elle-même. Ceci diffère de la comparaison classique où -0,0 est identique à 0,0 et NaN est différent de toute autre valeur, y compris de lui-même.
Sur la plupart des architectures informatiques, le processeur dispose d'un cache matériel distinct de la RAM . Situé au sein même du processeur, le cache offre un accès beaucoup plus rapide, mais stocke généralement beaucoup moins de données que la RAM. Par conséquent, la plupart des processeurs conservent en mémoire les emplacements récemment accédés, ainsi que les emplacements proches. Par exemple, lors de l'accès à un élément d'un tableau, cet élément peut être stocké en RAM avec les éléments voisins, ce qui accélère l'accès séquentiel aux éléments proches ( localité de référence ). Sur un tableau trié, la recherche binaire peut accéder à des emplacements mémoire éloignés si le tableau est volumineux, contrairement aux algorithmes (tels que la recherche linéaire et le sondage linéaire dans les tables de hachage ) qui accèdent aux éléments séquentiellement. Ceci augmente légèrement le temps d'exécution de la recherche binaire pour les grands tableaux sur la plupart des systèmes.
Paul Khuong a constaté que la recherche binaire sur de grands tableaux (≥ 512 Kio) dont la taille est une puissance de deux engendre un problème supplémentaire lié à l'implémentation des caches du processeur. Plus précisément, le tampon de traduction d'adresses (TLB) est souvent implémenté comme une mémoire adressable par contenu (CAM), la « clé » étant généralement constituée des bits de poids faible de l'adresse demandée. Lors d'une recherche sur un tableau dont la taille est une puissance de deux, les adresses mémoire ayant les mêmes bits de poids faible sont fréquemment accédées, ce qui provoque des collisions (« aliasing ») avec la « clé » utilisée pour accéder à la CAM. Un TLB typique est associatif à 4 voies, ce qui signifie qu'il peut gérer au maximum quatre adresses accédant à la même « clé », au-delà desquelles un phénomène de saturation du TLB se produit. (Bien que les autres niveaux de cache du processeur utilisent également une configuration similaire, ils gèrent des zones plus petites avec un nombre de voies plus élevé, généralement 8 ou 16, et sont donc moins affectés.) On peut éviter ce problème en décalant le point de division de la recherche binaire afin qu'il divise à au lieu d'exactement au milieu. 24
Recherche binaire comparée à d'autres méthodes
Les tableaux triés associés à la recherche binaire constituent une solution très inefficace lorsque les opérations d'insertion et de suppression sont entrelacées avec la recherche, chaque opération prenant du temps. De plus, les tableaux triés peuvent complexifier l'utilisation de la mémoire, notamment lorsque des éléments y sont fréquemment insérés. D'autres structures de données permettent des insertions et des suppressions bien plus efficaces. La recherche binaire peut être utilisée pour effectuer des correspondances exactes et déterminer l'appartenance à un ensemble (si une valeur cible est présente dans un ensemble de valeurs). Certaines structures de données permettent des correspondances exactes et des déterminations d'appartenance à un ensemble plus rapides. Cependant, contrairement à de nombreux autres algorithmes de recherche, la recherche binaire permet des correspondances approximatives efficaces, généralement réalisées en un temps donné, indépendamment du type ou de la structure des valeurs. Par ailleurs, certaines opérations, comme la recherche du plus petit et du plus grand élément, peuvent être effectuées efficacement sur un tableau trié.
Recherche linéaire
La recherche linéaire est un algorithme de recherche simple qui parcourt chaque enregistrement jusqu'à trouver la valeur cible. Elle peut être effectuée sur une liste chaînée , ce qui permet des insertions et des suppressions plus rapides que sur un tableau. La recherche binaire est plus rapide que la recherche linéaire pour les tableaux triés, sauf si le tableau est court, auquel cas il faut le trier au préalable. Tous les algorithmes de tri basés sur la comparaison d'éléments, tels que le tri rapide et le tri fusion , nécessitent au moins n comparaisons dans le pire des cas. Contrairement à la recherche linéaire, la recherche binaire peut être utilisée pour une correspondance approximative efficace. Certaines opérations, comme la recherche du plus petit et du plus grand élément, peuvent être effectuées efficacement sur un tableau trié, mais pas sur un tableau non trié.
Un arbre binaire de recherche est une structure de données arborescente binaire fonctionnant selon le principe de la recherche binaire. Les enregistrements de l'arbre sont triés et chaque enregistrement peut être recherché à l'aide d'un algorithme similaire à la recherche binaire, en un temps logarithmique moyen. L'insertion et la suppression nécessitent également un temps logarithmique moyen dans les arbres binaires de recherche. Ceci peut être plus rapide que l'insertion et la suppression en temps linéaire dans les tableaux triés, et les arbres binaires conservent la capacité d'effectuer toutes les opérations possibles sur un tableau trié, y compris les requêtes par intervalle et les requêtes approximatives.
Cependant, la recherche binaire est généralement plus efficace car les arbres binaires de recherche sont souvent imparfaitement équilibrés, ce qui entraîne des performances légèrement inférieures à celles de la recherche binaire classique. Ceci s'applique même aux arbres binaires de recherche équilibrés (c'est-à-dire ceux qui équilibrent leurs propres nœuds), car ils produisent rarement l'arbre avec le moins de niveaux possible. Hormis les arbres binaires de recherche équilibrés, l'arbre peut être fortement déséquilibré, avec peu de nœuds internes ayant deux enfants, ce qui fait que le temps de recherche moyen et dans le pire des cas se rapproche des comparaisons. Les arbres binaires de recherche occupent plus d'espace que les tableaux triés.
Les arbres binaires de recherche se prêtent à une recherche rapide dans la mémoire externe stockée sur les disques durs, car ils peuvent être structurés efficacement dans les systèmes de fichiers. L' arbre B généralise cette méthode d'organisation arborescente. Les arbres B sont fréquemment utilisés pour organiser le stockage à long terme, comme les bases de données et les systèmes de fichiers .
Hachage
Pour l'implémentation de tableaux associatifs , les tables de hachage , une structure de données qui associe des clés à des enregistrements à l'aide d'une fonction de hachage , sont généralement plus rapides que la recherche binaire sur un tableau trié d'enregistrements. La plupart des implémentations de tables de hachage nécessitent un temps constant amorti en moyenne. Cependant, le hachage est inefficace pour les correspondances approximatives, telles que le calcul de la clé immédiatement inférieure, de la clé immédiatement supérieure et de la clé la plus proche, car la seule information fournie lors d'une recherche infructueuse est que la cible est absente de tout enregistrement. La recherche binaire est idéale pour ce type de correspondances, qu'elle effectue en temps logarithmique. La recherche binaire prend également en charge les correspondances approximatives. Certaines opérations, comme la recherche du plus petit et du plus grand élément, peuvent être réalisées efficacement sur des tableaux triés, mais pas sur des tables de hachage.
algorithmes d'appartenance à un ensemble
Un problème connexe à la recherche est celui de l'appartenance à un ensemble . Tout algorithme de recherche, comme la recherche binaire, peut également être utilisé pour l'appartenance à un ensemble. D'autres algorithmes sont plus spécifiquement adaptés à cette tâche. Un tableau de bits est le plus simple et s'avère utile lorsque l'intervalle de clés est limité. Il stocke de manière compacte une collection de bits , chaque bit représentant une clé unique de l'intervalle. Les tableaux de bits sont très rapides et ne nécessitent qu'un temps d'exécution. Le type Judy1 du tableau de Judy gère efficacement les clés de 64 bits.
Pour obtenir des résultats approximatifs, les filtres de Bloom , une autre structure de données probabiliste basée sur le hachage, stockent un ensemble de clés en les encodant à l'aide d'un tableau de bits et de plusieurs fonctions de hachage. Les filtres de Bloom sont généralement beaucoup plus compacts que les tableaux de bits et à peine plus lents : avec les fonctions de hachage, les requêtes d'appartenance ne prennent que du temps. Cependant, les filtres de Bloom sont sujets aux faux positifs .
Autres structures de données
Il existe des structures de données qui peuvent, dans certains cas, améliorer la recherche binaire, tant pour la recherche que pour d'autres opérations disponibles sur les tableaux triés. Par exemple, les recherches, les correspondances approximatives et les opérations disponibles sur les tableaux triés peuvent être effectuées plus efficacement que la recherche binaire sur des structures de données spécialisées telles que les arbres de van Emde Boas , les arbres de fusion , les tries et les tableaux de bits . Ces structures de données spécialisées sont généralement plus rapides car elles tirent parti des propriétés des clés possédant un certain attribut (généralement des clés de petits entiers), et seront donc gourmandes en temps ou en espace pour les clés dépourvues de cet attribut. Tant que les clés peuvent être ordonnées, ces opérations peuvent toujours être effectuées au moins efficacement sur un tableau trié, quelles que soient les clés. Certaines structures, comme les tableaux de Judy, utilisent une combinaison d'approches pour atténuer ce problème tout en conservant l'efficacité et la possibilité d'effectuer des correspondances approximatives.
Variations
Recherche binaire uniforme
La recherche binaire uniforme stocke la différence entre l'élément médian actuel et les deux éléments médians suivants possibles au lieu de limites spécifiques.
La recherche binaire uniforme stocke, au lieu des bornes inférieure et supérieure, la différence d'indice de l'élément médian entre l'itération courante et la suivante. Une table de correspondance contenant ces différences est calculée au préalable. Par exemple, si le tableau à parcourir est les ordinateurs décimaux .
Recherche exponentielleVisualisation de la recherche exponentielle permettant de trouver la borne supérieure de la recherche binaire suivante
La recherche exponentielle étend la recherche binaire aux listes non bornées. Elle commence par trouver le premier élément dont l'indice est une puissance de deux et supérieur à la valeur cible. Cet indice est ensuite défini comme la borne supérieure, et la recherche binaire s'effectue en plusieurs étapes. Une recherche exponentielle prend itérations avant le début de la recherche binaire, et au plus itérations pour la recherche binaire elle-même, où représente la position de la valeur cible. La recherche exponentielle fonctionne sur les listes bornées, mais ne constitue une amélioration par rapport à la recherche binaire que si la valeur cible se situe en début de tableau.
Recherche par interpolation
Visualisation de la recherche par interpolation linéaire. Dans ce cas, aucune recherche n'est nécessaire car l'estimation de la position de la cible dans le tableau est correcte. D'autres implémentations peuvent utiliser une autre fonction pour estimer cette position.
Au lieu de calculer le point médian, la recherche par interpolation estime la position de la valeur cible en tenant compte des éléments minimum et maximum du tableau, ainsi que de sa longueur. Elle repose sur le principe que le point médian n'est pas toujours la meilleure estimation. Par exemple, si la valeur cible est proche de l'élément maximum du tableau, elle se situe probablement vers la fin de celui-ci.
Une fonction d'interpolation courante est l'interpolation linéaire . Si représente le tableau, et respectivement les bornes inférieure et supérieure, et la cible, alors la cible est estimée à environ la distance entre et . Lorsque l'interpolation linéaire est utilisée et que la distribution des éléments du tableau est uniforme ou quasi uniforme, la recherche par interpolation effectue des comparaisons.
En pratique, la recherche par interpolation est plus lente que la recherche binaire pour les petits tableaux, car elle nécessite des calculs supplémentaires. Sa complexité temporelle augmente moins vite que celle de la recherche binaire, mais cela ne compense les calculs supplémentaires que pour les grands tableaux.
cascade fractionnaire
Dans la cascade fractionnaire , chaque tableau possède des pointeurs vers un élément sur deux d'un autre tableau, de sorte qu'une seule recherche binaire doit être effectuée pour parcourir tous les tableaux.
Le fractionnement en cascade est une technique qui accélère la recherche binaire d'un même élément dans plusieurs tableaux triés. La recherche dans chaque tableau séparément nécessite un temps O(n), où n est le nombre de tableaux. Le fractionnement en cascade réduit ce temps à O ( n) en stockant dans chaque tableau des informations spécifiques sur chaque élément et sa position dans les autres tableaux.
La recherche binaire a été généralisée pour fonctionner sur certains types de graphes, où la valeur cible est stockée dans un sommet plutôt que dans un élément de tableau. Les arbres binaires de recherche constituent une de ces généralisations : lorsqu'un sommet (nœud) de l'arbre est interrogé, l'algorithme détermine soit que ce sommet est la cible, soit dans quel sous-arbre se trouve la cible. Cependant, cette généralisation peut être étendue comme suit : étant donné un graphe non orienté à pondération positive et un sommet cible, l'algorithme détermine, lors de l'interrogation d'un sommet, que ce sommet est égal à la cible, ou bien il reçoit une arête incidente appartenant au plus court chemin reliant le sommet interrogé à la cible. L'algorithme de recherche binaire standard correspond simplement au cas où le graphe est un chemin. De même, les arbres binaires de recherche correspondent au cas où les arêtes vers les sous-arbres gauche ou droit sont fournies lorsque le sommet interrogé est différent de la cible. Pour tout graphe non orienté à pondération positive, il existe un algorithme qui trouve le sommet cible lors des requêtes dans le pire des cas.
Recherche binaire bruyante
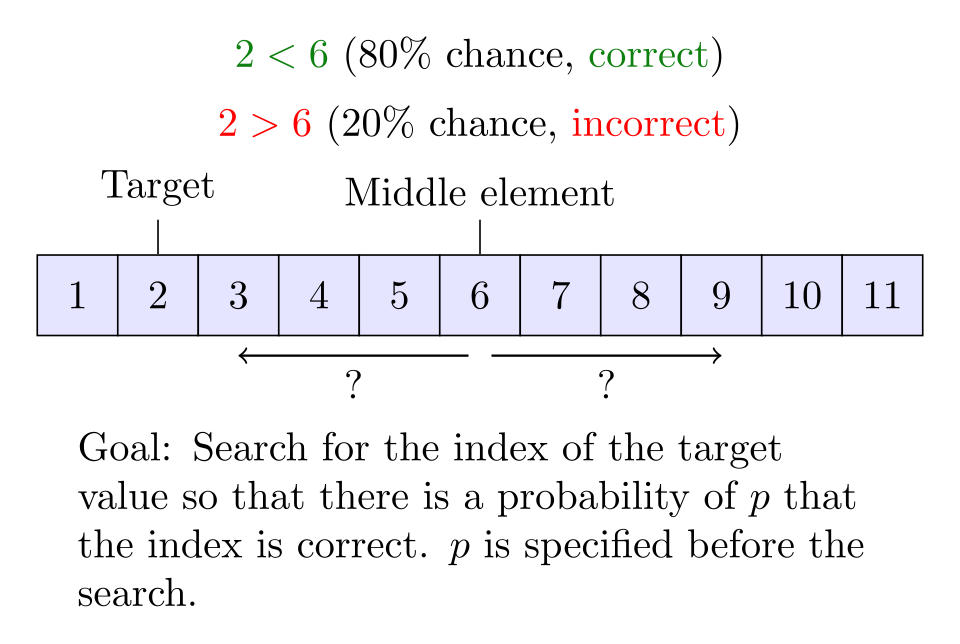
Dans la recherche binaire bruitée, il existe une certaine probabilité qu'une comparaison soit incorrecte.
Les algorithmes de recherche binaire bruitée résolvent le cas où l'algorithme ne peut comparer de manière fiable les éléments du tableau. Pour chaque paire d'éléments, il existe une certaine probabilité que l'algorithme effectue une comparaison erronée. La recherche binaire bruitée peut trouver la position correcte de la cible avec une probabilité donnée qui contrôle la fiabilité de la position obtenue. Toute procédure de recherche binaire bruitée doit effectuer au moins comparaisons en moyenne, où est la fonction d'entropie binaire et est la probabilité que la procédure aboutisse à une position erronée. Le problème de la recherche binaire bruitée peut être considéré comme un cas du jeu de Rényi-Ulam , une variante du jeu des vingt questions où les réponses peuvent être incorrectes.
Recherche binaire quantique
Les ordinateurs classiques sont limités à un nombre d'itérations exact dans le pire des cas lors d'une recherche binaire. Les algorithmes quantiques de recherche binaire sont également limités à un nombre proportionnel de requêtes (représentant les itérations de la procédure classique), mais le facteur constant est inférieur à un, ce qui permet une complexité temporelle plus faible sur les ordinateurs quantiques . Toute procédure de recherche binaire quantique exacte — c'est-à-dire une procédure qui donne toujours le bon résultat — requiert au moins requêtes dans le pire des cas, où est le logarithme népérien . Il existe une procédure de recherche binaire quantique exacte qui s'exécute en requêtes dans le pire des cas. À titre de comparaison, l'algorithme de Grover est l'algorithme quantique optimal pour la recherche dans une liste non ordonnée d'éléments, et il requiert requêtes.
Histoire
L'idée de trier une liste d'éléments pour faciliter la recherche remonte à l'Antiquité. Le plus ancien exemple connu est la tablette Inakibit-Anu de Babylone, datant d'environ 200 sexagésimaux et leurs inverses , classés par ordre lexicographique , ce qui simplifiait la recherche d'une entrée spécifique. Par ailleurs, plusieurs listes de noms triés par leur première lettre ont été découvertes dans les îles de la mer Égée . Le Catholicon , un dictionnaire latin achevé en 1286, fut le premier ouvrage à décrire des règles de classement des mots par ordre alphabétique, et non plus seulement par leurs premières lettres.
En 1946, John Mauchly mentionna pour la première fois la recherche binaire dans le cadre des Moore School Lectures , un cours universitaire fondamental en informatique. En 1957, William Wesley Peterson publia la première méthode de recherche par interpolation. Jusqu'en 1960, tous les algorithmes de recherche binaire publiés ne fonctionnaient que pour les tableaux dont la longueur était inférieure d'une unité à une puissance de deux −1\". [[On-Line Encyclopedia of Integer Sequences|OEIS]] [http://oeis.org/A000225 A000225] {{Webarchive|url=https://web.archive.org/web/20160608084228/http://oeis.org/A000225 |date=8 June 2016 }}. Retrieved 7 May 2016."}},"i":0}}] [ i ]. Cette année-là, Derrick Henry Lehmer publia un algorithme de recherche binaire applicable à tous les tableaux. En 1962, Hermann Bottenbruch présenta une implémentation ALGOL 60 de la recherche binaire qui plaçait la comparaison d'égalité à la fin , augmentant ainsi le nombre moyen d'itérations d'une unité, mais réduisant à une seule unité le nombre de comparaisons par itération. La recherche binaire uniforme a été développée par AK Chandra de l'Université de Stanford en 1971. En 1986, Bernard Chazelle et Leonidas J. Guibas ont introduit la cascade fractionnaire comme méthode de résolution de nombreux problèmes de recherche en géométrie algorithmique .
Problèmes de mise en œuvre
Bien que l'idée de base de la recherche binaire soit relativement simple, les détails peuvent s'avérer étonnamment complexes.
Lorsque Jon Bentley a proposé la recherche binaire comme exercice dans un cours destiné aux programmeurs professionnels, il a constaté que 90 % d'entre eux ne parvenaient pas à trouver une solution correcte après plusieurs heures de travail, principalement parce que les implémentations incorrectes ne s'exécutaient pas ou renvoyaient une réponse erronée dans de rares cas particuliers . Une étude publiée en 1988 montre que le code correct n'est présent que dans cinq manuels sur vingt. De plus, l'implémentation de la recherche binaire proposée par Bentley lui-même, publiée dans son ouvrage *Programming Pearls* en 1986 , contenait une erreur de dépassement de capacité qui est restée indétectée pendant plus de vingt ans. L'implémentation de la recherche binaire dans la bibliothèque du langage Java a présenté le même bug de dépassement de capacité pendant plus de neuf ans.
En pratique, les variables représentant les indices sont souvent de taille fixe (entiers), ce qui peut entraîner un dépassement de capacité arithmétique pour les très grands tableaux. Si le point médian de l'intervalle est calculé comme , sa valeur peut excéder la plage des entiers du type de données utilisé pour le stocker, même si et sont compris dans cette plage. Si et sont non négatifs, ce problème peut être évité en calculant le point médian comme .
Une boucle infinie peut se produire si les conditions de sortie de la boucle ne sont pas correctement définies. Dès que la condition de sortie est dépassée , la recherche a échoué et cet échec doit être signalé. De plus, la boucle doit être interrompue lorsque l'élément cible est trouvé, ou, dans le cas d'une implémentation où cette vérification est effectuée à la fin, des vérifications de succès ou d'échec de la recherche doivent être présentes à la fin. Bentley a constaté que la plupart des programmeurs ayant implémenté incorrectement la recherche binaire commettaient une erreur dans la définition des conditions de sortie.
Le langage C fournit cette fonctionbsearch() dans sa bibliothèque standard , qui est généralement implémentée via une recherche binaire, bien que la norme officielle ne l'exige pas.
La bibliothèque standard de C++ fournit les fonctions binary_search(), lower_bound(), upper_bound()et equal_range(). En utilisant la bibliothèque C++20std::ranges , elle peut être appliquée sur une plage comme std::ranges::binary_search().
La bibliothèque standard Phobos de Dstd.range , dans le module, fournit un type SortedRange(renvoyé par sort()et assumeSorted()les fonctions) avec des méthodes contains(), equalRange(), lowerBound()et trisect(), qui utilisent par défaut des techniques de recherche binaire pour les plages offrant un accès aléatoire.
COBOL fournit le SEARCH ALLverbe permettant d'effectuer des recherches binaires sur des tables ordonnées COBOL.
Le package de bibliothèque standard de Gosort contient les fonctions Search`find`, SearchInts`find`, `find` SearchFloat64set ` SearchStringsfind`, qui implémentent la recherche binaire générale, ainsi que des implémentations spécifiques pour la recherche dans des tranches d'entiers, de nombres à virgule flottante et de chaînes de caractères, respectivement.
Java propose un ensemble de méthodes statiques surchargéesbinarySearch() dans les classes Le framework .NET 2.0 de Microsoft propose des versions génériques statiques de l'algorithme de recherche binaire dans ses classes de base de collections. Un exemple serait System.Arrayla méthode `get` de `get` BinarySearch<T>(T[] array, T value).
Pour Objective-C , le framework Cocoa fournit la méthode dans Mac OS X 10.6 et versions ultérieures. Le framework Core Foundation C d'Apple contient également une fonction. CFArrayBSearchValues()
Python fournit le bisectmodule qui maintient une liste triée sans avoir à trier la liste après chaque insertion.
La classe Array de Rubybsearch inclut une méthode avec correspondance approximative intégrée.
La primitive slice de Rustbinary_search() fournit , binary_search_by(), binary_search_by_key(), et partition_point().
 R
R  T
T